Modal publishes breakdown of serverless GPU infrastructure
Modal published a technical breakdown of its infrastructure for serverless GPU execution of AI inference workloads. The system reduces replica startup times from multiple kiloseconds to tens of seconds via process checkpointing and three other integrated components. These methods support rapid scaling on accelerators such as the B200 for variable inference demand and billion-parameter models, prioritizing GPU utilization over steady training workloads.
Step 3 to achieve truly serverless GPUs for AI inference: skip over application setup work by saving processes to storage and then reloading them instead of re-executing them.

A Linux process is a data structure. If you can serialize that data structure, you can often send and deserialize the data faster than you can recreate it.

Step 3 to achieve truly serverless GPUs for AI inference: skip over application setup work by saving processes to storage and then reloading them instead of re-executing them.
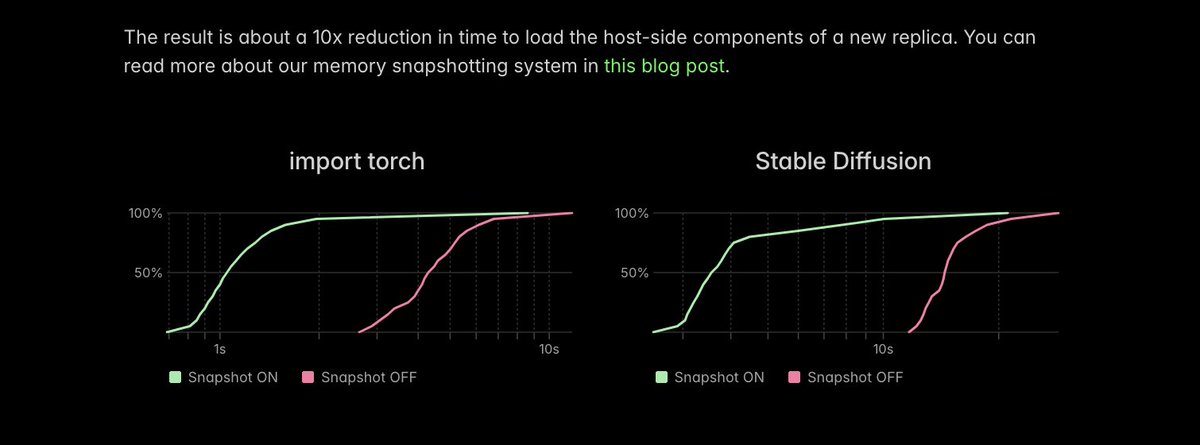
One big perf win: importing torch requires a metric fuckton of serial syscalls from Python. Checkpoint/restore turns this into one big load -- which @modal can complete 10x faster.
We use gVisor as our container runtime, so the Linux processes are running in an emulated kernel. It comes with built-in features for this "checkpoint/restore" workflow, very cleanly supported thanks to Go's clean cooperative multitasking architecture.
Learn more about this "memory snapshotting" approach, and other ways to boot AI inference servers faster, on our blog:
One big perf win: importing torch requires a metric fuckton of serial syscalls from Python. Checkpoint/restore turns this into one big load -- which @modal can complete 10x faster.
"feels like David Blaine showing us how he does his magic tricks"
