Cameron R. Wolfe publishes "Agent Evaluation: A Detailed Guide" covering agent fundamentals, multi-agent systems, evaluation patterns, and benchmarks including Tau-Bench and Terminal-Bench
Lei Li links to related analysis on agents as model plus harness.
I just published a detailed guide on evaluating agents. It covers:
1. Agent fundamentals (everything from basic concepts to complex ideas like multi-agent systems). 2. Common evaluation patterns / frameworks observed in practice. 3. Case studies of popular agent benchmarks (e.g., Tau-Bench and Terminal-Bench series).
Building high-quality evaluation capabilities is now more important than ever due to the growing adoption of agents in high-stakes applications like coding and medicine. Although evaluation is time-consuming and difficult, learning how to properly evaluate agents is incredibly valuable. Rigorously measuring performance and not relying on anecdotal checks allows us to rapidly improve agent capabilities.
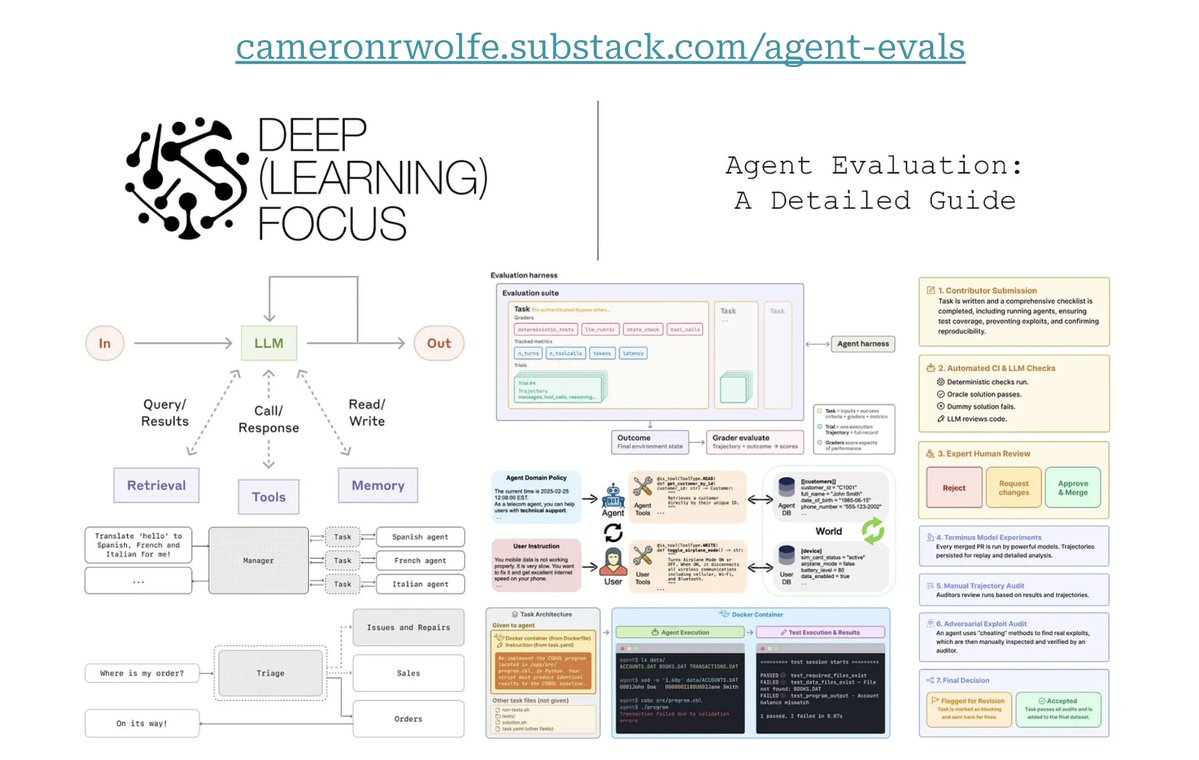
Read it here: https://cameronrwolfe.substack.com/p/agent-evals
I just published a detailed guide on evaluating agents. It covers: 1. Agent fundamentals (everything from basic concepts to complex ideas like multi-agent systems). 2. Common evaluation patterns / frameworks observed in practice. 3. Case studies of popular agent benchmarks (e.g., Tau-Bench and Terminal-Bench series). Building high-quality evaluation capabilities is now more important than ever due to the growing adoption of agents in high-stakes applications like coding and medicine. Although evaluation is time-consuming and difficult, learning how to properly evaluate agents is incredibly valuable. Rigorously measuring performance and not relying on anecdotal checks allows us to rapidly improve agent capabilities.