OpenClaw outperforms Hermes Agent on a GitHub star history scraping and live dashboard task using the Qwen 35B model on a MacBook Pro M5 Max, finishing in just over 12 minutes with 203k tokens
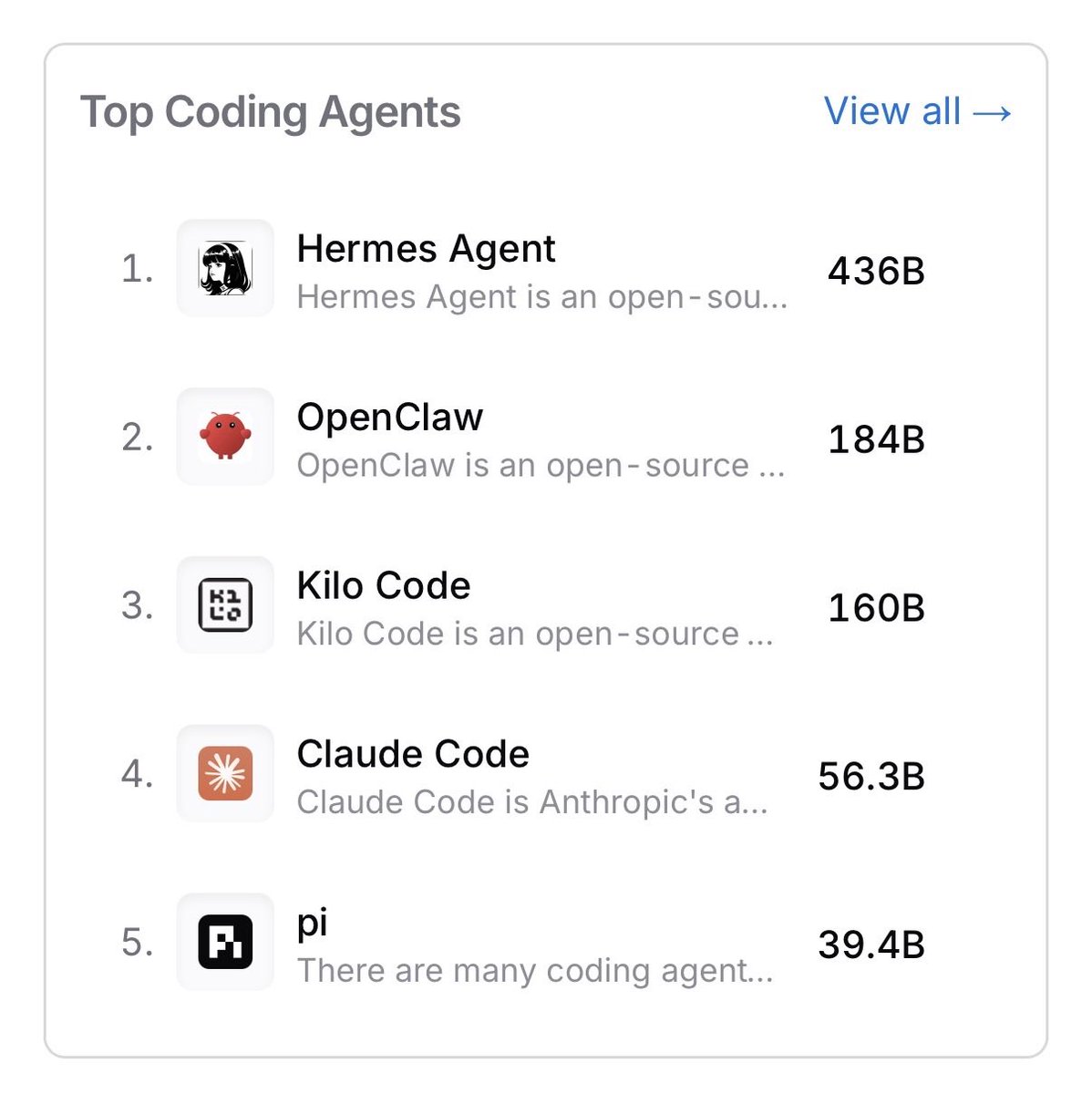
Separate evaluations ranked Hermes Agent first and OpenClaw second among coding agents that also included Kilo Code, Claude Code, and pi.
I’m sorry that you’re this desperate that you will take such an unscientific benchmark instead of any established one.
Also qwen local is one of the most random length models there is with all its looping. And we smoke you all on quality benchmarks on every open model. Here’s wildclawbench by internlm, same speed on open models, much better results.
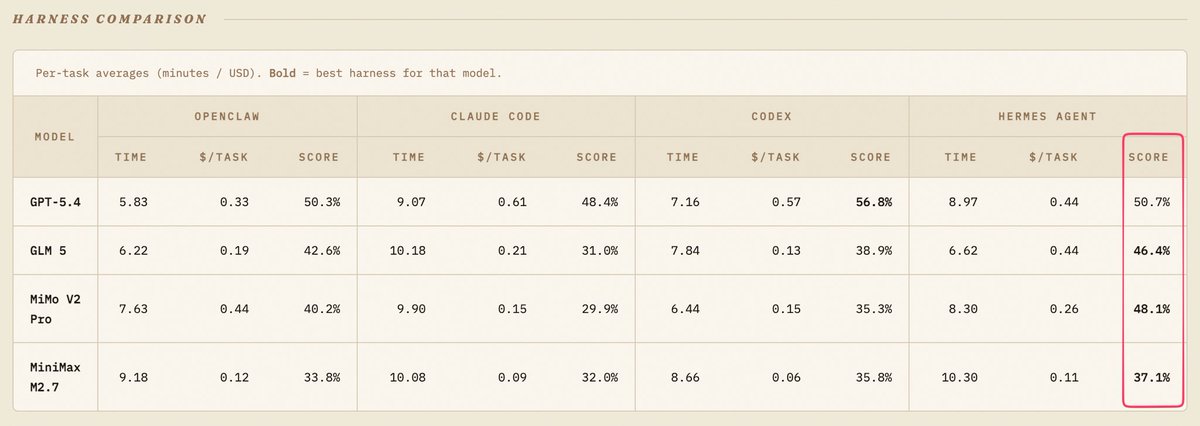
Looks like our focus on performance paid off.
Also there’s this wolfbench too by weights and biases. But do any of these benchmarks matter? I’d argue generally no! It’s the user experience and the community experience that matters, and you have failed. Thats part why your token throughput has done nothing but collapse, starting the day Hermes was released, and in just 3 days since surpassing you, we’ve nearly 2.5x’ed your token volume. Real users using it. They chose.
While i have the lucky few of you who read Peters tweets here, heres a free 20$ sub to Nous Portal for Hermes Agent, where you can access 300+ models at discounted rates and all the core hermes tools, and even free models. First 100 new users only. Time to drop the lobster
BAZOZFN1
100 uses. Sign up at https://portal.nousresearch.com/manage-subscription
Also there’s this wolfbench too by weights and biases. But do any of these benchmarks matter? I’d argue generally no! It’s the user experience and the community experience that matters, and you have failed. Thats part why your token throughput has done nothing but collapse, starting the day Hermes was released, and in just 3 days since surpassing you, we’ve nearly 2.5x’ed your token volume. Real users using it. They chose.
Looks like our focus on performance paid off.