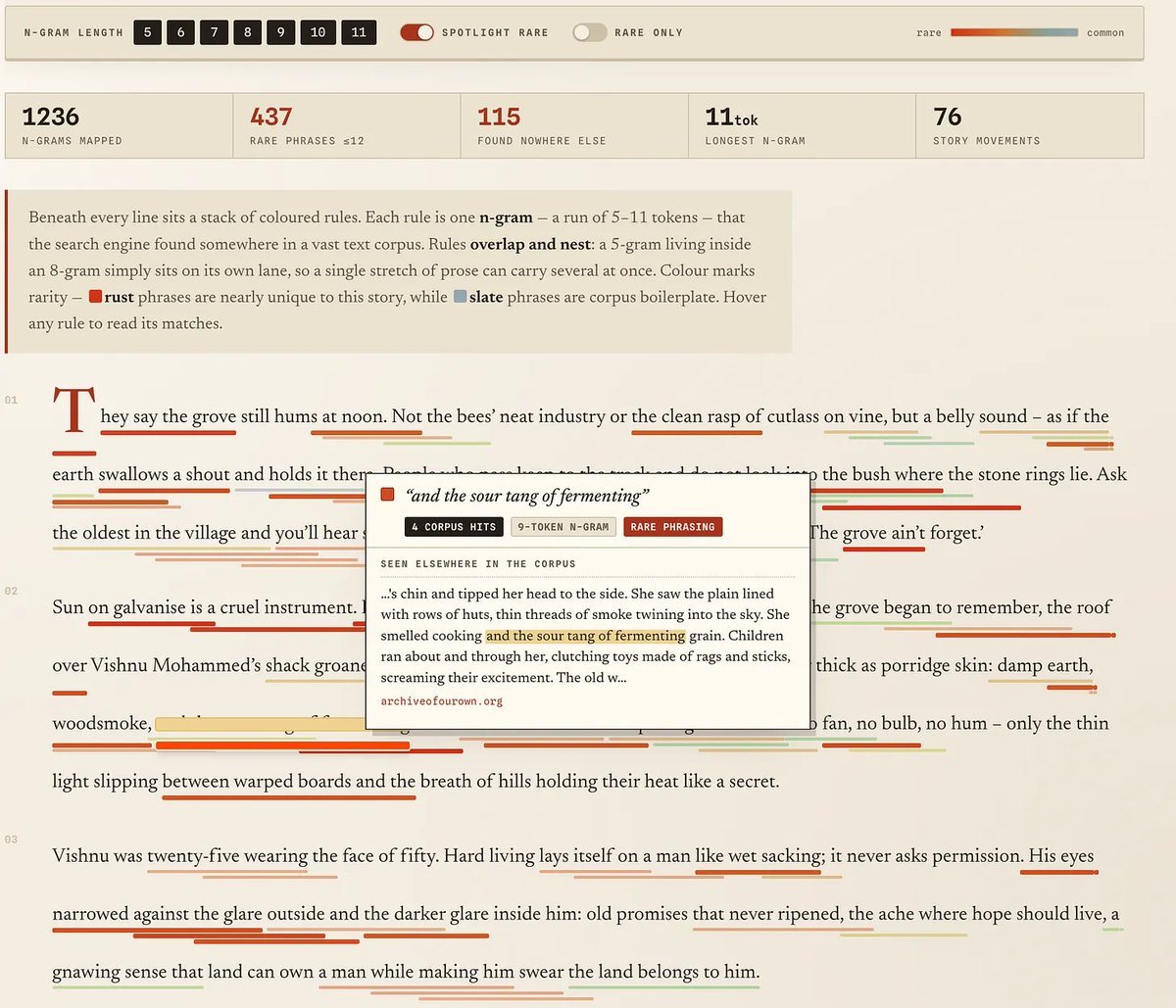
Stony Brook's Tuhin Chakrabarty finds a prize-winning Granta story contains 1,236 phrases copied from online fanfiction
An n-gram tool mapped the phrases to fanfiction sites.
@alexolegimas @TuhinChakr Built on an ai2 project led by @liujc1998 !!!
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction. https://tuhinchakrabarty.substack.com/p/ai-slop-grantagate-and-bad-writing
@TuhinChakr @alexolegimas @liujc1998 I know just saying for fun!
@natolambert @alexolegimas @liujc1998 @natolambert fyi i am not stealing any credit. I have already attributed it to infinigram in the substack as well as mentioned creativity index and olmo trace several times on X after :)
Paging Alan Sokol.
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction. https://tuhinchakrabarty.substack.com/p/ai-slop-grantagate-and-bad-writing
This is a reasonable take. One can at best make statistical claims on such n-gram analysis.
For those who don't know, infini-gram is a really cool N-gram search engine that works impressively fast over massive datasets Just because there is an N-gram match doesn't necessarily mean an LLM "plagiarized" from the given work, but there is a reasonable chance that the given document was in the pretraining set of the LLM and influenced the weights towards producing that N-gram. What is most interesting to me are actually the 115 N-grams found nowhere else on the internet. Maybe that's some sign that it's from the prompt or context. Or maybe even just a token getting randomly sampled. I'd love to see some more comparisons on human text as well. Waybe there is a major difference here in N-gram similarity for human and AI text, but we won't know until we try it!
Since this post has blown up.
1) The research is based on two papers
https://arxiv.org/pdf/2410.04265 https://arxiv.org/pdf/2504.07096
2) When writing about the matches I focused on webpages that are not defunct and fan fiction results were especially relevant to AI fiction but some phrases can be in other websites too. That does not change the point about genre mismatch or stitching rare expressions
3) The attribution engine is built using CommonCrawl that LLMs have been trained on. So it might not catch all the possible webpages that might have that expression
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction. https://tuhinchakrabarty.substack.com/p/ai-slop-grantagate-and-bad-writing
A reader told me
cane and forgetting ->
cane ( as in sugarcane from Trinidad) cane -> rum rum -> drinking drinking -> forgetting
🤯🤯🤯
One thing from @TuhinChakr post hits very close home, people tend to #rationalize (bc we don't know better) and see things not there. We saw it already in GPT-2 generated stories -- we *expect* things to *mean* something so we tend to see things that are not there...
@alexolegimas Thank you 🥹
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction. https://tuhinchakrabarty.substack.com/p/ai-slop-grantagate-and-bad-writing
@natolambert @alexolegimas @liujc1998 @natolambert fyi i am not stealing any credit. I have already attributed it to infinigram in the substack as well as mentioned creativity index and olmo trace several times on X after :)
@alexolegimas @TuhinChakr Built on an ai2 project led by @liujc1998 !!!
This from @TuhinChakr is brilliant. That prize winning story from Granta? Turns out it's just a bunch of random whole phrases taken directly from existing text on the internet. Tool allows you to trace those n-grams directly to their source, which is mostly random fanfiction.