T3 Stack creator Theo Browne reports that Opus 4.8 is cheaper but slightly less accurate than Opus 4.7 on CursorBench 3.1
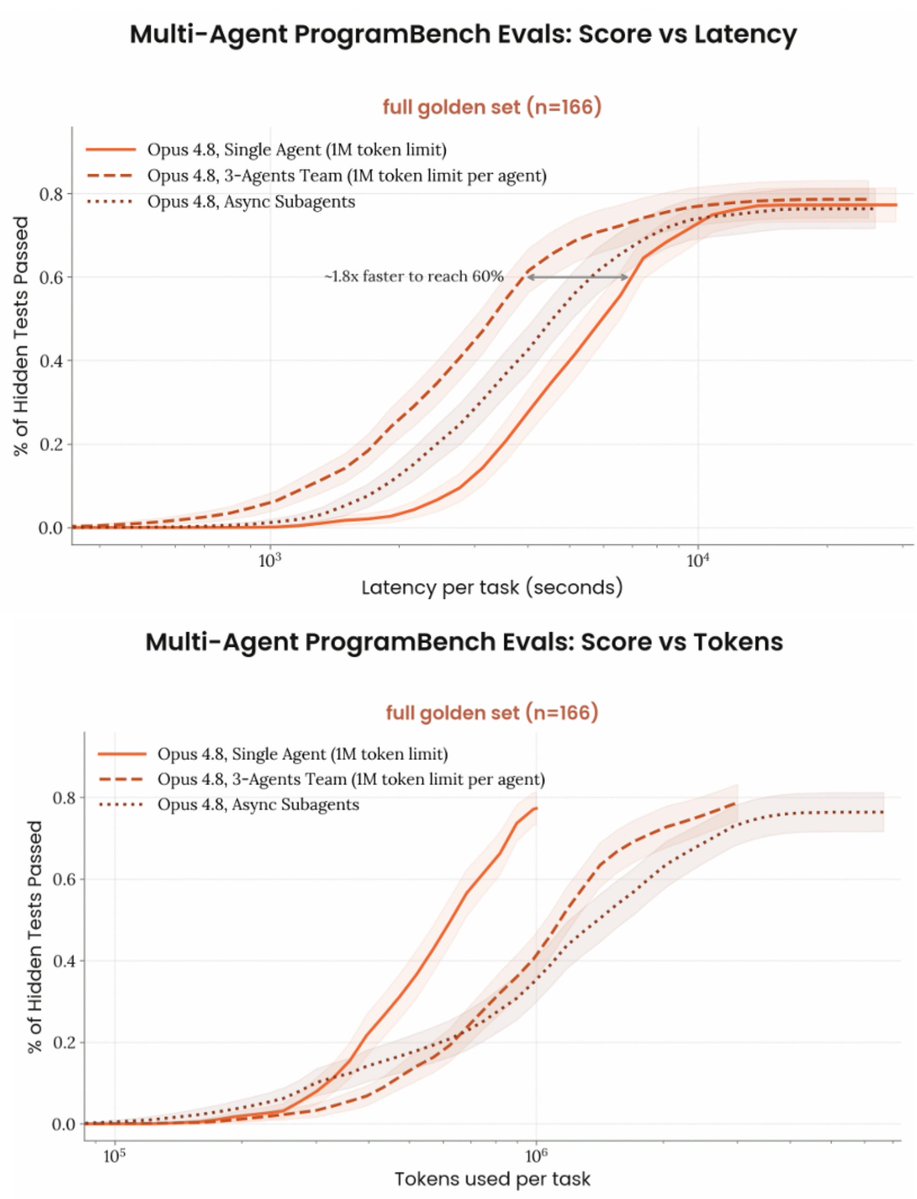
Multi-agent teams speed up Opus 4.8 workflows by 1.8x
subagents, teams of agents etc. will be first class citizens soon (if not already)
two things here: 1) you want to maximize token efficiency even more 2) training/serving on your own harness gives you an even bigger boost than before
benchmarks in the opus 4.8 model card show that for now it's a latency vs cost tradeoff, but imo this will likely shift to intelligence/autonomy vs cost (think dynamic workflows or agent swarms). and for cost not to blow up too much, you need to maximize token efficiency even more
we'll also likely see huge gaps on more complex/autonomous benchmarks whether they use these features or not, a bit like when tool use was introduced. on those i'd expect third party harnesses to struggle to keep up with closed source models/harnesses
this is also a case for open source models (and maybe open harnesses like codex?). if you want deep control over this, doing your own RL to train the model in the environment you want it to operate in feels more important than ever
Cursor has updated CursorBench with Opus 4.8. It is more efficient, but performs slightly worse than Opus 4.7 within margin of error.
subagents, teams of agents etc. will be first class citizens soon (if not already for some)
two things here: 1) you want to maximize token efficiency even more 2) training/serving on your own harness gives you an even bigger boost than before
benchmarks in the opus 4.8 model card show that for now it's a latency vs cost tradeoff, but imo this will likely shift to intelligence/autonomy vs cost (think dynamic workflows or agent swarms). and for cost not to blow up too much, you need to maximize token efficiency even more
we'll also likely see huge gaps on more complex/autonomous benchmarks whether they use these features or not, a bit like when tool use was introduced. on those i'd expect third party harnesses to struggle to keep up with closed source models/harnesses
this is also a case for open source models (and maybe open harnesses like codex?). if you want deep control over this, doing your own RL to train the model in the environment you want it to operate in feels more important than ever
Cursor has updated CursorBench with Opus 4.8. It is more efficient, but performs slightly worse than Opus 4.7 within margin of error.