LisanBench analysis finds Opus 4.8 beats GPT-5.5 among non-thinking models when its thinking configuration is disabled
The model achieved zero wrong-edit-distance failures on the benchmark.
TLDR: Opus 4.8 high ranks only 5th overall, but it is the cleanest and most reliable result so far: #1 validity, 93.3% clean stops, and 0% wrong-edit-distance failures.
It edges out GPT-5.5 on reasoning efficiency, and cost-efficiency, but behaves differently: less exploratory, more controlled, and much more likely to reuse long word-chain "highways"
LisanBench Update Opus 4.8 with the default high thinking setting ranks 5th overall. Without thinking enabled it outscores GPT-5.5 and takes back the #1 non-thinking spot. Despite ranking 5th place Opus 4.8 is by other metrics the best model and an improvement over Opus 4.6 and 4.7 and overall similar to GPT-5.5. Opus 4.8 (high) ranks #1 by validity (valid transitions / all checked transitions). Opus 4.8 (high) is also ranked 1st when you look at the failure modes with 93.3% of responses without any errors and 0% wrong edit distance. GPT-5.5 only comes to a clean stop 31.3% of the time, and fails 52.7% of the time because of wrong edit distance. In terms of reasoning efficiency and cost-efficiency Opus 4.8 (high) and GPT-5.5-medium are very similar, but Opus 4.8 edges out a win in both. Opus 4.8 non-thinking still sometimes exposes self-correction traces like "Wait, let me redo…". This is not unique to Opus 4.8; earlier non-thinking Claude Opus models did it too, especially Opus 4.6 and 4.7. I did not find the same explicit meta-correction pattern in GPT-5.5 no-thinking. In its behavior Opus 4.8 (high) is less explorative than Opus 4.7 (xhigh) and GPT-5.5. It does not lean on the same plural/singular bridge pattern as Claude 4.6; instead it shows a different reuse pattern I call highways. Highways are chains of words that a model reuses across at least 2 starting words. Opus 4.8 uses highways way more than other models. It has the most 10-word highways (repeating chains of 10 words) and also the longest individual highway of 45 words. About 16.5% of Opus 4.8 (high)'s 10-word path segments appeared again in another starting word, vs only 0.92% for GPT-5.5. For Opus 4.8 (non-thinking) this metric is at a whopping 41.59%. In summary, Opus 4.8 is a very strong and efficient model that reverses the more explorative aspects of Opus 4.7. ---- Opus 4.8 (high) scoring only 5th made me curious as to why that is. It turns out that some word chains are not counted properly, because some words like "spams", "blog", "gamers", "dork" and many others were not included in the dictionary and falsely flagged as incorrect transitions. When I RL'd smaller Qwen3 models on LisanBench, I noticed other quality issues with the dictionary, for example that it has dozens of 1-letter words beyond just the standard letters of the alphabet, like mathematical symbols and umlauts. Because of that I decided to change the dictionary from words_alpha.txt from dwyl/english-words to SCOWL (the exact version will be in the repo once I update it). The new dictionary only affects the rankings modestly. (see image in thread below With the new dictionary, there are now only two 1-letter words "I" and "a", and a lot of words that should be included are present making most models score a bit higher. All starting words are still in the same connected component, meaning even from difficult starting words in sparse regions there's a path into denser regions.
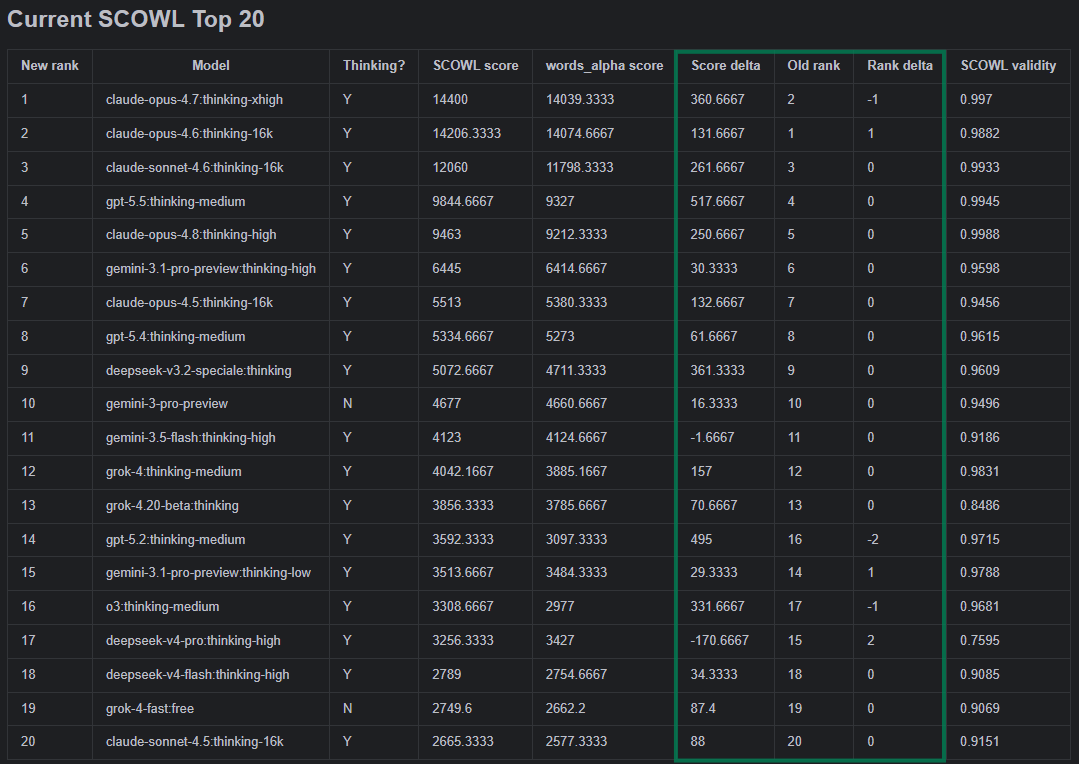
LisanBench Update Opus 4.8 with the default high thinking setting ranks 5th overall. Without thinking enabled it outscores GPT-5.5 and takes back the #1 non-thinking spot. Despite ranking 5th place Opus 4.8 is by other metrics the best model and an improvement over Opus 4.6 and 4.7 and overall similar to GPT-5.5. Opus 4.8 (high) ranks #1 by validity (valid transitions / all checked transitions). Opus 4.8 (high) is also ranked 1st when you look at the failure modes with 93.3% of responses without any errors and 0% wrong edit distance. GPT-5.5 only comes to a clean stop 31.3% of the time, and fails 52.7% of the time because of wrong edit distance. In terms of reasoning efficiency and cost-efficiency Opus 4.8 (high) and GPT-5.5-medium are very similar, but Opus 4.8 edges out a win in both. Opus 4.8 non-thinking still sometimes exposes self-correction traces like "Wait, let me redo…". This is not unique to Opus 4.8; earlier non-thinking Claude Opus models did it too, especially Opus 4.6 and 4.7. I did not find the same explicit meta-correction pattern in GPT-5.5 no-thinking. In its behavior Opus 4.8 (high) is less explorative than Opus 4.7 (xhigh) and GPT-5.5. It does not lean on the same plural/singular bridge pattern as Claude 4.6; instead it shows a different reuse pattern I call highways. Highways are chains of words that a model reuses across at least 2 starting words. Opus 4.8 uses highways way more than other models. It has the most 10-word highways (repeating chains of 10 words) and also the longest individual highway of 45 words. About 16.5% of Opus 4.8 (high)'s 10-word path segments appeared again in another starting word, vs only 0.92% for GPT-5.5. For Opus 4.8 (non-thinking) this metric is at a whopping 41.59%. In summary, Opus 4.8 is a very strong and efficient model that reverses the more explorative aspects of Opus 4.7. ---- Opus 4.8 (high) scoring only 5th made me curious as to why that is. It turns out that some word chains are not counted properly, because some words like "spams", "blog", "gamers", "dork" and many others were not included in the dictionary and falsely flagged as incorrect transitions. When I RL'd smaller Qwen3 models on LisanBench, I noticed other quality issues with the dictionary, for example that it has dozens of 1-letter words beyond just the standard letters of the alphabet, like mathematical symbols and umlauts. Because of that I decided to change the dictionary from words_alpha.txt from dwyl/english-words to SCOWL (the exact version will be in the repo once I update it). The new dictionary only affects the rankings modestly. (see image in thread below With the new dictionary, there are now only two 1-letter words "I" and "a", and a lot of words that should be included are present making most models score a bit higher. All starting words are still in the same connected component, meaning even from difficult starting words in sparse regions there's a path into denser regions.
I still really want to fix the token issue.
I would like for each model the TTC scaling curves, then the scores would be better comparable.
LisanBench is a lot about perseverance and extra tokens really help the models score higher.
Opus 4.7 xhigh probably just scores higher because it uses literally 3x the tokens
Opus 4.6 and Sonnet 4.6 score higher because their "bridge pattern" exploit is better than the "highway" one
LisanBench Update Opus 4.8 with the default high thinking setting ranks 5th overall. Without thinking enabled it outscores GPT-5.5 and takes back the #1 non-thinking spot. Despite ranking 5th place Opus 4.8 is by other metrics the best model and an improvement over Opus 4.6 and 4.7 and overall similar to GPT-5.5. Opus 4.8 (high) ranks #1 by validity (valid transitions / all checked transitions). Opus 4.8 (high) is also ranked 1st when you look at the failure modes with 93.3% of responses without any errors and 0% wrong edit distance. GPT-5.5 only comes to a clean stop 31.3% of the time, and fails 52.7% of the time because of wrong edit distance. In terms of reasoning efficiency and cost-efficiency Opus 4.8 (high) and GPT-5.5-medium are very similar, but Opus 4.8 edges out a win in both. Opus 4.8 non-thinking still sometimes exposes self-correction traces like "Wait, let me redo…". This is not unique to Opus 4.8; earlier non-thinking Claude Opus models did it too, especially Opus 4.6 and 4.7. I did not find the same explicit meta-correction pattern in GPT-5.5 no-thinking. In its behavior Opus 4.8 (high) is less explorative than Opus 4.7 (xhigh) and GPT-5.5. It does not lean on the same plural/singular bridge pattern as Claude 4.6; instead it shows a different reuse pattern I call highways. Highways are chains of words that a model reuses across at least 2 starting words. Opus 4.8 uses highways way more than other models. It has the most 10-word highways (repeating chains of 10 words) and also the longest individual highway of 45 words. About 16.5% of Opus 4.8 (high)'s 10-word path segments appeared again in another starting word, vs only 0.92% for GPT-5.5. For Opus 4.8 (non-thinking) this metric is at a whopping 41.59%. In summary, Opus 4.8 is a very strong and efficient model that reverses the more explorative aspects of Opus 4.7. ---- Opus 4.8 (high) scoring only 5th made me curious as to why that is. It turns out that some word chains are not counted properly, because some words like "spams", "blog", "gamers", "dork" and many others were not included in the dictionary and falsely flagged as incorrect transitions. When I RL'd smaller Qwen3 models on LisanBench, I noticed other quality issues with the dictionary, for example that it has dozens of 1-letter words beyond just the standard letters of the alphabet, like mathematical symbols and umlauts. Because of that I decided to change the dictionary from words_alpha.txt from dwyl/english-words to SCOWL (the exact version will be in the repo once I update it). The new dictionary only affects the rankings modestly. (see image in thread below With the new dictionary, there are now only two 1-letter words "I" and "a", and a lot of words that should be included are present making most models score a bit higher. All starting words are still in the same connected component, meaning even from difficult starting words in sparse regions there's a path into denser regions.
but of course creating these scaling curves requires like 5x more money for benchmarking
I have already experimented with reduced word sets to save $, but then CIs blow up
idk if I want to spend like 5-10k on benchmarking just to have some scaling curves, that's like a solid double digit percentage of my net worth lmao
I still really want to fix the token issue. I would like for each model the TTC scaling curves, then the scores would be better comparable. LisanBench is a lot about perseverance and extra tokens really help the models score higher. Opus 4.7 xhigh probably just scores higher because it uses literally 3x the tokens Opus 4.6 and Sonnet 4.6 score higher because their "bridge pattern" exploit is better than the "highway" one
website should also include Opus 4.8 results now
LisanBench Update Opus 4.8 with the default high thinking setting ranks 5th overall. Without thinking enabled it outscores GPT-5.5 and takes back the #1 non-thinking spot. Despite ranking 5th place Opus 4.8 is by other metrics the best model and an improvement over Opus 4.6 and 4.7 and overall similar to GPT-5.5. Opus 4.8 (high) ranks #1 by validity (valid transitions / all checked transitions). Opus 4.8 (high) is also ranked 1st when you look at the failure modes with 93.3% of responses without any errors and 0% wrong edit distance. GPT-5.5 only comes to a clean stop 31.3% of the time, and fails 52.7% of the time because of wrong edit distance. In terms of reasoning efficiency and cost-efficiency Opus 4.8 (high) and GPT-5.5-medium are very similar, but Opus 4.8 edges out a win in both. Opus 4.8 non-thinking still sometimes exposes self-correction traces like "Wait, let me redo…". This is not unique to Opus 4.8; earlier non-thinking Claude Opus models did it too, especially Opus 4.6 and 4.7. I did not find the same explicit meta-correction pattern in GPT-5.5 no-thinking. In its behavior Opus 4.8 (high) is less explorative than Opus 4.7 (xhigh) and GPT-5.5. It does not lean on the same plural/singular bridge pattern as Claude 4.6; instead it shows a different reuse pattern I call highways. Highways are chains of words that a model reuses across at least 2 starting words. Opus 4.8 uses highways way more than other models. It has the most 10-word highways (repeating chains of 10 words) and also the longest individual highway of 45 words. About 16.5% of Opus 4.8 (high)'s 10-word path segments appeared again in another starting word, vs only 0.92% for GPT-5.5. For Opus 4.8 (non-thinking) this metric is at a whopping 41.59%. In summary, Opus 4.8 is a very strong and efficient model that reverses the more explorative aspects of Opus 4.7. ---- Opus 4.8 (high) scoring only 5th made me curious as to why that is. It turns out that some word chains are not counted properly, because some words like "spams", "blog", "gamers", "dork" and many others were not included in the dictionary and falsely flagged as incorrect transitions. When I RL'd smaller Qwen3 models on LisanBench, I noticed other quality issues with the dictionary, for example that it has dozens of 1-letter words beyond just the standard letters of the alphabet, like mathematical symbols and umlauts. Because of that I decided to change the dictionary from words_alpha.txt from dwyl/english-words to SCOWL (the exact version will be in the repo once I update it). The new dictionary only affects the rankings modestly. (see image in thread below With the new dictionary, there are now only two 1-letter words "I" and "a", and a lot of words that should be included are present making most models score a bit higher. All starting words are still in the same connected component, meaning even from difficult starting words in sparse regions there's a path into denser regions.
@scaling01 clean is the best way I have to describe this model. it is clean, in a very profound sense. it doesn't go around doing random chaotically unclean shit. I have no better words to express this
TLDR: Opus 4.8 high ranks only 5th overall, but it is the cleanest and most reliable result so far: #1 validity, 93.3% clean stops, and 0% wrong-edit-distance failures. It edges out GPT-5.5 on reasoning efficiency, and cost-efficiency, but behaves differently: less exploratory, more controlled, and much more likely to reuse long word-chain "highways"