Teortaxes generates clean synthetic solution traces for Putnam-level problems using Mythos and pretrains a 7B model, achieving gradual loss reduction but strictly worse final performance due to limited model depth.
Replies suggest scale-aware pipelines as a potential mitigation.
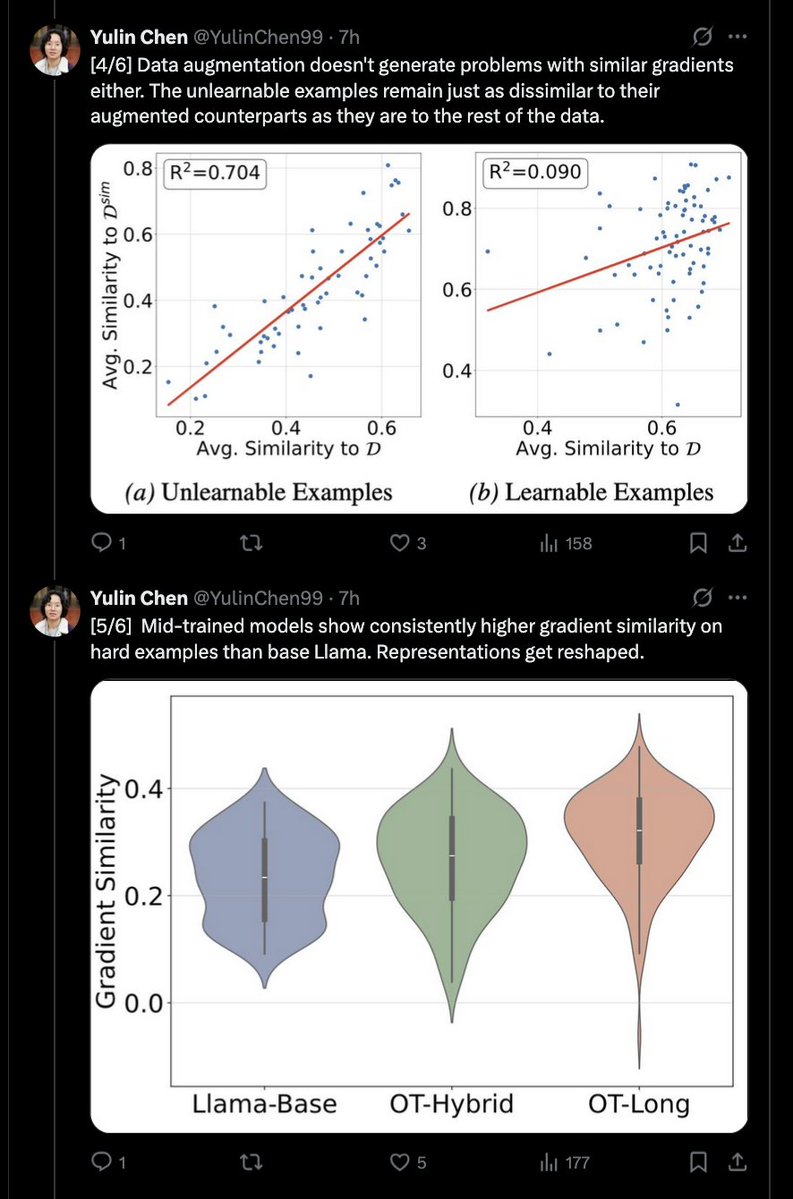
Extremely relevant work from @YulinChen99! But do mid-trained models actually become capable of learning these unlearnable problems via RLVR just because they're more gradient-compatible?

One thing I sometimes think about: when does synthetic data get TOO GOOD? Consider: we use some Mythos [10T 200AB] to generate clean, CONCISE solution traces for Putnam-level problems, and *pre*train a 7B model on that (along with general knowledge). BUT its depth/residual stream width/whatever are insufficient for inferring the structure of such data, the implied representations are irreducibly complex. Of course we still see the loss gradually falling, but it ends up performing strictly worse OOD than a model trained on a modestly enriched web crawl. Whereas Haiku-5.5 [500B 12AB], trained on the same synthetic dataset, indeed recovers much of the original's performance a year later. So: how do we derive the scaling law for the inherent data complexity mix? To an extent this is already obvious, we see that in the same family, MoEs are much more verbose (Qwen 35B vs 27B, Gemma 26B vs 31B), because reaching the same-ish quality of final answers is only possible with more, lower-complexity operations, or in the bad case just brute forcing the problem by mumbling for 100K tokens until you get ≈an implicit consensus vote, and this emerges from RL. V4-Flash is also more verbose than V4-Pro, and, tellingly, than V3.2-Speciale if pushed to the same final answer accuracy in a hard OOD task. But that's about RL. The issue of SFTing on outputs of much stronger models is also obvious enough. I am mainly interested in pretraining. Clearly the data can be refined a lot yet, but likely not in the direction of naive "higher quality". I suspect this is part of what holds back non-frontier labs. How do we even approach this? @Dorialexander @willccbb
There's almost nothing public about it but a key thing is scale-aware synthetic pipelines. Large models can compress complexity while small ones need to rely way more on decomposition/iterative simplification. All doable with proper environment design, so long as generator model always has more info than final trained model.
One thing I sometimes think about: when does synthetic data get TOO GOOD? Consider: we use some Mythos [10T 200AB] to generate clean, CONCISE solution traces for Putnam-level problems, and *pre*train a 7B model on that (along with general knowledge). BUT its depth/residual stream width/whatever are insufficient for inferring the structure of such data, the implied representations are irreducibly complex. Of course we still see the loss gradually falling, but it ends up performing strictly worse OOD than a model trained on a modestly enriched web crawl. Whereas Haiku-5.5 [500B 12AB], trained on the same synthetic dataset, indeed recovers much of the original's performance a year later. So: how do we derive the scaling law for the inherent data complexity mix? To an extent this is already obvious, we see that in the same family, MoEs are much more verbose (Qwen 35B vs 27B, Gemma 26B vs 31B), because reaching the same-ish quality of final answers is only possible with more, lower-complexity operations, or in the bad case just brute forcing the problem by mumbling for 100K tokens until you get ≈an implicit consensus vote, and this emerges from RL. V4-Flash is also more verbose than V4-Pro, and, tellingly, than V3.2-Speciale if pushed to the same final answer accuracy in a hard OOD task. But that's about RL. The issue of SFTing on outputs of much stronger models is also obvious enough. I am mainly interested in pretraining. Clearly the data can be refined a lot yet, but likely not in the direction of naive "higher quality". I suspect this is part of what holds back non-frontier labs. How do we even approach this? @Dorialexander @willccbb