Ring Ling model totals 63 billion active parameters
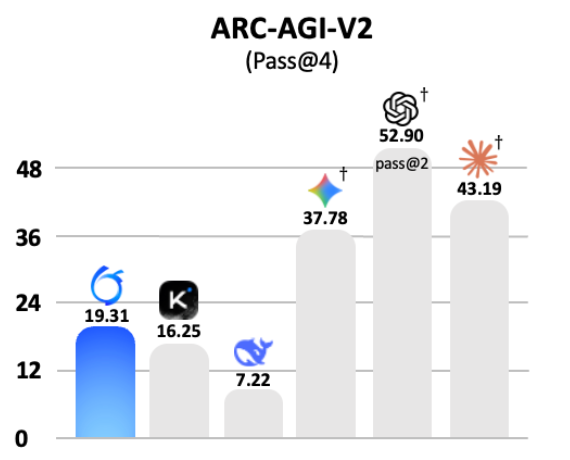
The Ring Ling model, also called Ring-2.6-1T, contains 63 billion active parameters and more than 30 trillion total parameters. The scale exceeds V4 and ranks it among the largest Chinese systems, behind only Baidu's Ernie 5.0 and Qwen-Max. Related Ring 2.5 versions record near 66 percent on the public ARC-AGI benchmark, with private performance estimated near 30 percent and ARC-AGI-V2 Pass@4 scores including 19.31, 16.25, 7.22, 37.78, 52.90, and 43.19.
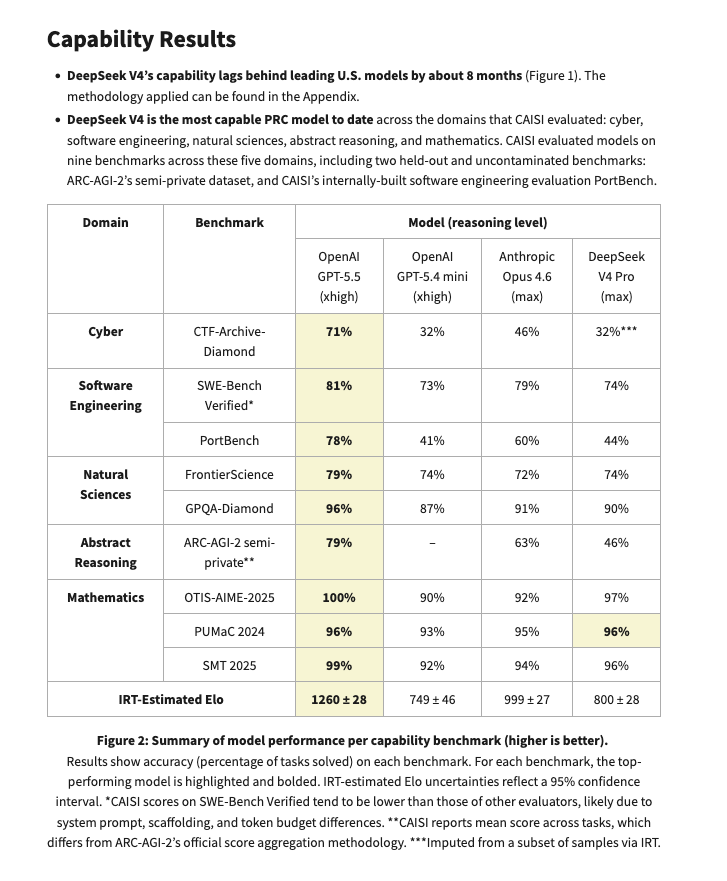
This is very frustrating, we have non-comparable datapoints (CAISI's ARC-AGI-2 for DSV4 vs the lb for others, public vs semi-private set, pass@4 vs @2…) But I think it plausible that current gen PRC open models score 50ish on proper ARC-AGI-V2, up from 4-12% of late 2025 ones.
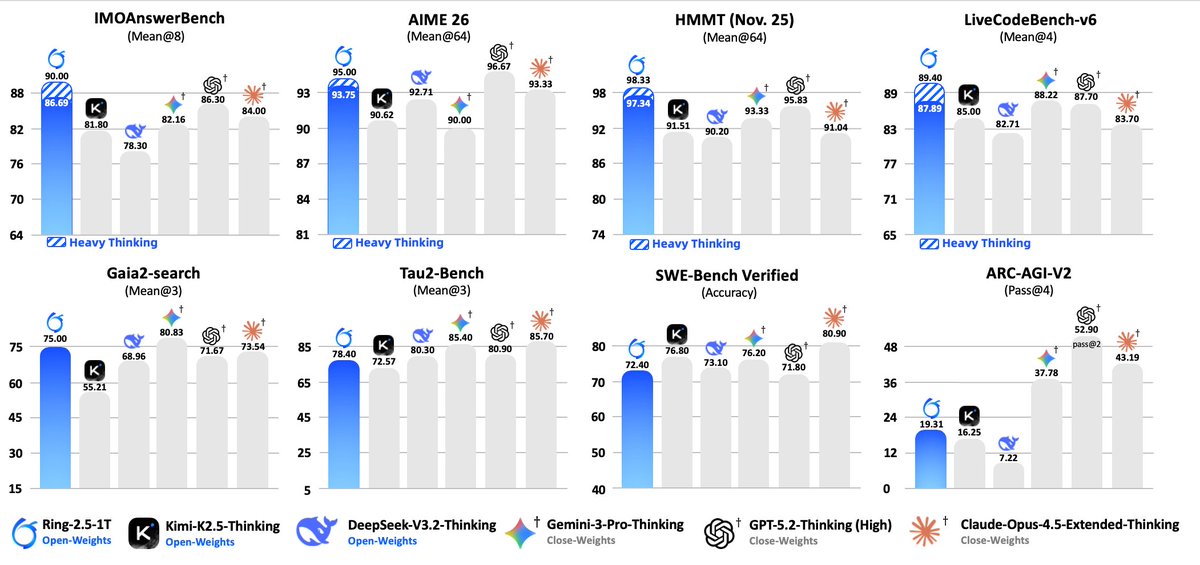

@teortaxesTex i wouldn't get too hyped about this score this was Ring 2.5: They are very likely not scoring anywhere near 66% on the private eval. the private eval is probably closer to 30%
If that is true, this is pretty big because it'd mean they've recovered this performance without exponentially more spending. I think V4-Pro is only like 3x of V3.2 in compute costs. Kimi K2.6 is an updated K2.5. ARC-AGI-2 would be a matter of pure post-training.
This is very frustrating, we have non-comparable datapoints (CAISI's ARC-AGI-2 for DSV4 vs the lb for others, public vs semi-private set, pass@4 vs @2…) But I think it plausible that current gen PRC open models score 50ish on proper ARC-AGI-V2, up from 4-12% of late 2025 ones.
data, data, data, data Ring 2.6 1T hallucinates so hard that DeepSeekV4-Flash (fitting into 160 Gb and notoriously flimsy on AA-Omniscience) looks frontier next to it. But muh agent workflows… you don't need 1T params (63B active) for that. Scale is for knowledge. Try again.

also, bruh what happened here? Why are files all over the place


data, data, data, data Ring 2.6 1T hallucinates so hard that DeepSeekV4-Flash (fitting into 160 Gb and notoriously flimsy on AA-Omniscience) looks frontier next to it. But muh agent workflows… you don't need 1T params (63B active) for that. Scale is for knowledge. Try again.
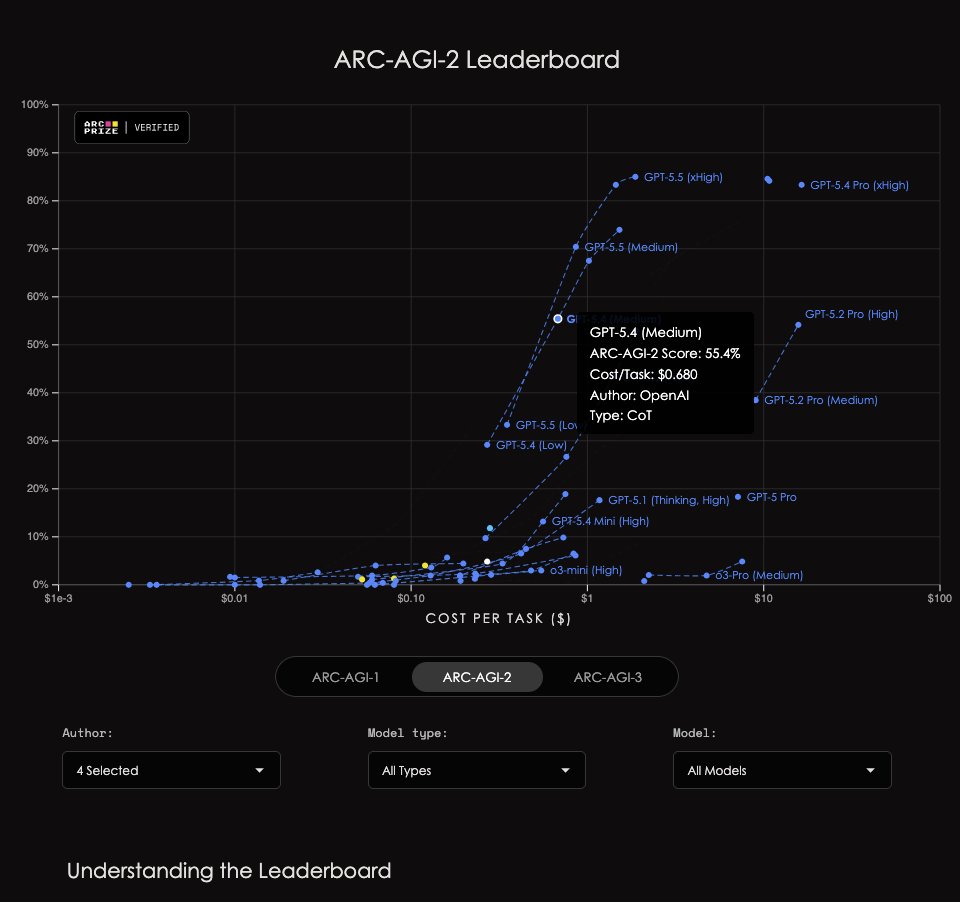
…wut? "based on internal evaluations from the public set" You can't just drop this without giving public eval figures for frontier models! Those are their semi-private ARC-AGI 2 scores! @scaling01 look here
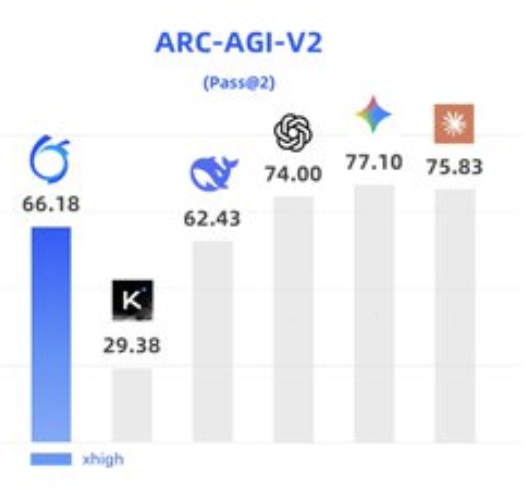
I remind you that except for Baidu's Ernie 5.0 and Qwen-Max, Ring/Ling is as far as we can tell the most compute-intensive Chinese model. 63B active, >30T total. It's bigger than V4.
…wut? "based on internal evaluations from the public set" You can't just drop this without giving public eval figures for frontier models! Those are their semi-private ARC-AGI 2 scores! @scaling01 look here
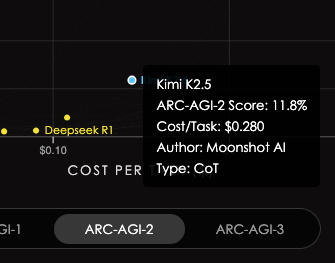
@scaling01 that's pass@4. Official semi-private leaderboard is pass@2, there Kimi K2.5 gets 11.8% with DSV3.2 4.0%. I don't have a good intuition about pass@k scaling factors here, but looks plausible that the discounting is not as much as you say.
@teortaxesTex i wouldn't get too hyped about this score this was Ring 2.5: They are very likely not scoring anywhere near 66% on the private eval. the private eval is probably closer to 30%
@teortaxesTex i wouldn't get too hyped about this score this was Ring 2.5:
They are very likely not scoring anywhere near 66% on the private eval.
the private eval is probably closer to 30%
…wut? "based on internal evaluations from the public set" You can't just drop this without giving public eval figures for frontier models! Those are their semi-private ARC-AGI 2 scores! @scaling01 look here