Serena Ge releases DeepSWE, a long-horizon benchmark designed to evaluate AI coding agents on complex engineering tasks
Its prompts are half the length of SWE-bench Pro.
This is the new standard for engineering evals

Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
Honestly, looks about right, harness (mini-swe-agent) affinities aside Kimi is the closest to a mature autonomous SWE agent out of open models DS is weak and needs handholding (though has isolated strengths like debugging) a mark of good eval: stronger separation of top tier


Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
wow evals caught up to vibes
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
I think what you'll also find is the tasks are like a third the price.
wow evals caught up to vibes
> they built a "NEW" coding benchmark > GPT-5.5 scores 70% > Mythos probably ~90% > mfw it's already saturated > and you are asking "when will the AI bubble pop?"
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
you literally need to build benchmarks where frontier models score below 10% or the benchmark is cooked within 6 months
> they built a "NEW" coding benchmark > GPT-5.5 scores 70% > Mythos probably ~90% > mfw it's already saturated > and you are asking "when will the AI bubble pop?"
New coding benchmark.
GPT-5.5 and GPT-5.4 are ahead of Opus 4.7 💀
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
counterintuitive result right here, imo
the data analysis is well done, lots of thoughts went behind them. great eval!
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
It's truly amazing to see how the general sentiment has shifted in favor of Codex.
I'm reading so many posts saying that Codex is really good now with GPT-5.5, and that Claude Code is regularly preferred.
(I've become a huge Codex fan myself).
At the same time, the new DeepSWE benchmark shows that GPT-5.5 is now ranked number one in this measurement as well.

Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
finally, a great benchmark. now we just need one thousand more.
seriously though, this is great.
and we do need one thousand more.
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
@theo it’s funny i often find myself judging benchmarks on how well they match my own taste.
i should either stop paying attention to benchmarks or stop over valuing my taste.
This is the first code bench that actually aligns with how it feels to use these models coding.
This is the first code bench that actually aligns with how it feels to use these models coding.
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
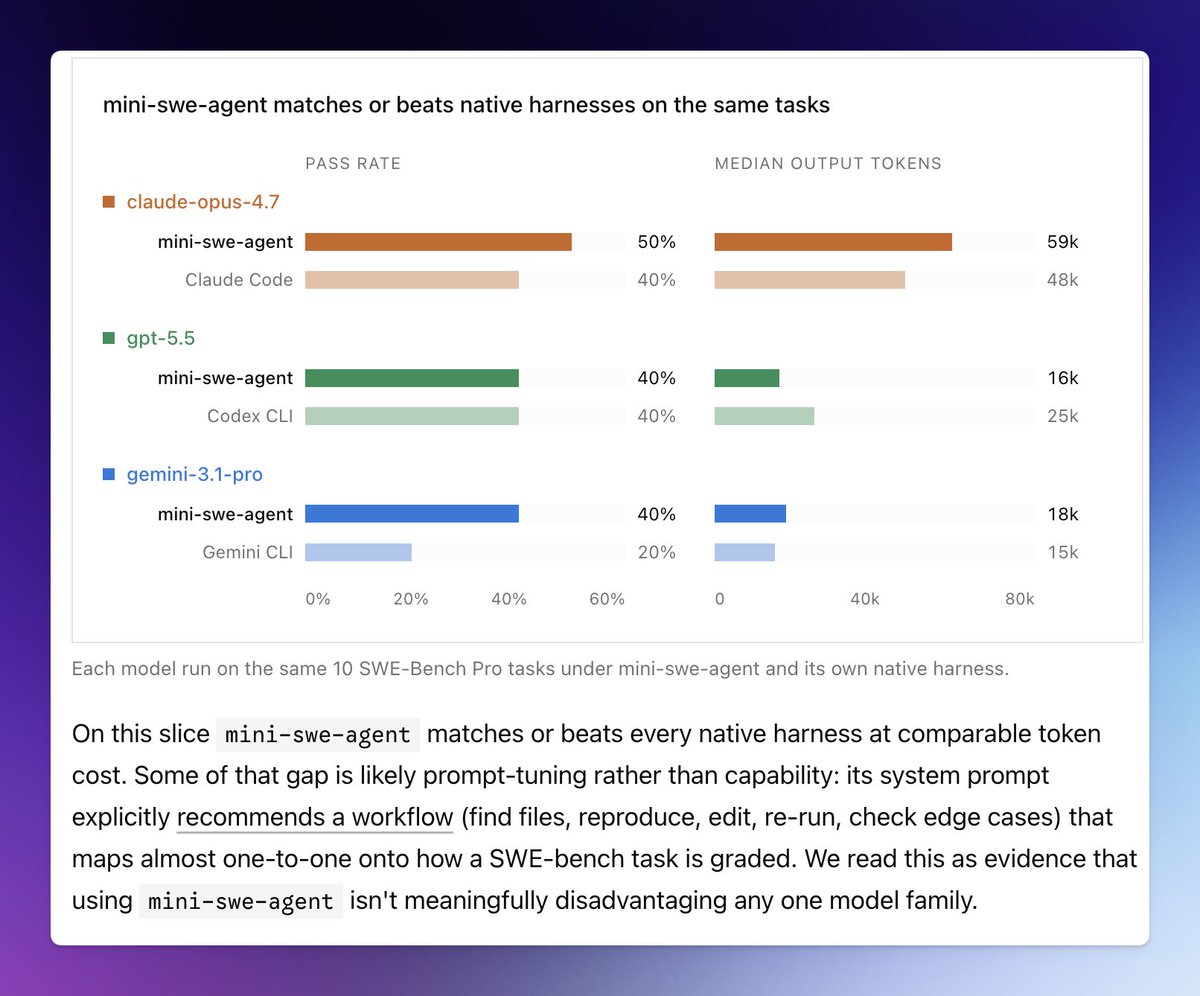
This chart is nuts
This is the first code bench that actually aligns with how it feels to use these models coding.
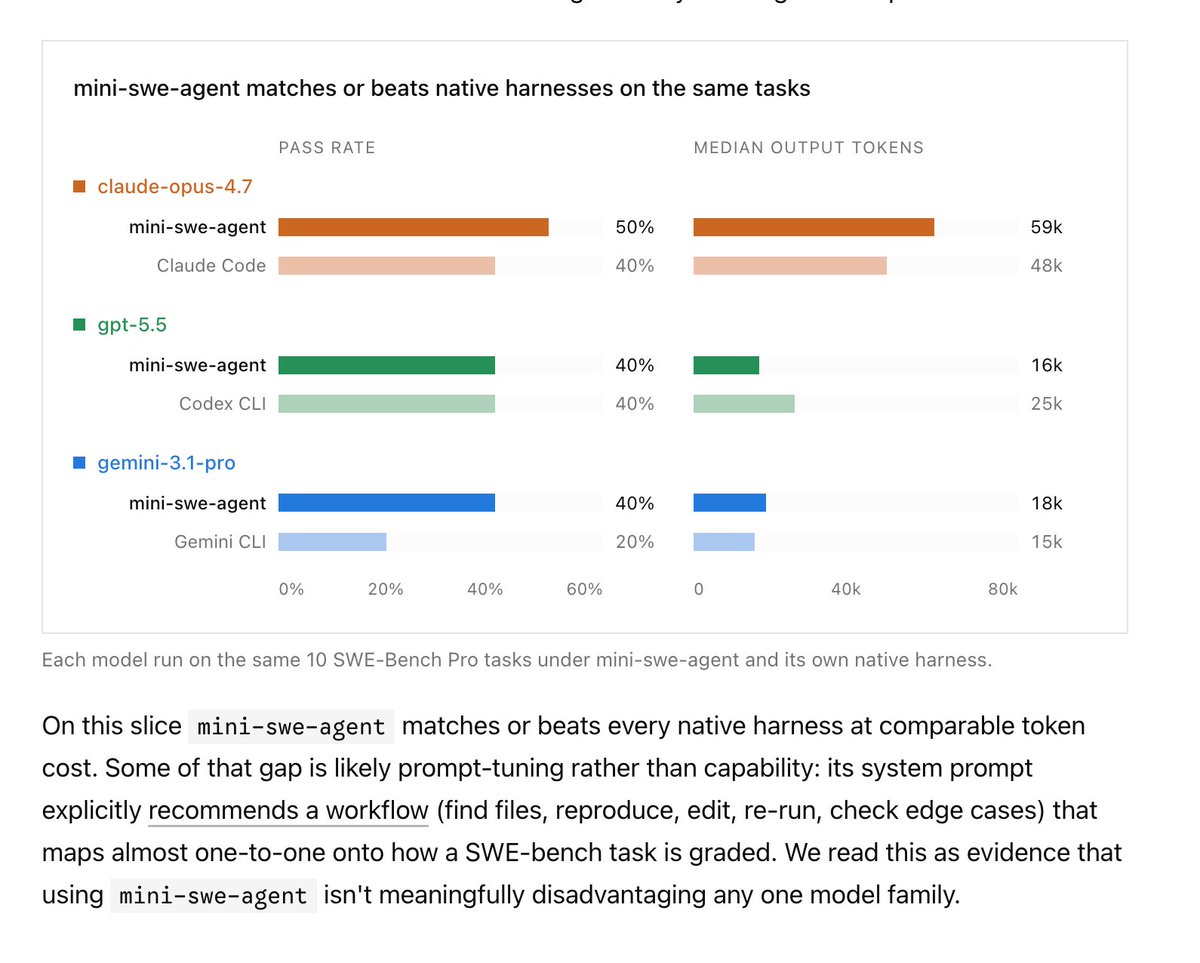
So many gems in this. Gap between "official" harnesses and their simple agent harness says a lot about how the labs are operating. Gemini gap is hilarious
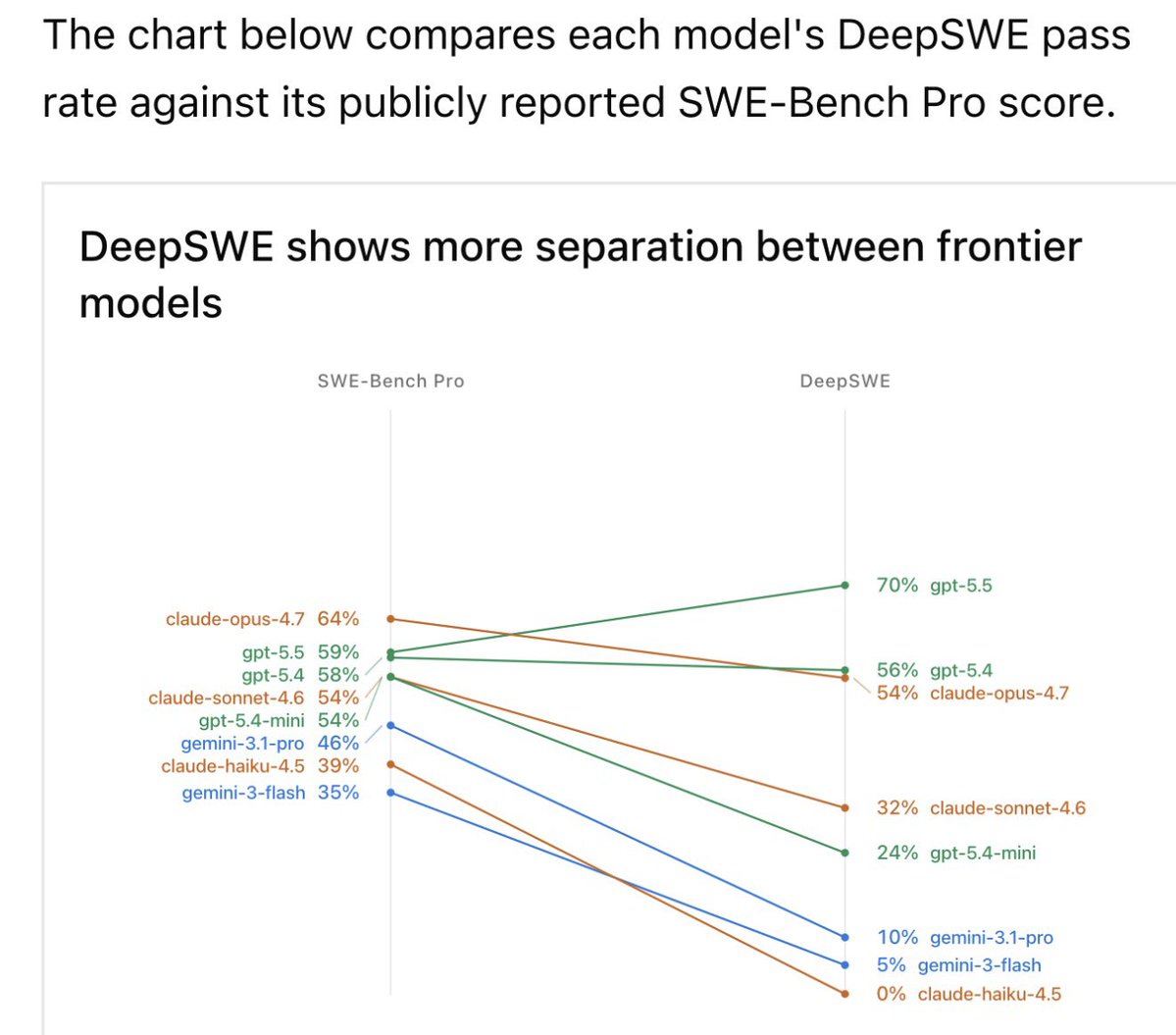
This chart is nuts
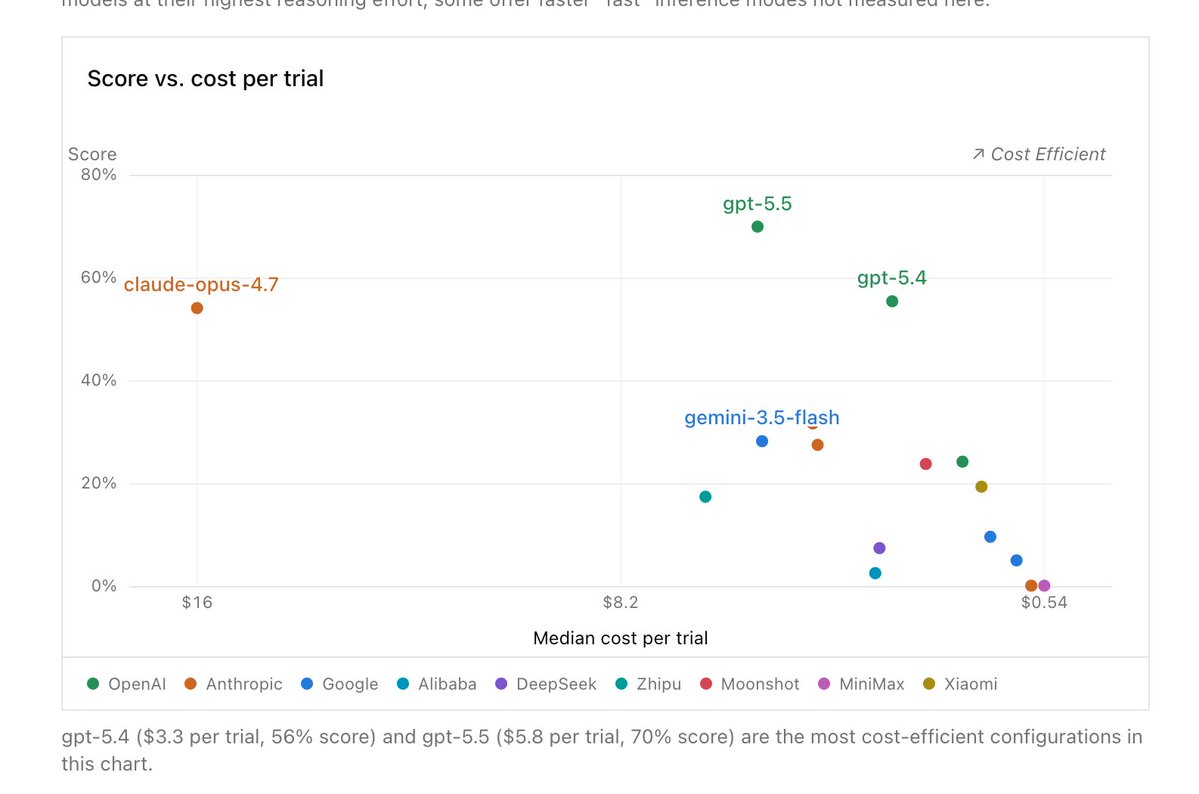
Gemini 3.5 Flash being MORE EXPENSIVE than GPT-5.5 at HALF the score is also hilarious
So many gems in this. Gap between "official" harnesses and their simple agent harness says a lot about how the labs are operating. Gemini gap is hilarious
First correct benchmark I’ve seen in a while
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
