Dwarkesh Podcast analysis identifies selection of research questions and detection of unproductive paths as primary bottlenecks to automating AI research
Models already execute experiments reliably but lack strategic oversight.
——0——
QUOTE POST #980Lisan al Gaib@SCALING01
#980Lisan al Gaib@SCALING01
interesting results on this new benchmark
hyperparam search > sonnet 4.6 > glm-5 > gpt-5.5 > vLLM default > Opus 4.7
lol
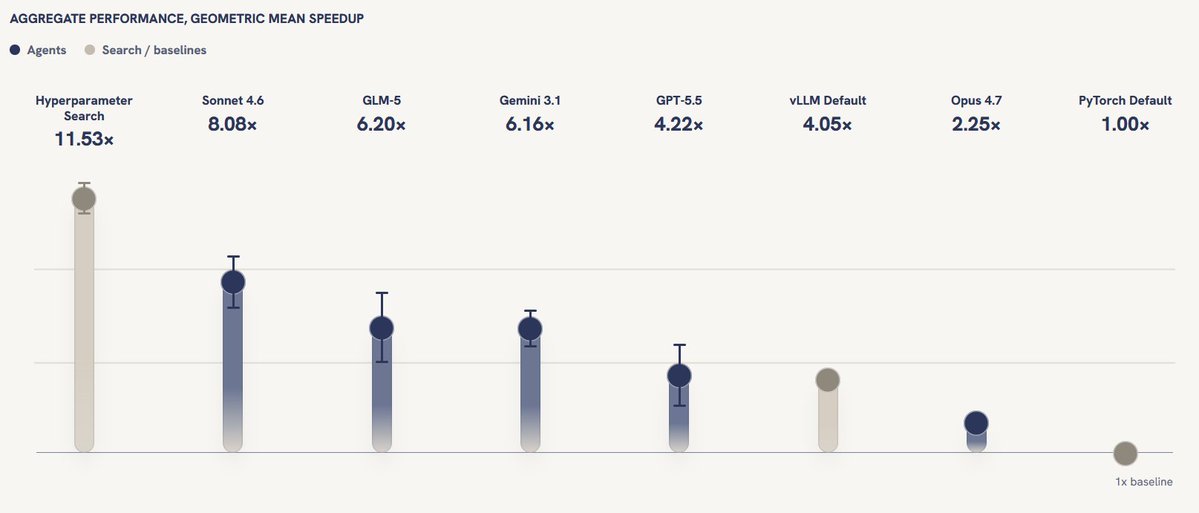
AI R&D agents look great in demos. They write code, fix bugs, and propose research-shaped ideas. But what do researchers actually spend their time doing? Fighting dependency conflicts, noisy metrics, and configs that I’m pretty sure worked 20 minutes ago. Can agents do that? 🧵
2:19 PM · May 20, 2026 · 5.3K Views
3:33 PM · May 20, 2026 · 1.4K Views