So, to add a belated 2nd update, in what ways is this similar/different to the Thinking Machines interaction models?
First, where we both agree is that interactions with models should be more fluent, with users and models interrupting each other, talking in parallel and all-in-all behaving much more like humans in conversation than humans using instant messengers.
The first interesting difference after that is the focus. While thinky is building interactions models that work between all modalities, we were very focused on purely LLM applications (and LLM-based agents), with audio/video being only a faint reference in our motivation section. Our main interest is in parallelizing the work that LLM-based agents are doing and to change how they are interacting with the environment.
A technical difference (although we may have to ping the thinking machines team to fully confirm this), is that the interactions models appear to be built with a single stream format in the backend (using 'micro-turns'). In comparison, our model really is parallel, and each forward pass consumes input tokens from all input streams and produces a token in each output stream (which we argue is a much better way to leverage the GPUs).
Then, a practical difference is that our work is much more conceptual, the models are tiny and only instruction-tuned -- matching our academic environment. For this reason I was actually very excited seeing the thinking machines implementation of their large-scale interaction model. For many months, our tongue-in-cheek draft for the conclusions only read (image attached), "someone should really spend money to test something like this at scale".
-- Finally, while both their report and ours are interested in continuous interactions there is a small, but noticeable, difference in direction. The interaction models are designed first to improve human-AI communication and, well, interaction.
This is very cool, but a direction we want to add is that a parallel stream format could also be a nice framework for the AI itself, to build a continuously running, intelligent system. We think that this would make the model more reliably and safe than current approaches to duct-tape message-based LLMs into the rough shape of a 'continuously acting agent'.
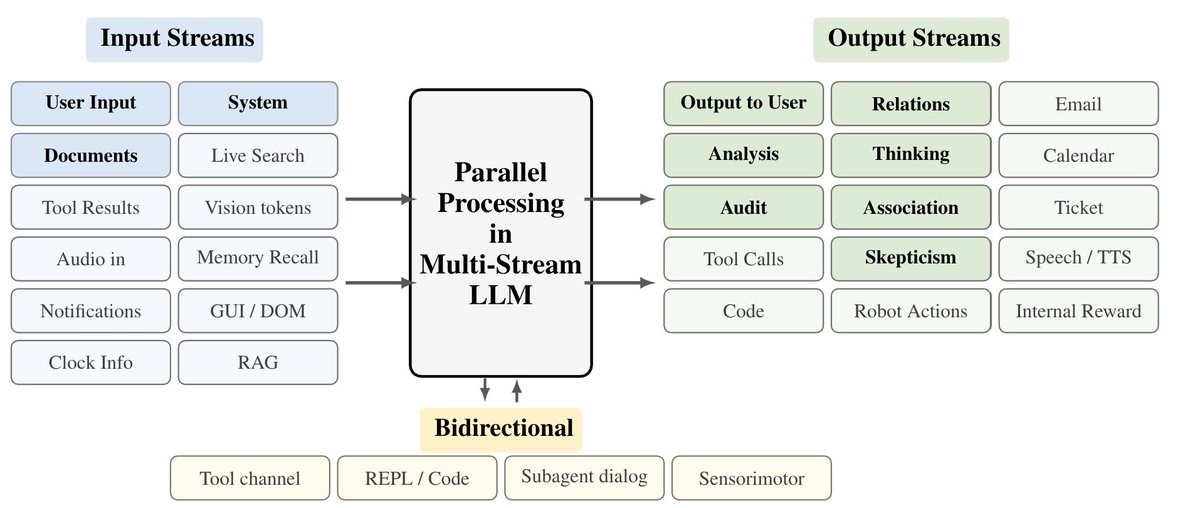

We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn. This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information. In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can … 🔵Be created by instruction-tuning for the stream format 🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in) 🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency 🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security 🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized. Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.