HiDream Open-Sources 8B Pixel-Level Unified Transformer Image Model
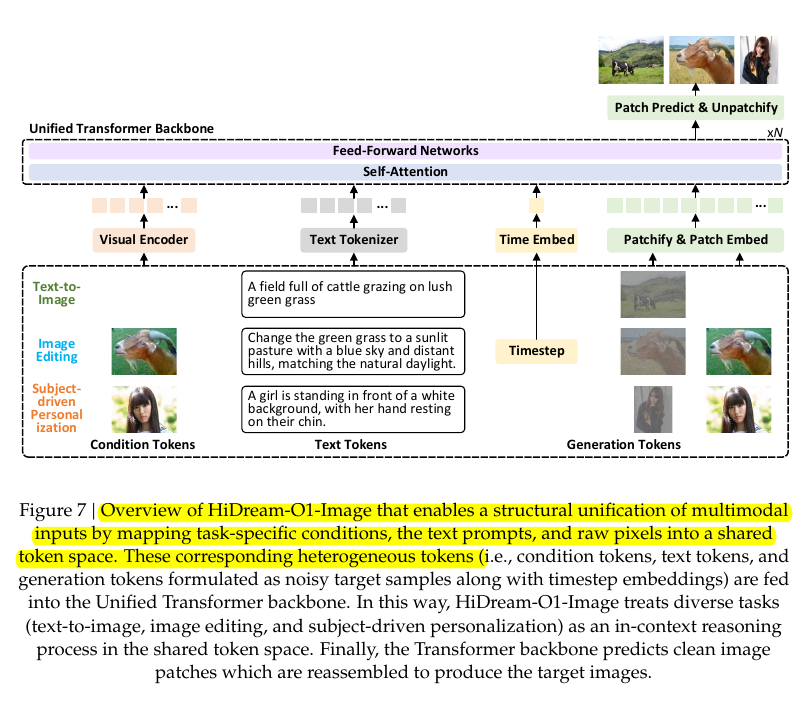
🧵 2. This diagram explains why HiDream is not just another image generator with a bigger parameter count.
HiDream maps text, reference images, task instructions, and raw image patches into one shared token space before generation starts.
The model then sends those mixed tokens through one Unified Transformer Backbone, where self-attention lets every part of the request look at every other part.
For text-to-image, the condition can be only a prompt, such as cattle grazing in a field.
For image editing, the condition includes an input image plus an instruction, such as changing grass, sky, and lighting while keeping the same animal.
For subject-driven personalization, the condition includes a reference subject, such as a person, so the model can preserve identity while creating a new scene.
The right side explains the generation process: the model predicts clean image patches from noisy image patches, then stitches those patches back into a final image.
The important technical shift is that HiDream treats generation, editing, and personalization as the same kind of token prediction problem, instead of building a different pipeline for each task.
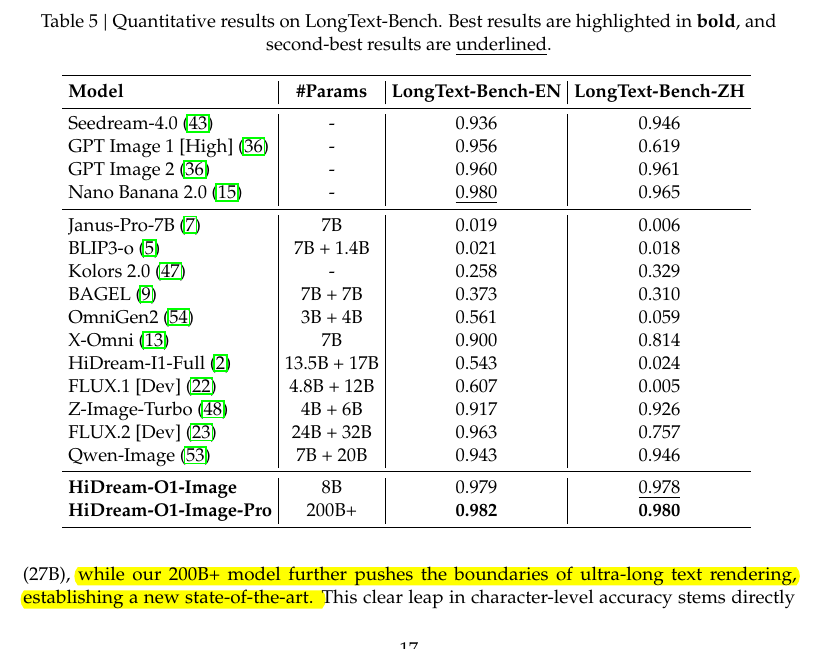
HiDream just open-sourced an 8B image model with a big message behind it: the old diffusion pipeline (VAE-plus-text-encoder) may not be the only serious path left. 8B param, HiDream-O1-Image (8B) claims parity with models over 3x its size (e.g., 27B Qwen-Image). @HiDream_AI , @vivago_ai Key Features 🧬 Pixel-Level Unified Transformer — One end-to-end model on raw pixels, no VAE, no disjoint text encoder. 🎨 One Model, Many Tasks — Text-to-image, long-text rendering, instruction editing, subject-driven personalization, and storyboard generation in a single architecture. 🧠 Reasoning-Driven Prompt Agent — Built-in "thinking" agent that resolves implicit knowledge, layout, and text rendering before generation. 🖼️ Native High Resolution — Direct synthesis up to 2,048 × 2,048 with sharp fine-grained detail. ⚡ Exceptional Efficiency and Versatility at 8B Scale — With only 8B parameters, achieves performance parity with or even surpasses larger open-source DiTs and leading closed-source models. Most image models still split the job across a text encoder, a VAE, and a diffusion model, so details can get lost when real pixels are compressed into hidden image codes. HiDream-O1-Image removes that split by using a Pixel-level Unified Transformer, where raw image patches, text tokens, and task conditions enter the same model space. That means text-to-image, image editing, and subject personalization become variants of one in-context generation task, not separate pipelines. A prompt agent first rewrites messy user requests into clearer visual instructions, reasoning through layout, subject attributes, physics, and context before generation. The strongest result is text rendering. On LongText-Bench, the 8B model scores 0.979 in English and 0.978 in Chinese, while the 200B+ model reaches 0.982 and 0.980. That is the part to watch, because clean text inside generated images is still one of the hardest problems for image models. 🧵 1.
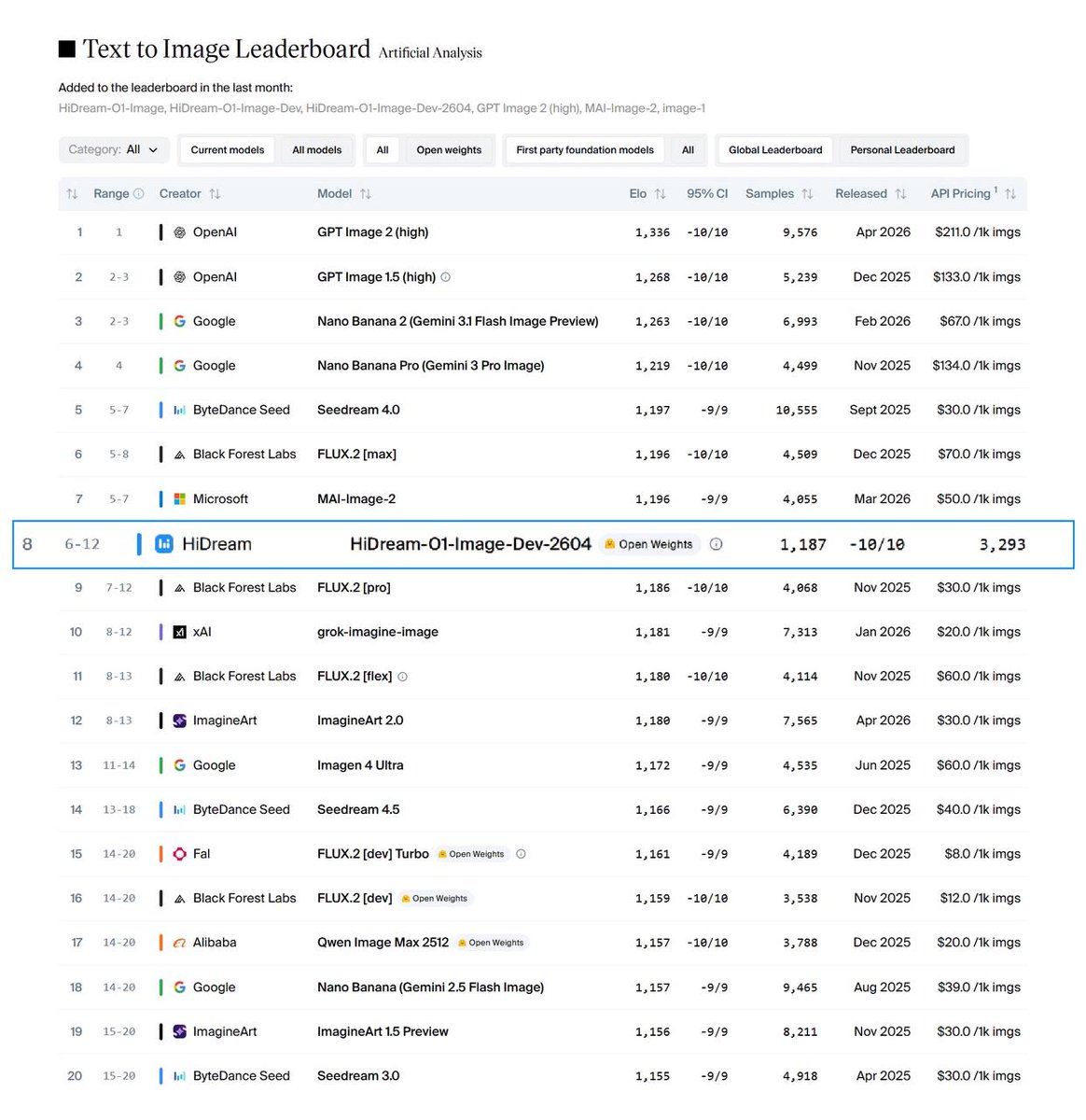
🧵 3. HiDream-O1-Image (codename: Peanut) debuts at #8 in the Artificial Analysis Text to Image Arena,
🧵 2. This diagram explains why HiDream is not just another image generator with a bigger parameter count. HiDream maps text, reference images, task instructions, and raw image patches into one shared token space before generation starts. The model then sends those mixed tokens through one Unified Transformer Backbone, where self-attention lets every part of the request look at every other part. For text-to-image, the condition can be only a prompt, such as cattle grazing in a field. For image editing, the condition includes an input image plus an instruction, such as changing grass, sky, and lighting while keeping the same animal. For subject-driven personalization, the condition includes a reference subject, such as a person, so the model can preserve identity while creating a new scene. The right side explains the generation process: the model predicts clean image patches from noisy image patches, then stitches those patches back into a final image. The important technical shift is that HiDream treats generation, editing, and personalization as the same kind of token prediction problem, instead of building a different pipeline for each task.
🧵 4. Standard image models usually compress images before generation, which saves compute but can lose tiny details like sharp text, clean texture, and exact layout.
HiDream-O1-Image instead patchifies raw pixels and feeds them into the same Transformer stream as text, edits, and reference images.
🧵 3. HiDream-O1-Image (codename: Peanut) debuts at #8 in the Artificial Analysis Text to Image Arena,
🧵 5. General text-to-image generation at up to 2,048 × 2,048.

🧵 4. Standard image models usually compress images before generation, which saves compute but can lose tiny details like sharp text, clean texture, and exact layout. HiDream-O1-Image instead patchifies raw pixels and feeds them into the same Transformer stream as text, edits, and reference images.
🧵 6. Long-text rendering & layout control — accurate, multi-region, multilingual text.

🧵 5. General text-to-image generation at up to 2,048 × 2,048.
🧵 7. Subject-driven personalization — preserve identity / IP across new scenes.

🧵 6. Long-text rendering & layout control — accurate, multi-region, multilingual text.
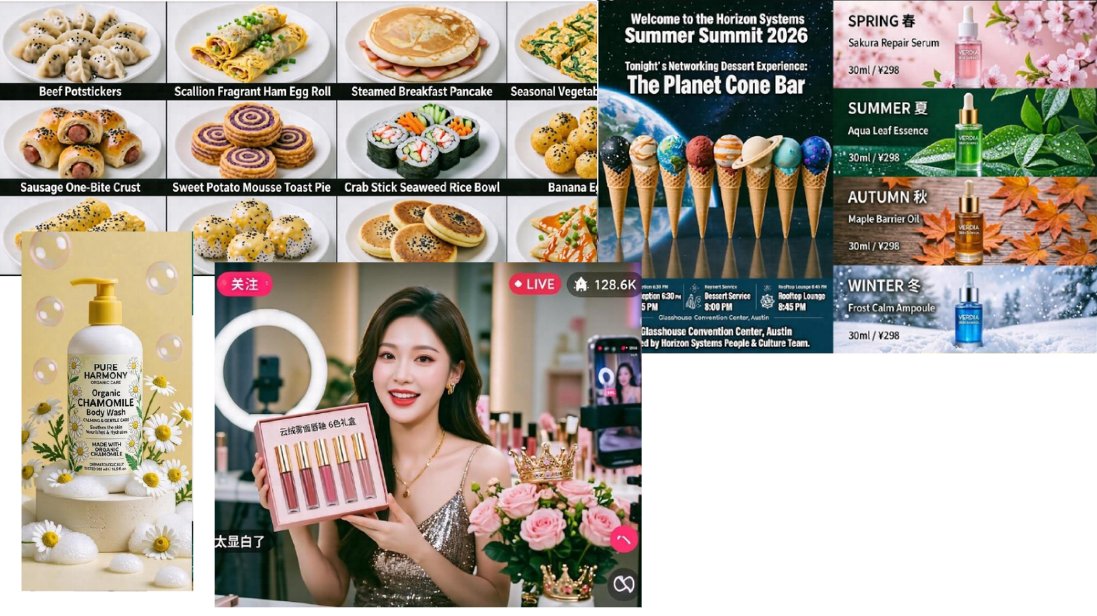
🧵 8. The model also uses a Prompt Agent built on Gemma. When the user gives a messy prompt, the agent first reasons about layout, subject details, physical logic, and scene context, then turns that into a clearer generation prompt.
That is useful for prompts like posters, ads, storyboards, product shots, and multi-object edits.

🧵 7. Subject-driven personalization — preserve identity / IP across new scenes.
🧵 9. HiDream-O1-Image’s 8B model beats GPT Image 2, Seedream-4.0, FLUX.2, and Qwen-Image on “LongText-Bench”.
And this is the hard part that usually breaks image models: it keeps long English and Chinese text readable inside generated images
🧵 8. The model also uses a Prompt Agent built on Gemma. When the user gives a messy prompt, the agent first reasons about layout, subject details, physical logic, and scene context, then turns that into a clearer generation prompt. That is useful for prompts like posters, ads, storyboards, product shots, and multi-object edits.
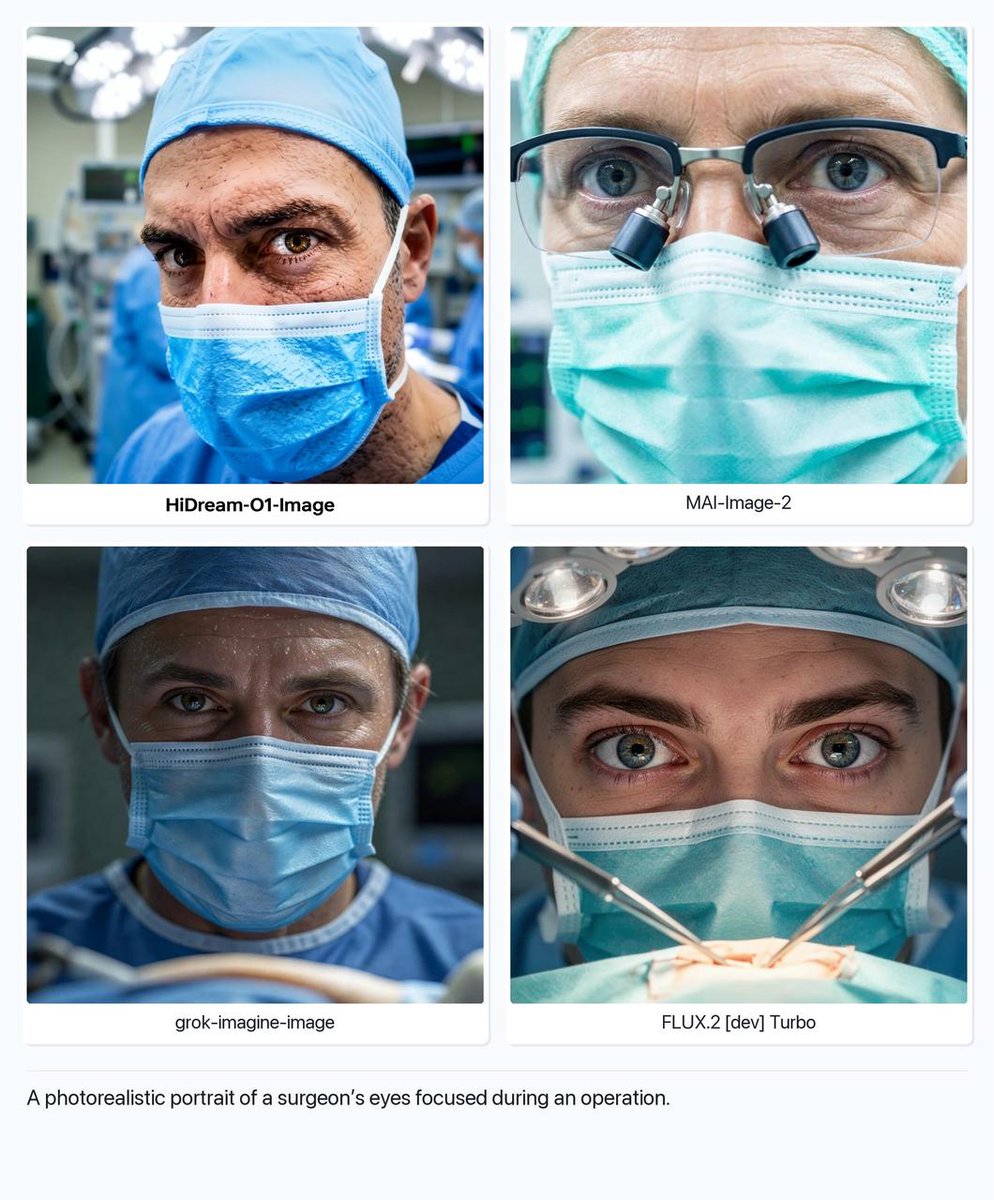
🧵 10. More beautiful results from HiDream-O1-Image



🧵 9. HiDream-O1-Image’s 8B model beats GPT Image 2, Seedream-4.0, FLUX.2, and Qwen-Image on “LongText-Bench”. And this is the hard part that usually breaks image models: it keeps long English and Chinese text readable inside generated images
Github: https://github.com/HiDream-ai/HiDream-O1-Image
Huggingface: https://huggingface.co/HiDream-ai/HiDream-O1-Image
🧵 11. The text rendering capability of HiDream-O1-Image is truly the finest.
🧵 11. The text rendering capability of HiDream-O1-Image is truly the finest.


🧵 10. More beautiful results from HiDream-O1-Image