Sebastian Raschka ranks 28 LLMs by active parameters
Sebastian Raschka posted a table from his LLM Architecture Gallery that ranks 28 large language models by active parameters per token. DeepSeek V4-Pro leads at 3.1 percent active parameters, followed by Kimi K2 variants at 3.2 percent and Qwen3 80B-A3B at 3.8 percent. The table shows active versus total parameter counts, model type, attention mechanism, and release dates. It offers one comparative view for sparse models while omitting KV cache size, routing overhead, context length, and hardware efficiency.
Meta observation: DeepSeek is still king of the active-parameter ratio
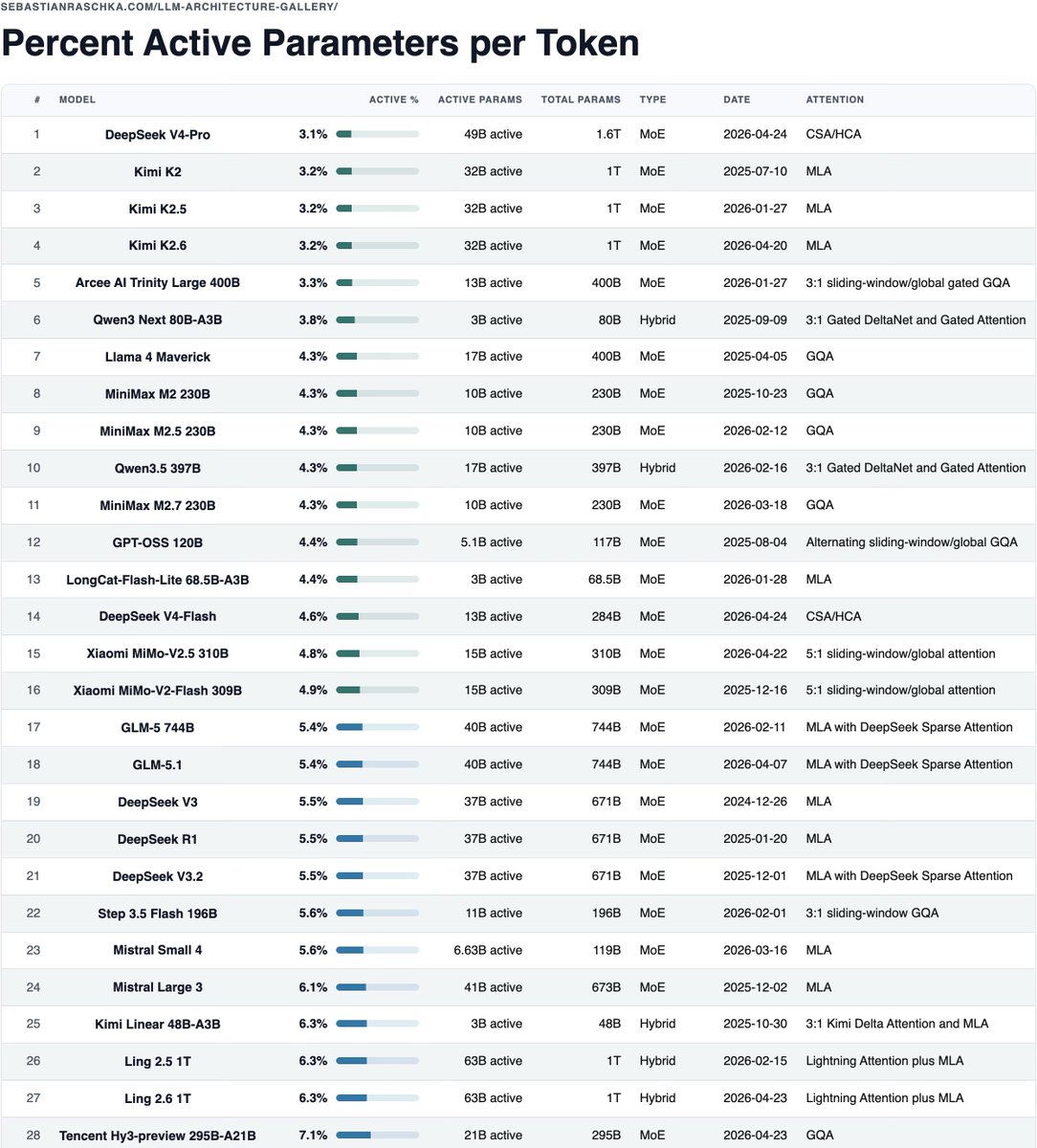
The table in HTML format for easier (and non-truncated) viewing: https://sebastianraschka.com/llm-architecture-gallery/active-parameter-ratio/
Meta observation: DeepSeek is still king of the active-parameter ratio
@teortaxesTex good catch, will add
@rasbt Xiaomi 2.5 pro missing (4.2%, 1T)
@scaling01 This is a truncated one... but Google was on the bottom of the list
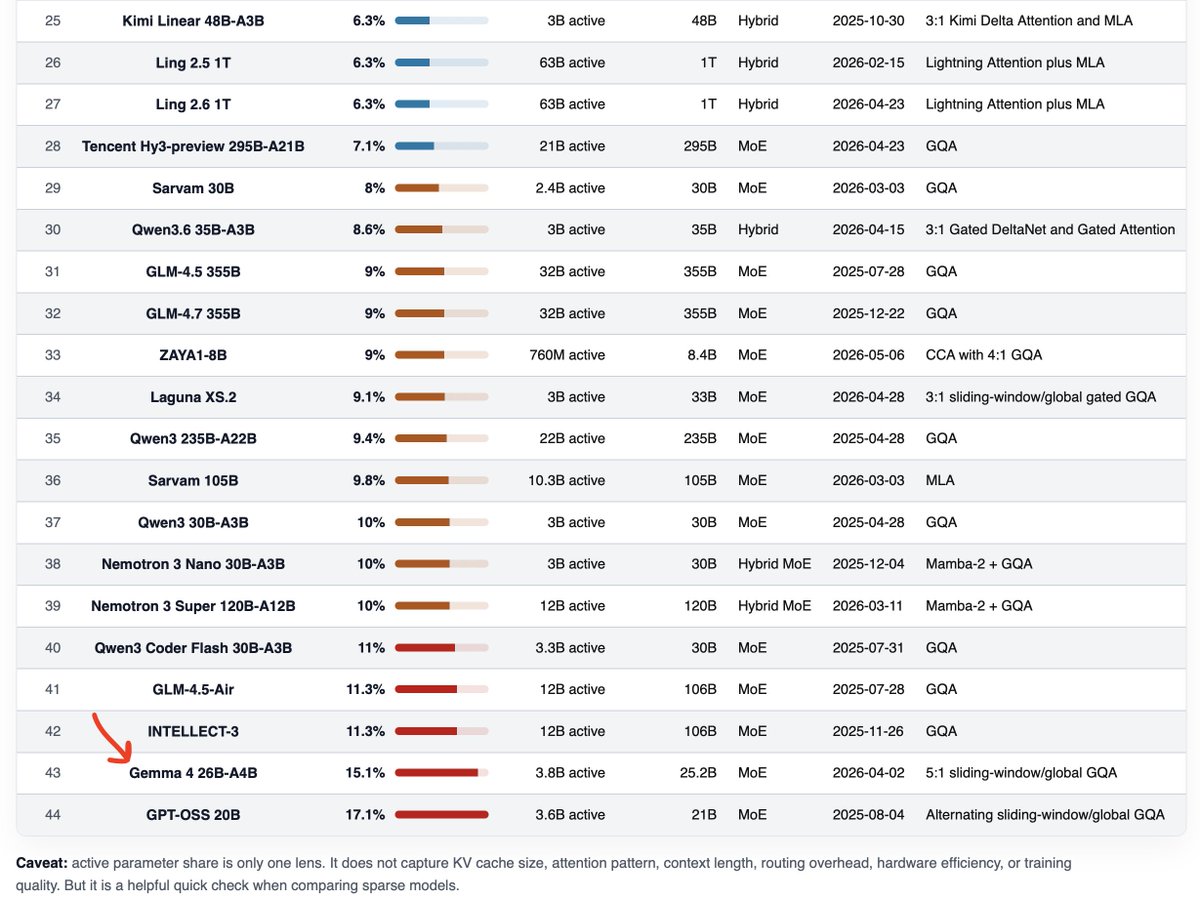
I wouldn't be surprised if Google was at 1-2% active
@rasbt Xiaomi 2.5 pro missing (4.2%, 1T)
Meta observation: DeepSeek is still king of the active-parameter ratio
@scaling01 Likely all the incoming generation of frontier models. Extreme sparsity is economic viability.
I wouldn't be surprised if Google was at 1-2% active
I wouldn't be surprised if Google was at 1-2% active
Meta observation: DeepSeek is still king of the active-parameter ratio
@rasbt I mean the closed Gemini 3 models
@scaling01 This is a truncated one... but Google was on the bottom of the list