Researchers release SMDD-Bench, a benchmark evaluating LLM agents on 502 small molecule drug design tasks across five workflows, with frontier models at roughly 40 percent success
Public leaderboard at smddbench.com and arXiv paper now available.
The 5 task types are all things real medicinal chemists actually do:
2D Pharmacophore ID — write a Python filter that separates actives from inactives Interaction Point Discovery — predict the 3 most conserved 3D hotspots in a pocket Scaffold Hopping — same binding mode, new scaffold Lead Optimization — multi-objective ADMET + affinity under hard constraints Fragment Assembly — link 3D fragments into a drug-like molecule that re-docks to the right pose

🧬New agentic AI-for-science benchmark: SMDD-Bench! Can frontier LLM agents actually do small-molecule drug design? Real medicinal chemistry — not single-turn QA, not toy property prediction. Long-horizon, multi-turn, tool-using, with strict oracle budgets. We release 502 agentic tasks across 5 real drug-design workflows (pharmacophore ID, scaffold hopping, lead optimization, fragment assembly, interaction point discovery), every one guaranteed-solvable via a hidden witness molecule. Agents get a Python sandbox, 8 Boltz2 calls, 15 ADMET-AI calls, no internet — and have to plan across dozens of turns to spend that budget wisely. Result: GPT-5.4 and Gemini 3.1 Pro are neck-and-neck at the top (40.2% vs 39.0%), Claude Sonnet 4.6 right behind at 38%. Open-source models trail meaningfully. Even the best agents fail >60% of the time. 🧵 below
Key methodological idea: witness-aware task generation.
Most "design" benchmarks have no guarantee a solution exists. We co-generate a witness molecule with every task — a hidden molecule that already passes the full evaluator. So every task instance has at least one provably valid answer.
The 5 task types are all things real medicinal chemists actually do: 2D Pharmacophore ID — write a Python filter that separates actives from inactives Interaction Point Discovery — predict the 3 most conserved 3D hotspots in a pocket Scaffold Hopping — same binding mode, new scaffold Lead Optimization — multi-objective ADMET + affinity under hard constraints Fragment Assembly — link 3D fragments into a drug-like molecule that re-docks to the right pose
This is fundamentally a long-horizon, budget-constrained tool-use benchmark that just happens to live in chemistry. Agents have to:
plan across dozens of turns decide which of 23 oracle calls to spend where reason about 3D geometry from text write RDKit code that actually executes generalize SAR rules across turns

Key methodological idea: witness-aware task generation. Most "design" benchmarks have no guarantee a solution exists. We co-generate a witness molecule with every task — a hidden molecule that already passes the full evaluator. So every task instance has at least one provably valid answer.
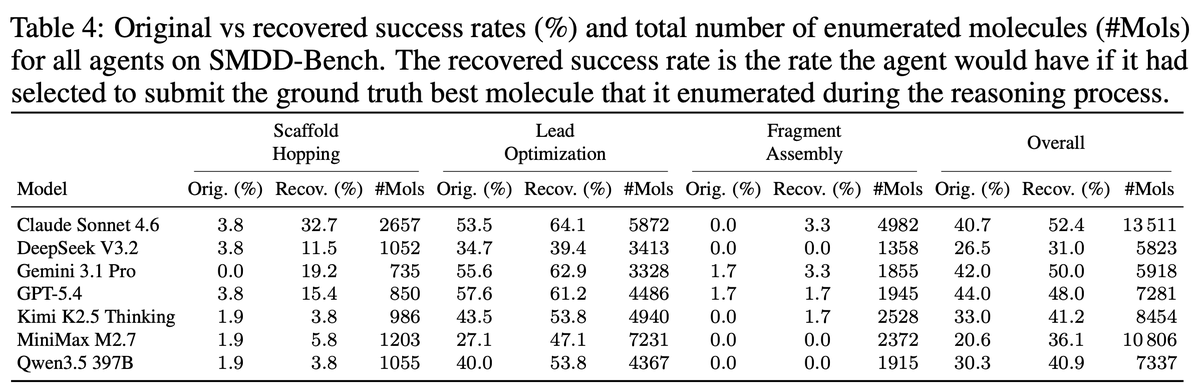
Most interesting finding: LLMs often enumerate the right molecule but fail to pick it.
If agents had submitted the best molecule they ever mentioned in their trace, overall success jumps significantly:
MiniMax M2.7: 20.6% → 36.1% Claude Sonnet 4.6: 40.7% → 52.4% Gemini 3.1 Pro: 42.0% → 50.0%
This is fundamentally a long-horizon, budget-constrained tool-use benchmark that just happens to live in chemistry. Agents have to: plan across dozens of turns decide which of 23 oracle calls to spend where reason about 3D geometry from text write RDKit code that actually executes generalize SAR rules across turns
We also release:
SMDD-Bench Lite — 100-task representative subset for fast iteration SMDD-Bench Diversity — 20-task subset for testing parallel-agent diversity Public leaderboard at http://smddbench.com
We hope this becomes the testbed for training the next generation of autonomous medicinal chemistry agents. 📄 Paper: https://arxiv.org/abs/2605.21740 🌐 Site + leaderboard: https://smddbench.com
Other findings: On Lead Opt, agents often converge to the same handful of molecules across 10 runs — pairwise Tanimoto >0.8. Bad for parallel deployment. Common failure mode: agents test the same disqualified substructure 3+ times. No cross-turn SAR synthesis. Another: Gemini once "solved" a scaffold-hop task by recalling a known PubChem molecule from memory in one shot. Memorization, not design.
Other findings:
On Lead Opt, agents often converge to the same handful of molecules across 10 runs — pairwise Tanimoto >0.8. Bad for parallel deployment. Common failure mode: agents test the same disqualified substructure 3+ times. No cross-turn SAR synthesis. Another: Gemini once "solved" a scaffold-hop task by recalling a known PubChem molecule from memory in one shot. Memorization, not design.
Most interesting finding: LLMs often enumerate the right molecule but fail to pick it. If agents had submitted the best molecule they ever mentioned in their trace, overall success jumps significantly: MiniMax M2.7: 20.6% → 36.1% Claude Sonnet 4.6: 40.7% → 52.4% Gemini 3.1 Pro: 42.0% → 50.0%
Huge thanks to @GoogleCloud @GeminiApp for Gemini credits. None of this benchmarking would have been feasible without them.
We also release: SMDD-Bench Lite — 100-task representative subset for fast iteration SMDD-Bench Diversity — 20-task subset for testing parallel-agent diversity Public leaderboard at http://smddbench.com We hope this becomes the testbed for training the next generation of autonomous medicinal chemistry agents. 📄 Paper: https://arxiv.org/abs/2605.21740 🌐 Site + leaderboard: https://smddbench.com
@niloofar_mire Very cool work, @niloofar_mire and team!
🧬New agentic AI-for-science benchmark: SMDD-Bench! Can frontier LLM agents actually do small-molecule drug design? Real medicinal chemistry — not single-turn QA, not toy property prediction. Long-horizon, multi-turn, tool-using, with strict oracle budgets. We release 502 agentic tasks across 5 real drug-design workflows (pharmacophore ID, scaffold hopping, lead optimization, fragment assembly, interaction point discovery), every one guaranteed-solvable via a hidden witness molecule. Agents get a Python sandbox, 8 Boltz2 calls, 15 ADMET-AI calls, no internet — and have to plan across dozens of turns to spend that budget wisely. Result: GPT-5.4 and Gemini 3.1 Pro are neck-and-neck at the top (40.2% vs 39.0%), Claude Sonnet 4.6 right behind at 38%. Open-source models trail meaningfully. Even the best agents fail >60% of the time. 🧵 below