Gated DeltaNet-2 separates channel-wise erase and write gates within linear attention, raising S-NIAH-3 scores from 63 to 90 on 1.3B models trained on 100B tokens
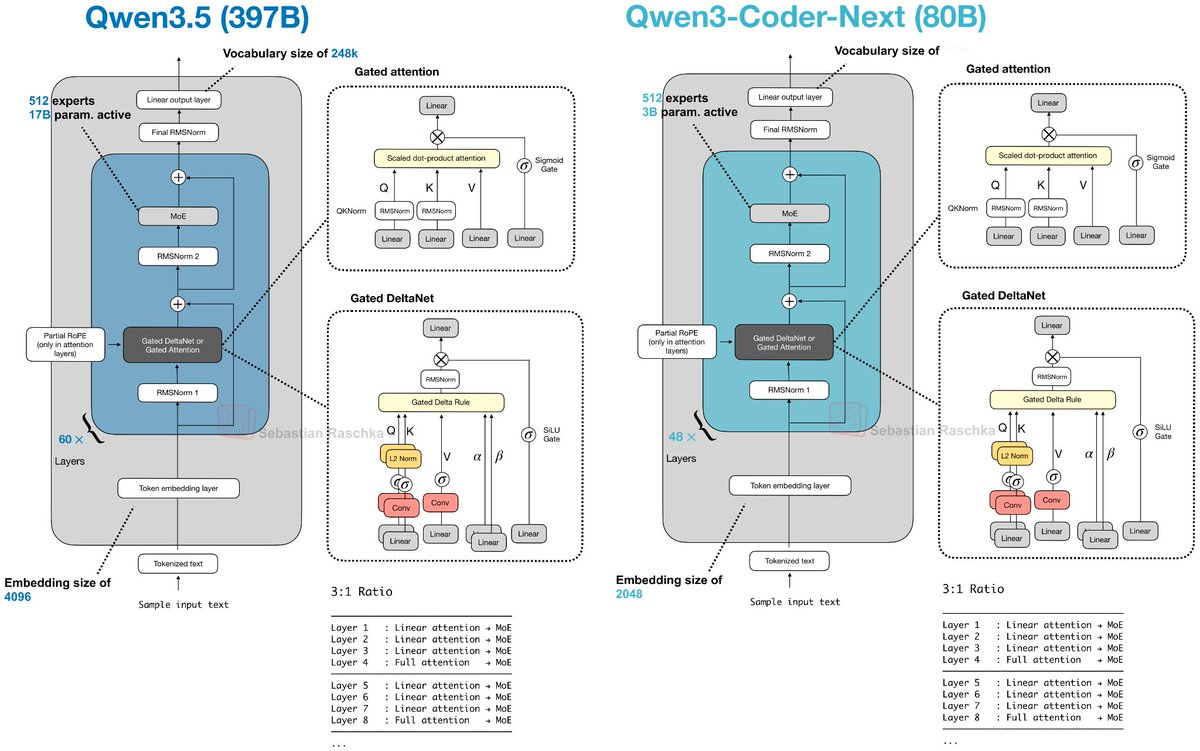
The mechanism appears in Qwen3-Next and Qwen3.5 397B models.
Gated DeltaNet has been one of my favorite "hybrid attention" newcomers in the good old transformer stack. Excited to see Gated DeltaNet-2. Adding it to my reading stack. In the meantime, I have a primer on Gated DeltaNet here: https://magazine.sebastianraschka.com/i/177848019/26-gated-deltanet
Gated DeltaNet-2 is here. 🚀 🔥 New paper: Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention Gated DeltaNet-2 outperforms KDA and Mamba-3, the latest and best recurrent architectures, head to head at 1.3B. 🏆 💡 Here's the idea behind it: Linear attention squeezes an unbounded KV cache into a fixed-size recurrent state. The hard part isn't just what to forget, it's how to edit that memory without scrambling the associations already in it. Prior delta-rule models like Gated DeltaNet and KDA use one scalar gate to do two jobs at once: erasing old content and writing new content. But these two decisions act on different axes of the state, so tying them together is a real limitation. Gated DeltaNet-2 decouples them. ✂️ a channel-wise erase gate b_t picks which key-side coordinates to read and remove ✍️ a channel-wise write gate w_t picks which value-side coordinates to commit 🔁 recovers KDA when both gates collapse to a scalar, and Gated DeltaNet when the decay collapses too ⚡ still trains fast: chunkwise WY algorithm with gate-aware backward, fused in Triton 📊 Results: We train 1.3B models on 100B tokens of FineWeb-Edu, matched in recurrent state size, against Mamba-2, Gated DeltaNet, KDA, and Mamba-3. Best average on language modeling + commonsense reasoning, in both recurrent and hybrid settings Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38 Joint work with @YejinChoinka and @jankautz. 📄 Paper: https://shorturl.at/AAlVb 💻 Code: https://github.com/NVlabs/GatedDeltaNet-2 #LinearAttention #StateSpaceModels #Mamba #LLM
PS: it can be found in recent Qwen models since Qwen3-Next
Gated DeltaNet has been one of my favorite "hybrid attention" newcomers in the good old transformer stack. Excited to see Gated DeltaNet-2. Adding it to my reading stack. In the meantime, I have a primer on Gated DeltaNet here: https://magazine.sebastianraschka.com/i/177848019/26-gated-deltanet
> Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38 Expected from this change. Maybe hybrids with GDN-2 layers are highly promising.
Gated DeltaNet-2 is here. 🚀 🔥 New paper: Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention Gated DeltaNet-2 outperforms KDA and Mamba-3, the latest and best recurrent architectures, head to head at 1.3B. 🏆 💡 Here's the idea behind it: Linear attention squeezes an unbounded KV cache into a fixed-size recurrent state. The hard part isn't just what to forget, it's how to edit that memory without scrambling the associations already in it. Prior delta-rule models like Gated DeltaNet and KDA use one scalar gate to do two jobs at once: erasing old content and writing new content. But these two decisions act on different axes of the state, so tying them together is a real limitation. Gated DeltaNet-2 decouples them. ✂️ a channel-wise erase gate b_t picks which key-side coordinates to read and remove ✍️ a channel-wise write gate w_t picks which value-side coordinates to commit 🔁 recovers KDA when both gates collapse to a scalar, and Gated DeltaNet when the decay collapses too ⚡ still trains fast: chunkwise WY algorithm with gate-aware backward, fused in Triton 📊 Results: We train 1.3B models on 100B tokens of FineWeb-Edu, matched in recurrent state size, against Mamba-2, Gated DeltaNet, KDA, and Mamba-3. Best average on language modeling + commonsense reasoning, in both recurrent and hybrid settings Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38 Joint work with @YejinChoinka and @jankautz. 📄 Paper: https://shorturl.at/AAlVb 💻 Code: https://github.com/NVlabs/GatedDeltaNet-2 #LinearAttention #StateSpaceModels #Mamba #LLM
gated deltanet 2 compared to previous linear attention methods (kimi delta attention, gated deltanet, mamba2)
each new variant adds finer control over what to decay, erase, and write in the state matrix

Gated DeltaNet-2 is here. 🚀 🔥 New paper: Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention Gated DeltaNet-2 outperforms KDA and Mamba-3, the latest and best recurrent architectures, head to head at 1.3B. 🏆 💡 Here's the idea behind it: Linear attention squeezes an unbounded KV cache into a fixed-size recurrent state. The hard part isn't just what to forget, it's how to edit that memory without scrambling the associations already in it. Prior delta-rule models like Gated DeltaNet and KDA use one scalar gate to do two jobs at once: erasing old content and writing new content. But these two decisions act on different axes of the state, so tying them together is a real limitation. Gated DeltaNet-2 decouples them. ✂️ a channel-wise erase gate b_t picks which key-side coordinates to read and remove ✍️ a channel-wise write gate w_t picks which value-side coordinates to commit 🔁 recovers KDA when both gates collapse to a scalar, and Gated DeltaNet when the decay collapses too ⚡ still trains fast: chunkwise WY algorithm with gate-aware backward, fused in Triton 📊 Results: We train 1.3B models on 100B tokens of FineWeb-Edu, matched in recurrent state size, against Mamba-2, Gated DeltaNet, KDA, and Mamba-3. Best average on language modeling + commonsense reasoning, in both recurrent and hybrid settings Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38 Joint work with @YejinChoinka and @jankautz. 📄 Paper: https://shorturl.at/AAlVb 💻 Code: https://github.com/NVlabs/GatedDeltaNet-2 #LinearAttention #StateSpaceModels #Mamba #LLM
updated viz with RWKV-7 and longcat flash linear attention

gated deltanet 2 compared to previous linear attention methods (kimi delta attention, gated deltanet, mamba2) each new variant adds finer control over what to decay, erase, and write in the state matrix
thanks @norxornor and @Grad62304977
updated viz with RWKV-7 and longcat flash linear attention