Research Shows 2-Layer Models Memorize Graphs With Minimal Eigendirections
We also studied how different hyperparameters (lr, wd, initialization) in training affects whether the model memorizes geometrically or associatively. It seems like there are various knobs that make the model memorize. Hope this helps as a starting point for some theory!
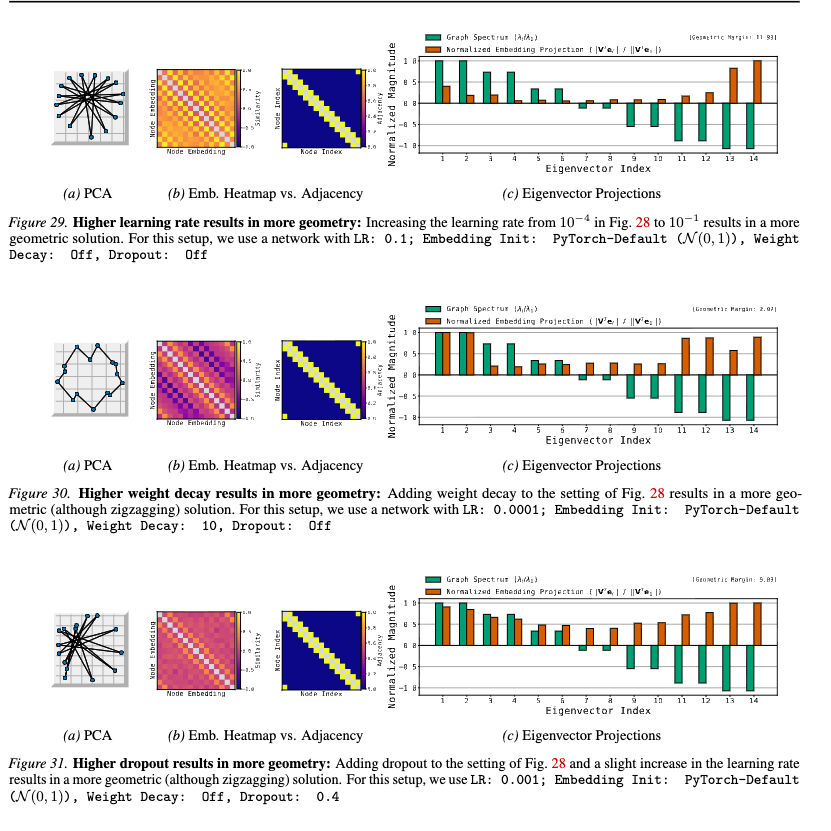
Also added clearer plots showing something unexplained by any existing theory about word2vec/node2vec models: a wide 2-layer model under CE loss somehow uses only a minimal set of eigendirections to memorize a graph even w/o regularization! (e.g., 2 directions for cycle graph)
We also tried our best to make the paper as short and load-able as we could...
tagging co-authors @ShNoroozi (who led the work) and @ElanRosenfeld
Meet us at ICML if you want to chat!
We also studied how different hyperparameters (lr, wd, initialization) in training affects whether the model memorizes geometrically or associatively. It seems like there are various knobs that make the model memorize. Hope this helps as a starting point for some theory!