SenseTime Open-Sources SenseNova-U1 Native Multimodal Model With MoE Backbone
Chinese AI lab SenseTime just open-sourced SenseNova U1, a unified multimodal model that can understand, reason, and generate images + text inside 1 model.
The interesting part is the architecture: it removes the usual visual encoder and variational auto-encoder setup, then handles image and language inside a shared representation space, instead of being passed between separate modules.
That means less handoff between modules, less information loss, and better consistency when creating dense visual content like infographics, guides, posters, comics, and image-text workflows.
That’s how the model can generate coherent text and images together in one flow, which is why it is strong for infographics, guides, comics, posters, and step-by-step visual content.
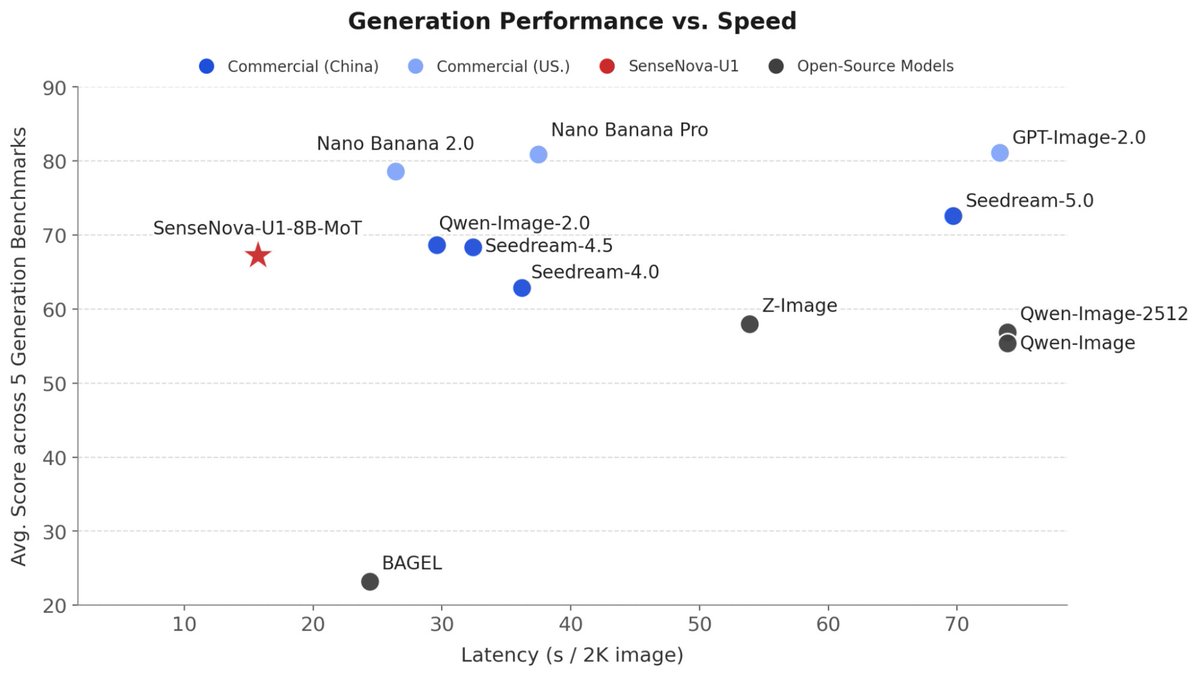
For infographic generation specifically, it is also around 2x faster than Qwen-Image-2.0 / Seedream-4.5 while staying in the same rough quality band, based on the client benchmark chart. 1/n




2/n Most multimodal systems still feel stitched together. - 1 part reads the image. - 1 part turns that into tokens. - 1 part reasons over language. - 1 part sends instructions to an image generator.
Every handoff can lose detail.
SenseNova U1 is trying a cleaner route: keep vision and language closer from the start, so the model can reason across both without constantly translating between separate systems.




Chinese AI lab SenseTime just open-sourced SenseNova U1, a unified multimodal model that can understand, reason, and generate images + text inside 1 model. The interesting part is the architecture: it removes the usual visual encoder and variational auto-encoder setup, then handles image and language inside a shared representation space, instead of being passed between separate modules. That means less handoff between modules, less information loss, and better consistency when creating dense visual content like infographics, guides, posters, comics, and image-text workflows. That’s how the model can generate coherent text and images together in one flow, which is why it is strong for infographics, guides, comics, posters, and step-by-step visual content. For infographic generation specifically, it is also around 2x faster than Qwen-Image-2.0 / Seedream-4.5 while staying in the same rough quality band, based on the client benchmark chart. 1/n
3/n The release includes the SenseNova U1 Lite series:
- SenseNova U1-8B-MoT, built on a dense backbone. - SenseNova U1-A3B-MoT, built on a mixture-of-experts backbone.
The impressive part is the size-performance tradeoff. U1 Lite reaches leading results among open-source models of similar scale, and even gets close to commercial image models on generation quality while being faster in inference.
2/n Most multimodal systems still feel stitched together. - 1 part reads the image. - 1 part turns that into tokens. - 1 part reasons over language. - 1 part sends instructions to an image generator. Every handoff can lose detail. SenseNova U1 is trying a cleaner route: keep vision and language closer from the start, so the model can reason across both without constantly translating between separate systems.
4/n The most useful part is the dense information rendering.
Infographics are hard for image models because they require layout control, readable text, visual structure, and semantic consistency at the same time.
SenseNova U1 is built for exactly this kind of output: knowledge posters, presentation-style visuals, comics, structured guides, and long image-text content where the text and images need to agree with each other.

3/n The release includes the SenseNova U1 Lite series: - SenseNova U1-8B-MoT, built on a dense backbone. - SenseNova U1-A3B-MoT, built on a mixture-of-experts backbone. The impressive part is the size-performance tradeoff. U1 Lite reaches leading results among open-source models of similar scale, and even gets close to commercial image models on generation quality while being faster in inference.
5/n. Another big piece is interleaved image-text generation.
That means the model can produce a full flow where text and visuals appear together, step by step, instead of generating a single image and stopping there.
All these examples demonstrate how the model can generate a complete multimodal sequence, pairing text and visuals across cooking guidance, iterative sketch refinement, comic-style drawing, and multi-view scene generation.
This is useful for tutorials, product guides, visual storytelling, education content, and agent workflows.




4/n The most useful part is the dense information rendering. Infographics are hard for image models because they require layout control, readable text, visual structure, and semantic consistency at the same time. SenseNova U1 is built for exactly this kind of output: knowledge posters, presentation-style visuals, comics, structured guides, and long image-text content where the text and images need to agree with each other.
6/n SenseNova U1-8B-MoT is around 2x faster than Qwen-Image-2.0 / Seedream-4.5 while staying in the same rough quality band
Much faster generation, while staying close to Qwen-Image-2.0 and Seedream-4.5 on quality.
5/n. Another big piece is interleaved image-text generation. That means the model can produce a full flow where text and visuals appear together, step by step, instead of generating a single image and stopping there. All these examples demonstrate how the model can generate a complete multimodal sequence, pairing text and visuals across cooking guidance, iterative sketch refinement, comic-style drawing, and multi-view scene generation. This is useful for tutorials, product guides, visual storytelling, education content, and agent workflows.
The full Technical Report is now out, their most detailed model disclosure yet.
Paper - http://arxiv.org/abs/2605.12500
Also: SenseNova-U1-A3B-MoT weights(38B-A3B MoE) are open-sourced.
Open-sourced an 8-step distilled LoRA: 100 NFE → 8 NFE, cutting H100 inference from 23s to 2s. ComfyUI is now supported, with ready-to-run workflows for t2i, image editing, and interleaved generation.
Also worth checking the SenseNova-Skills examples if you want prompt guides for infographic generation.
Built by @SenseTime_AI #AI #OpenSourceAI #MultimodalAI
Discord: https://discord.gg/BuTXPHmQub
Check it out here:
- GitHub: https://github.com/OpenSenseNova/SenseNova-U1
- Hugging Face: https://huggingface.co/collections/sensenova/sensenova-u1
6/n SenseNova U1-8B-MoT is around 2x faster than Qwen-Image-2.0 / Seedream-4.5 while staying in the same rough quality band Much faster generation, while staying close to Qwen-Image-2.0 and Seedream-4.5 on quality.