nanogpt contest is based on fineweb-10B. and shard 001 document 106548 contains a giant anomaly that caused the one consistent spikes in all my test runs: one 60k tokens document with the 20% of token n°11976— simply broken english gpt-2 tokenization
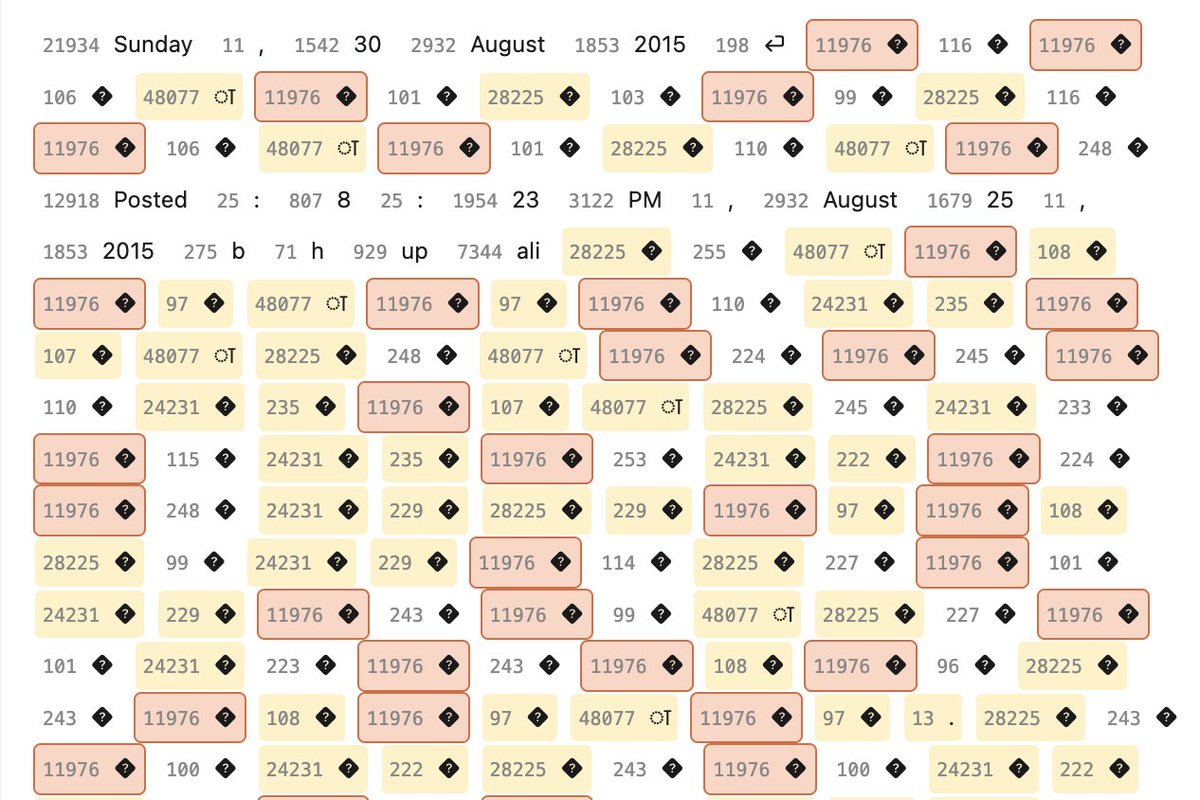
ok i'm starting to suspect many nanogpt speedrun spikes/anomalies (and maybe even minute optimization) can be tracked to this one marathi blog that somehow evade the English filter.
typical run with batch standing out.
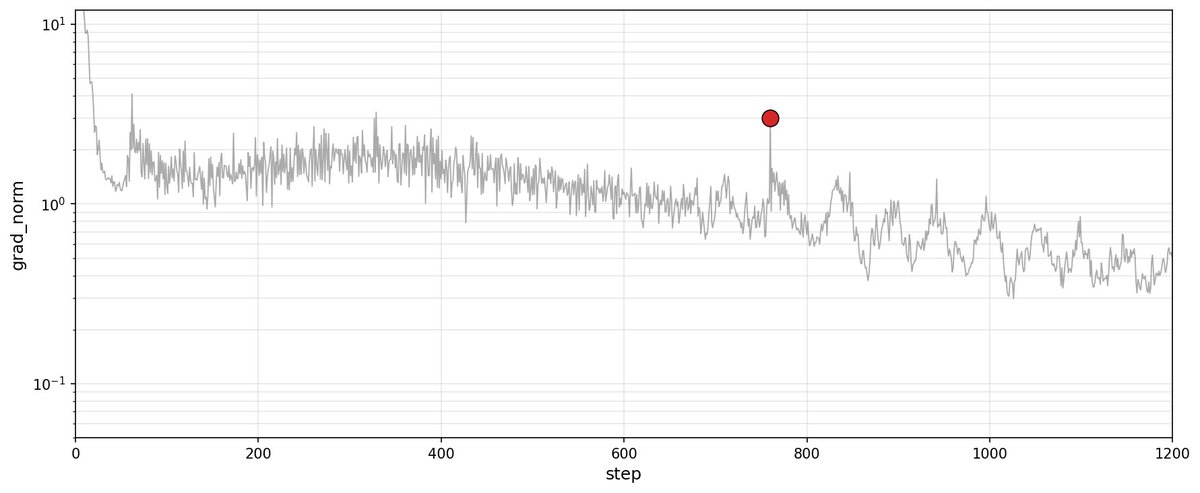
nanogpt contest is based on fineweb-10B. and shard 001 document 106548 contains a giant anomaly that caused the one consistent spikes in all my test runs: one 60k tokens document with the 20% of token n°11976— simply broken english gpt-2 tokenization
so important clarification : should not affect the official track (but definitely informal research).