Cohere releases Command A+, its most powerful large language model to date, as open-source Apache 2.0 software that runs on two H100 GPUs with 30% lower latency
Cohere co-founder Ivan Zhang highlighted efficiency and accessibility design choices.
Cohere is on such a great open-source trajectory lately. Beautiful Apache 2.0 model! https://huggingface.co/CohereLabs/command-a-plus-05-2026-bf16
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
@nickfrosst @cohere Congratulations on this milestone! Looks great 👍
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅
Interesting tidbit is the parallel block design. Via the Cmd-A the tech report "equivalent performance but significant improvement in throughput compared to the vanilla transformer block."

Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@eliebakouch It’s interesting. I’ve seen hidden -> wider -> hidden FFNs and hidden -> narrower -> hidden FFNs. But Command A+ seems tu use 4096 -> 4096 -> 4096 for each expert FFN, which I haven’t seen before (as far as I remember)
@rasbt the query head x head dim being super wide is quite different from other model as well afaik
Our first fully open source Apache 2 model :)
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
Nick really championed us going Apache 2 for this release and for Cohere Transcribe. Not an obvious decision and one that required many discussions. Like Nick says, I hope the model is more useful and empowering as a result.
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
Very cool to see that cohere is continuing to use the parallel attention and MLP set up @AiEleuther introduced
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
Check out our latest open-source model, built for efficiency, with a focus on business use-cases, available for all.
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
What a week to start at Cohere!
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@nickfrosst @cohere hell yeah! model looks great
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
Cohere has fallen, DS-MoE shape reigns supreme

Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@nickfrosst @cohere Very cool release. Much needed in the space.
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
@nickfrosst @cohere great work
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0
Open source Command A+ model
This tech can go one of two ways. It can go the way the internet and mobile phones did - in which technological hegemony resulted in a mostly disempowering tech.
Or it can empower the people that use it.
We are working towards that second one.
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
> be cohere > join forces with some German companies > immediately open source your best model > life is good
wait… did Cohere just release Command A+ models under Apache 2.0 for the first time ever?! 🙊 welcome to Europe! 🤗
Command A+ from @cohere is out now :) its our best model yet and its open source apache 2.0

Cohere dropped Command A+ 🔥
> 25B/219B MoE vision language model > supports 48 languages with efficient tokenizer > tool-calling/agentic + 128k context window > transformers day-0 support 🤗 free license 💗

try their demo and check the models https://huggingface.co/collections/CohereLabs/command-a-plus
Cohere dropped Command A+ 🔥 > 25B/219B MoE vision language model > supports 48 languages with efficient tokenizer > tool-calling/agentic + 128k context window > transformers day-0 support 🤗 free license 💗
Out today! Our most capable agentic model: - Runs on one B200 - 48 languages (including العربية, 日本語, 한국어) - Open source (Apache 2.0 ) - Multimodal: text + images - 218B Mixture-of-Experts model, 25B active parameters
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@aidangomez congrats on the release, would love to see a tech report here, lot of interesting/unusual choices
interesting open model by cohere with lots of unusual architecture choices, here is a recap: > parallel transformer, so MoE and attention are computed in parallel. likely doing some kind of MLP/attention disaggregation here? > lots of query heads, query total dim is 4x hidden size > big shared expert, 4x router size > no scaling after normalization of the top k > LayerNorm instead of RMS norm > 32 layer only, no dense layer at the start
@rasbt the query head x head dim being super wide is quite different from other model as well afaik
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅 Interesting tidbit is the parallel block design. Via the Cmd-A the tech report "equivalent performance but significant improvement in throughput compared to the vanilla transformer block."
interesting open model by cohere with lots of unusual architecture choices, here is a recap:
> parallel transformer, so MoE and attention are computed in parallel. likely doing some kind of MLP/attention disaggregation here? > lots of query heads, query total dim is 4x hidden size > big shared expert, 4x router size > no scaling after normalization of the top k > LayerNorm instead of RMS norm > 32 layer only, no dense layer at the start

Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@torchcompiled yeah actually at training it's pretty nice as well you're right
@eliebakouch Have seen a few parallelized MLP and attention cases, I wanna say one of the flux/SD models did that? My understanding is it’s a small perf hit but with proper parallleization can be a cozy inference and training speed up
also they have a "use_parallel_embedding" flag in the config? engram next?
interesting open model by cohere with lots of unusual architecture choices, here is a recap: > parallel transformer, so MoE and attention are computed in parallel. likely doing some kind of MLP/attention disaggregation here? > lots of query heads, query total dim is 4x hidden size > big shared expert, 4x router size > no scaling after normalization of the top k > LayerNorm instead of RMS norm > 32 layer only, no dense layer at the start
@nrehiew_ yes it's like the "older version" of this basically, the one from palm ect..
@eliebakouch Similar to this? This parallel arch basically halves layer count. The 1/2 weight and router stuff is different though
more pretty version of this visualization here if you are seeing this now
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅 Interesting tidbit is the parallel block design. Via the Cmd-A the tech report "equivalent performance but significant improvement in throughput compared to the vanilla transformer block."
@aidangomez A M A Z I N G !!!!!!
Our first fully open source Apache 2 model :)
@1vnzh @aidangomez real ones know ✊

@aidangomez transcribe erasure bro
@eliebakouch Similar to this? This parallel arch basically halves layer count. The 1/2 weight and router stuff is different though
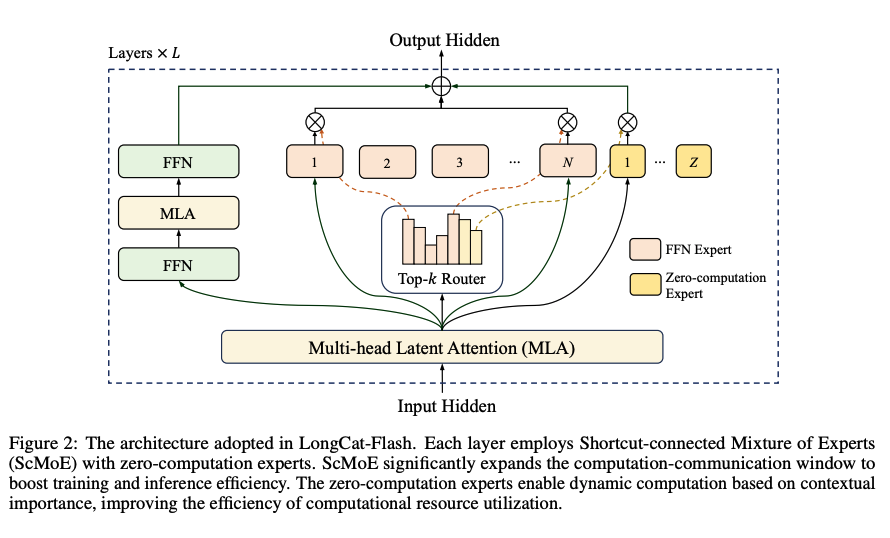
interesting open model by cohere with lots of unusual architecture choices, here is a recap: > parallel transformer, so MoE and attention are computed in parallel. likely doing some kind of MLP/attention disaggregation here? > lots of query heads, query total dim is 4x hidden size > big shared expert, 4x router size > no scaling after normalization of the top k > LayerNorm instead of RMS norm > 32 layer only, no dense layer at the start
4 shared experts with 8 routed experts active? so 12/132, that's crazy, i wonder why. most papers like Towards Greater Leverage would suggest 1 shared expert or minimal (i think we should decouple shared expert size anyway eventually)
also, 128 attention heads with GQA???

We ❤️ Open Source
Introducing: Cohere Command A+ We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
@aidangomez transcribe erasure bro
Our first fully open source Apache 2 model :)
@rasbt it’s from gpt-j https://github.com/kingoflolz/mesh-transformer-jax
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅 Interesting tidbit is the parallel block design. Via the Cmd-A the tech report "equivalent performance but significant improvement in throughput compared to the vanilla transformer block."
@eliebakouch Have seen a few parallelized MLP and attention cases, I wanna say one of the flux/SD models did that? My understanding is it’s a small perf hit but with proper parallleization can be a cozy inference and training speed up
interesting open model by cohere with lots of unusual architecture choices, here is a recap: > parallel transformer, so MoE and attention are computed in parallel. likely doing some kind of MLP/attention disaggregation here? > lots of query heads, query total dim is 4x hidden size > big shared expert, 4x router size > no scaling after normalization of the top k > LayerNorm instead of RMS norm > 32 layer only, no dense layer at the start