Fresh Random Token Data Matches Repeated Epochs in LLM Training
For these scaling trends, what would be the implied crossing point where an internet-sized pool would benefit from not filtering? The projections suggest ~1e30 FLOPs. Much larger than the largest training runs today, but perhaps within reach in a few years.
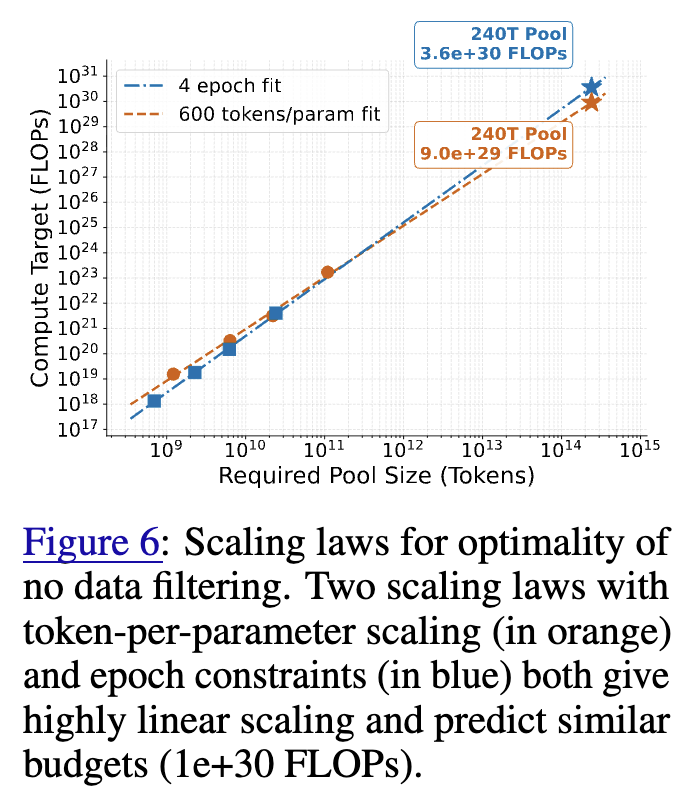
We can ask, is this phenomenon true only for small pool sizes? Or does it hold even when we scale the pool size as well? We find that larger pools change the crossing point, but scaling model size and data means that crossing points can remain at plausible epoch counts.
Does this transfer to benchmarks? The downstream evals are much noisier, but the trends are generally in line with what we see in the pretraining case, with the pool starting low and eventually catching up.

For these scaling trends, what would be the implied crossing point where an internet-sized pool would benefit from not filtering? The projections suggest ~1e30 FLOPs. Much larger than the largest training runs today, but perhaps within reach in a few years.