Self-Generated Replay Data From LLMs Reduces Catastrophic Forgetting
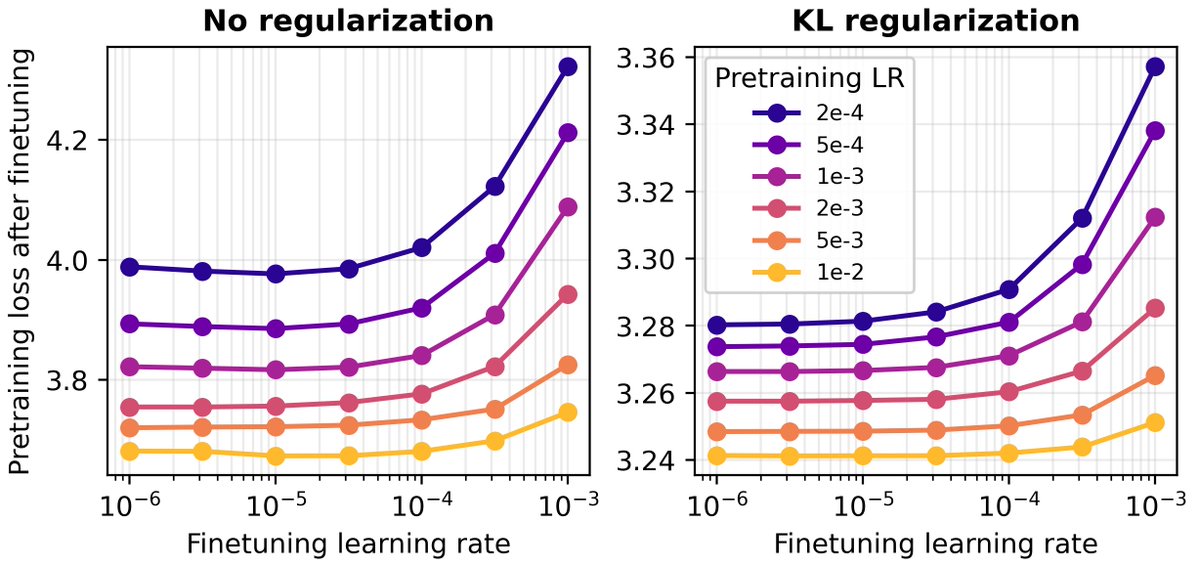
Learning rate matters too. Forgetting can be reduced by using a high pretraining learning rate, making it possible to release pretrained models that are less prone to downstream forgetting. A small finetuning learning rate also mitigates forgetting. 6/8
When does forgetting still happen? When the model has no spare capacity. Small models trained to saturation cannot absorb new information without overwriting old information. 5/8
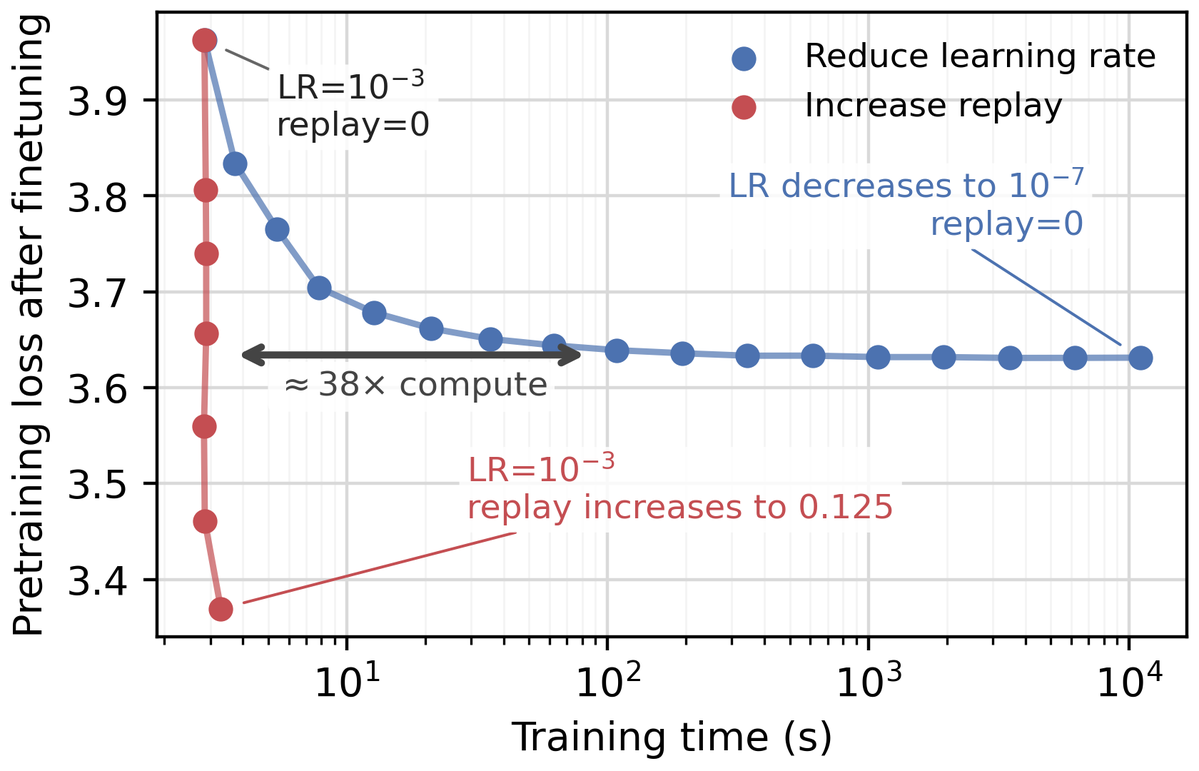
However, a small finetuning learning rate is expensive, increasing the optimizer steps required to reach a target loss. Using replay data in finetuning breaks this tradeoff, enabling the use of a high learning rate while minimizing forgetting! 7/8
Learning rate matters too. Forgetting can be reduced by using a high pretraining learning rate, making it possible to release pretrained models that are less prone to downstream forgetting. A small finetuning learning rate also mitigates forgetting. 6/8
Much more in the paper! As models are increasingly being adapted to new settings, it’s especially crucial to understand forgetting. This was an incredible effort with an amazing team led by @mrtnm. Code is available at: https://github.com/martin-marek/forgetting. 8/8
However, a small finetuning learning rate is expensive, increasing the optimizer steps required to reach a target loss. Using replay data in finetuning breaks this tradeoff, enabling the use of a high learning rate while minimizing forgetting! 7/8