Researchers Train Over 2000 MoE Models to Optimize Expert Size and Count
Why? MoEs add interacting design axes. Most prior work only studies 1–2 at a time because of combinatorial explosion. We sweep grids.
How? We train MoE LMs from 10M to 300M active params, up to 6.6B total params. Comparisons are FLOP-matched via active FFN/expert params. [2/9]
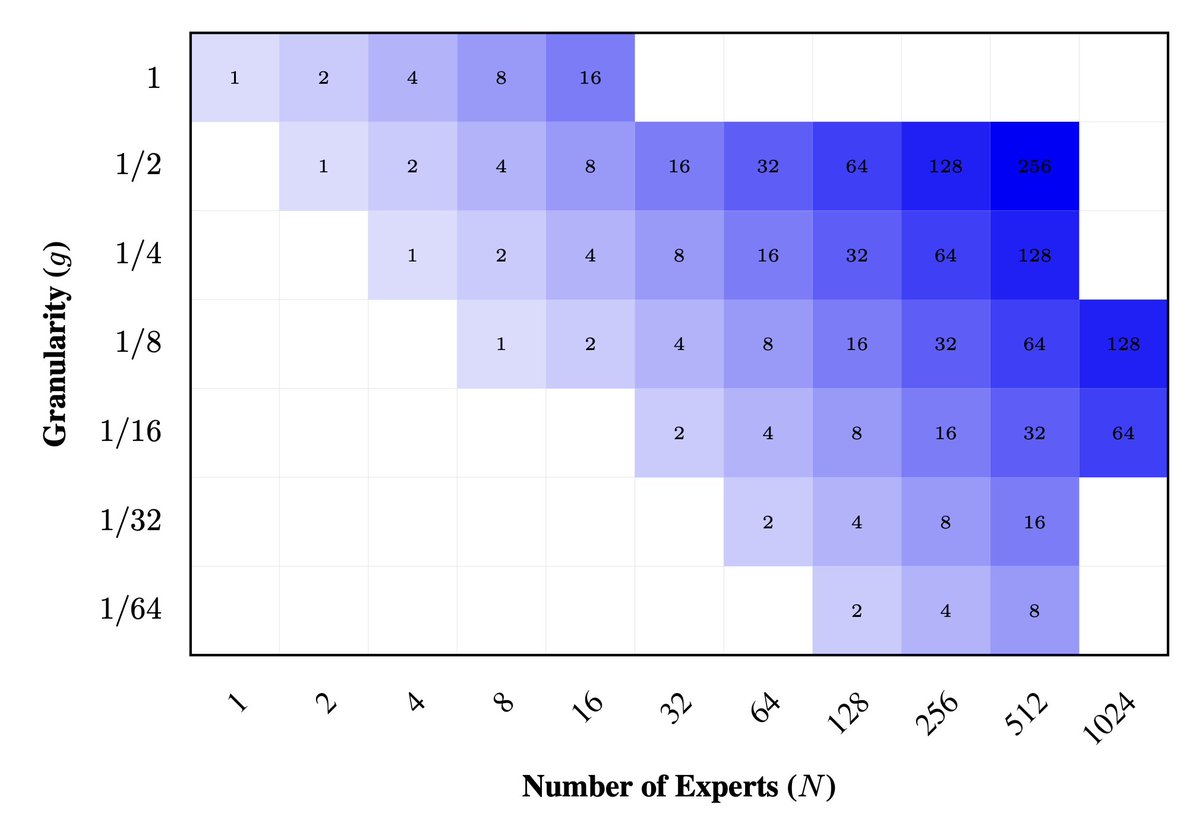
MoEs are everywhere, but the design space is confusing: total vs active experts? expert size? shared experts? routing? token dropping? We train >2000 MoE LMs 🫠 to investigate and bring you: 📄🔪🍰 Slicing and Dicing MoEs Tl;dr: it's all about expert size and count [1/9]
🤔 Do total (inactive) experts help ❓ Yes 📈 At fixed compute, increasing total MoE params - via either bigger or more experts - consistently improves LM loss. Even when total expert params are 128× active expert params. ➡️ Add as many total expert parameters as possible. [3/9]

Why? MoEs add interacting design axes. Most prior work only studies 1–2 at a time because of combinatorial explosion. We sweep grids. How? We train MoE LMs from 10M to 300M active params, up to 6.6B total params. Comparisons are FLOP-matched via active FFN/expert params. [2/9]
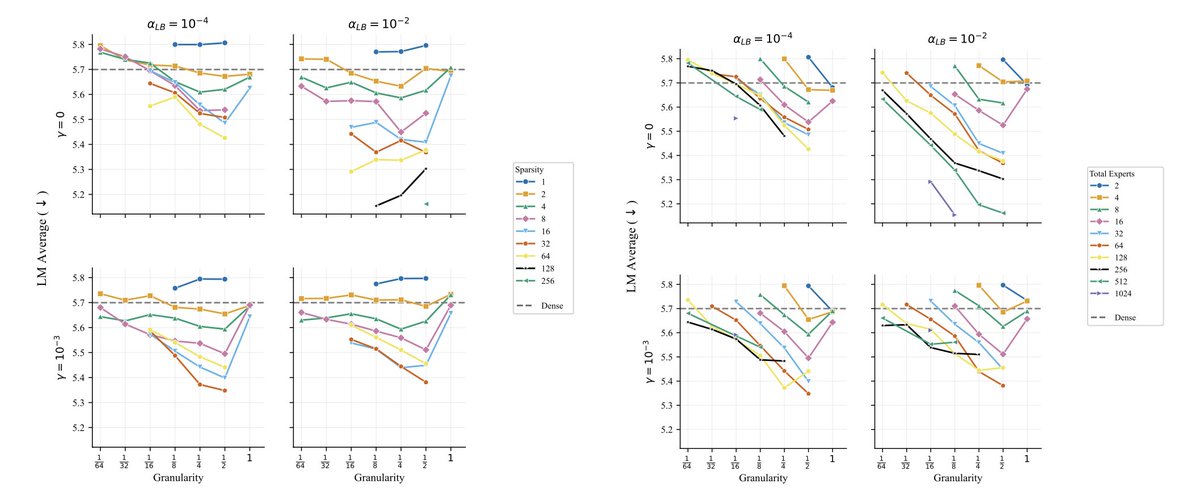
🤔 Experts: finer-grained? coarser? fewer? more❓ More experts. Optimal granularity changes slowly with total params (or sparsity), but shifts more with active params. ➡️ Choose expert size primarily by active params, then spend memory on expert count. [4/9]
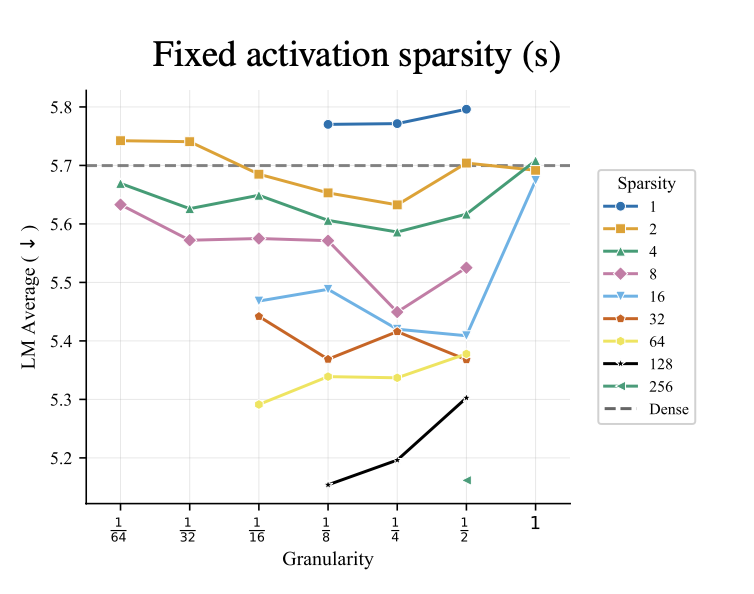
🤔 Do total (inactive) experts help ❓ Yes 📈 At fixed compute, increasing total MoE params - via either bigger or more experts - consistently improves LM loss. Even when total expert params are 128× active expert params. ➡️ Add as many total expert parameters as possible. [3/9]
🤔 Is finer granularity beneficial without sparse activation❓ Nope. We split a dense FFN into smaller always-active "experts", and performance degrades. ➡️ MoE gain is not just from smaller FFN blocks; it comes from sparse activation through inactive params. [5/9]

🤔 Experts: finer-grained? coarser? fewer? more❓ More experts. Optimal granularity changes slowly with total params (or sparsity), but shifts more with active params. ➡️ Choose expert size primarily by active params, then spend memory on expert count. [4/9]
🤔 Do more flexible expert configurations help? Generalists or heterogeneity❓ No. MoEs with heterogeneously sized experts interpolate between homogeneous MoEs. Shared generalist experts match or underperform no-generalist baselines. ➡️ Use homogeneous, non-shared experts. [6/9]


🤔 Is finer granularity beneficial without sparse activation❓ Nope. We split a dense FFN into smaller always-active "experts", and performance degrades. ➡️ MoE gain is not just from smaller FFN blocks; it comes from sparse activation through inactive params. [5/9]
🤔 What about routing ❓ Dropless routing yields a small but consistent gain. Extremely high or low load balancing (loss or loss-free) hurts performance, but many settings are near-optimal. ➡️ Just pick a sane setting that avoids token dropping. [7/9]

🤔 Do more flexible expert configurations help? Generalists or heterogeneity❓ No. MoEs with heterogeneously sized experts interpolate between homogeneous MoEs. Shared generalist experts match or underperform no-generalist baselines. ➡️ Use homogeneous, non-shared experts. [6/9]
Big thanks to my fantastic collaborators: @snehaark @DanielleRotherm @LukeZettlemoyer [9/9]
To summarize in one recipe 🥡 : 1️⃣ Find max FLOP/memory budget, set active/total expert parameters 2️⃣ Find optimal expert size from active parameters 3️⃣ Sanity checks of load balancing, minimize token dropping Easy as (slicing) 🥧. Code/data soon: http://github.com/hadasah/slicing_and_dicing [8/9]