Anthropic engineer Thariq Shihipar switches to Claude-generated HTML
Thariq Shihipar, who works on Claude Code at Anthropic, switches from Markdown files to Claude-generated HTML for most tasks. He details the workflow in a post, highlighting improved performance via Claude’s code generation for AI-assisted coding. The approach uses LLM wikis with dynamic HTML artifacts to capture structured data for AI agents and enable interactive outputs in workflows like inbox zeroing and deep research. Developers testing HTML-based artifacts repost and discuss the shift.
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
http://x.com/i/article/2052796100608974848
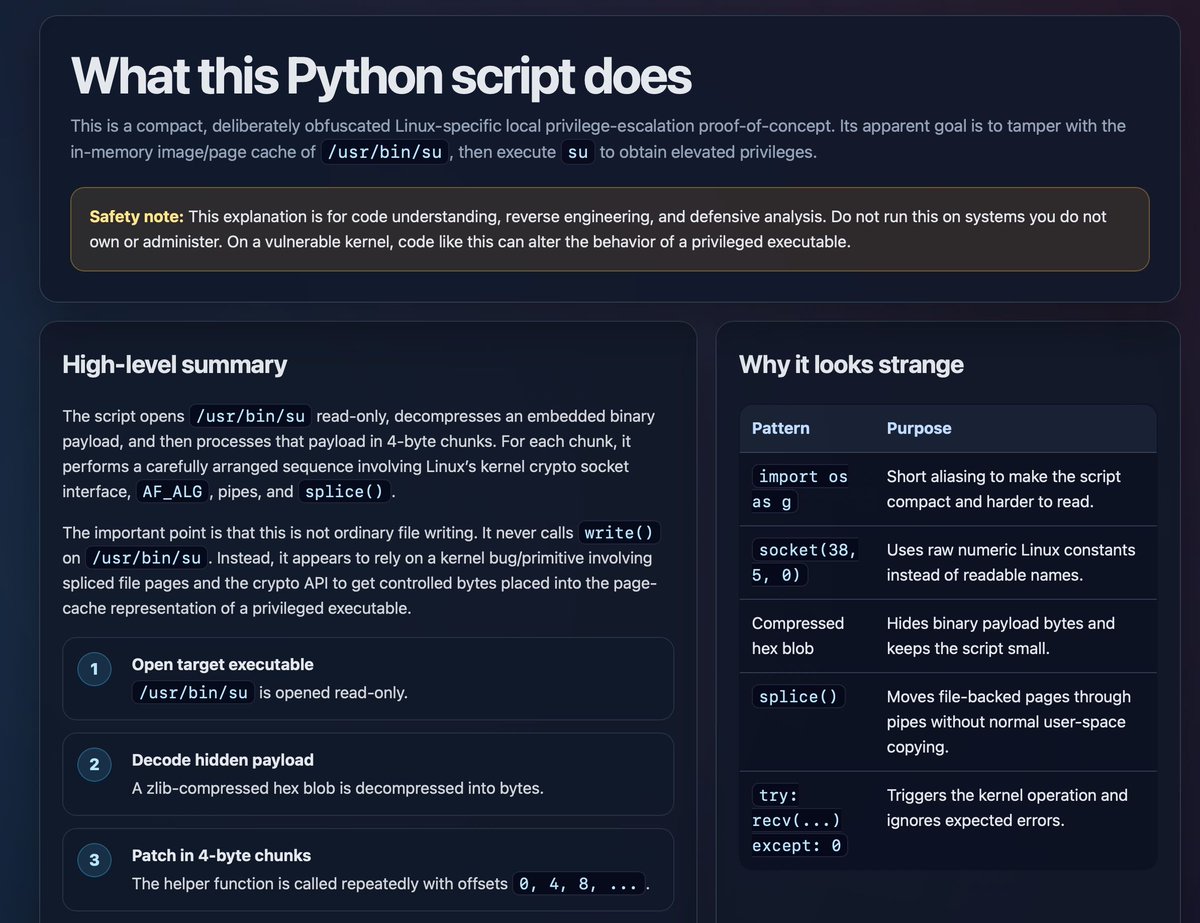
Asking for HTML explanations of things is pretty neat, I tried it just now with the obfuscated Python POC for the new http://copy.fail Linux vulnerability: https://simonwillison.net/2026/May/8/unreasonable-effectiveness-of-html/#trying-this-out
http://x.com/i/article/2052796100608974848
@karpathy 4 is svg animations @sarah_edo https://www.amazon.com/SVG-Animations-Implementations-Responsive-Animation/dp/1491939702
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
When I want to learn something new, or dig into a paper, I have Claude generate a HTML for me.
This works surprisingly well (especially in Claude, since Codex generated HTML is still kinda ugly...)
It's better than Google NotebookLM. Podcasts are nice, but reading is much higher-bandwidth than listening to a podcast.
HTML has a key advantage: they can show things. Diagrams. Charts. Interactive bits. You can actually poke at the idea, not just passively consume it.
Then I iterate. Ask questions. Refine sections. Add missing pieces. The HTML evolves with my understanding.
Over time, this compounds into a personal knowledge base.
"The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that." 💯
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
My favourite new stack: Agents + MCP + Markdown + HTML
“Files over apps” is a vibe!
LLM Wikis + HTML Artifacts are insanely powerful. You should seriously consider this in your workflows. LLM Wikis captures all the important information that lets you and your agents do meaningful work. HTML artifacts present that information in interesting ways that allow you to take important actions along with your agents. My HTML artifacts sit on top of my LLM wikis. They are dynamic and are easily extended as needs arise. I have hooked my Artifacts to talk to my agents, and similarly, the agents can talk to artifacts. This has allowed me to build powerful artifacts that reduce my inbox to zero, keep me updated on any topic of interest, fast prototyping, do deep research, design/trigger new experiments, generate figures to improve understanding, schedule research, search relevant information, discover topics, and so much more. What you see in the clip is not a website. It's a simple interactive HTML artifact. HTML artifacts are useful for designers, engineers, researchers, students, and anyone working with agents. Lastly, HTML doesn't replace Markdown. They are a much better combination working together.
More important takeaway: use both Markdown and HTML.
Your agents will thank you for it.
LLM Wikis + HTML Artifacts are insanely powerful. You should seriously consider this in your workflows. LLM Wikis captures all the important information that lets you and your agents do meaningful work. HTML artifacts present that information in interesting ways that allow you to take important actions along with your agents. My HTML artifacts sit on top of my LLM wikis. They are dynamic and are easily extended as needs arise. I have hooked my Artifacts to talk to my agents, and similarly, the agents can talk to artifacts. This has allowed me to build powerful artifacts that reduce my inbox to zero, keep me updated on any topic of interest, fast prototyping, do deep research, design/trigger new experiments, generate figures to improve understanding, schedule research, search relevant information, discover topics, and so much more. What you see in the clip is not a website. It's a simple interactive HTML artifact. HTML artifacts are useful for designers, engineers, researchers, students, and anyone working with agents. Lastly, HTML doesn't replace Markdown. They are a much better combination working together.
LLM Wikis + HTML Artifacts are insanely powerful.
You should seriously consider this in your workflows.
LLM Wikis captures all the important information that lets you and your agents do meaningful work.
HTML artifacts present that information in interesting ways that allow you to take important actions along with your agents.
My HTML artifacts sit on top of my LLM wikis. They are dynamic and are easily extended as needs arise.
I have hooked my Artifacts to talk to my agents, and similarly, the agents can talk to artifacts.
This has allowed me to build powerful artifacts that reduce my inbox to zero, keep me updated on any topic of interest, fast prototyping, do deep research, design/trigger new experiments, generate figures to improve understanding, schedule research, search relevant information, discover topics, and so much more.
What you see in the clip is not a website. It's a simple interactive HTML artifact.
HTML artifacts are useful for designers, engineers, researchers, students, and anyone working with agents.
Lastly, HTML doesn't replace Markdown. They are a much better combination working together.

Every day that passes. I am relying more and more on this simple stack: Agents + MCP + Markdown + HTML. I don't use my browser as much anymore, as the HTML artifacts take care of all of that for me. In a sense, these artifacts are hyperpersonalized, which I feel is how every website I visit should be. Forgot to mention that one of my favorite uses for HTML artifacts is actually monitoring stats, results, trends, etc.
LLM Wikis + HTML Artifacts are insanely powerful. You should seriously consider this in your workflows. LLM Wikis captures all the important information that lets you and your agents do meaningful work. HTML artifacts present that information in interesting ways that allow you to take important actions along with your agents. My HTML artifacts sit on top of my LLM wikis. They are dynamic and are easily extended as needs arise. I have hooked my Artifacts to talk to my agents, and similarly, the agents can talk to artifacts. This has allowed me to build powerful artifacts that reduce my inbox to zero, keep me updated on any topic of interest, fast prototyping, do deep research, design/trigger new experiments, generate figures to improve understanding, schedule research, search relevant information, discover topics, and so much more. What you see in the clip is not a website. It's a simple interactive HTML artifact. HTML artifacts are useful for designers, engineers, researchers, students, and anyone working with agents. Lastly, HTML doesn't replace Markdown. They are a much better combination working together.
For those interested, I will be doing a live session on this topic soon: https://academy.dair.ai/events/cmovobp97000904l5h0n9a2yz
Sign up if you are interested in some of the tools we are releasing soon to get you building with all these ideas.
Every day that passes. I am relying more and more on this simple stack: Agents + MCP + Markdown + HTML. I don't use my browser as much anymore, as the HTML artifacts take care of all of that for me. In a sense, these artifacts are hyperpersonalized, which I feel is how every website I visit should be. Forgot to mention that one of my favorite uses for HTML artifacts is actually monitoring stats, results, trends, etc.
My point exactly:
I prefer to combine both HTML and MD.
I have been sharing a few examples of LLM Artifacts like this one:
HTML is the new markdown. I've stopped writing markdown files for almost everything and switched to using Claude Code to generate HTML for me. This is why.
Another example
Hacker News → LLM Artifact I built the most personalized HN feed. It only tracks topics I do research around based on memory and LLM wiki. No point in storing bookmarks. With a few automations, rules, skills, and proactive agents, you can make the feed whatever you want.
HTML is the new markdown.
I've stopped writing markdown files for almost everything and switched to using Claude Code to generate HTML for me. This is why.
http://x.com/i/article/2052796100608974848
Now also on the Claude Blog: https://claude.com/blog/using-claude-code-the-unreasonable-effectiveness-of-html
http://x.com/i/article/2052796100608974848
when building products most ppl mess up how to think about modalities.. esp true with something like voice.
voice should be an input/output affordance the system picks based on your context, i don’t think it’s its own product category for a ton of use cases.
e.g. driving? voice in, voice out. cooking? voice in, glanceable visual out. at desk? text both ways. ambient/peripheral? home screen / no convo at all. the modality should be a function of (user state, info density, urgency, hands/eyes availability) & not a fixed shell. the configuration you use is absolutely critical. our system is designed such that ai can pick the right modalities by almost always presenting visual elements for you by deeply understanding your context.
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.