ECHO augments GRPO by adding an auxiliary environment-token prediction loss, enabling agents to learn action-conditioned dynamics from unsuccessful trajectories in sparse-reward settings
It cuts environment-token cross-entropy loss to 0.07-0.09 nats on Qwen3 models.
Really clean approach.
Do cross entropy loss on the environment feedback. This allows the model to get supervision even on failed rollouts and helps form a sort of pseudo world model!

http://x.com/i/article/2056344151235387392
Performance nearly doubles without any additional computation!
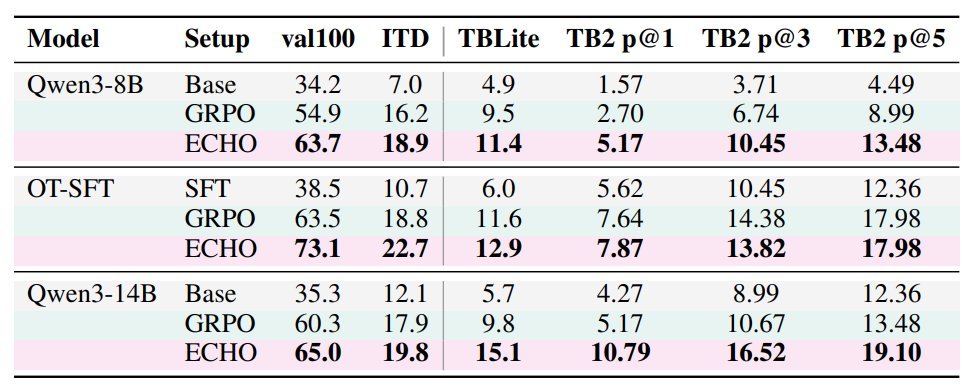
Really clean approach. Do cross entropy loss on the environment feedback. This allows the model to get supervision even on failed rollouts and helps form a sort of pseudo world model!
Interestingly, albeit unsurprisingly, normal GRPO does not change the representation of the environment-related tokens which is kinda to be expected given they are usually masked out. ECHO naturally does model the environment better.
(world modelling)

Performance nearly doubles without any additional computation!
Training without the GRPO term and only getting the model to learn to predict environmental responses works too!
(world modelling!)

Interestingly, albeit unsurprisingly, normal GRPO does not change the representation of the environment-related tokens which is kinda to be expected given they are usually masked out. ECHO naturally does model the environment better. (world modelling)