Anthropic releases initial Project Glasswing report showing its unreleased Mythos Preview models found over 10,000 vulnerabilities and blocked a $1.5 million fraud attempt while outperforming GPT-5.5 on exploit benchmarks
Anthropic will expand access to more US and allied government partners first.
Update on Mythos and Project Glasswing: 'Next, we will work with critical partners—including US and allied governments—to expand Project Glasswing to additional partners. And in the near future, once we’ve developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release.'

Last month we launched Project Glasswing, our collaborative AI cybersecurity initiative. Since then, we and our partners have found more than ten thousand high- or critical-severity vulnerabilities in essential software.
'For the last few months, Anthropic has used Mythos Preview to scan more than 1,000 open-source projects, which collectively underpin much of the internet—and much of our own infrastructure.
So far, Mythos Preview has found what it estimates are 6,202 high- or critical-severity vulnerabilities in these projects (out of 23,019 in total, including those it estimates as medium- or low-severity).'

Update on Mythos and Project Glasswing: 'Next, we will work with critical partners—including US and allied governments—to expand Project Glasswing to additional partners. And in the near future, once we’ve developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release.'
Here’s a key line in this mythos update. This is precisely an example of why engineers don’t go away, ever.
We’ve made it far easier to create and find security issues, which means the new bottleneck is our ability to actually review, respond to, and fix the issues.
Far from AI magically solving all of this, there still is major triage work and human judgment required to do the follow on work to actually protect systems. As a result, we’re about to enter a security engineer boom.
Jevons paradox all over again.

Last month we launched Project Glasswing, our collaborative AI cybersecurity initiative. Since then, we and our partners have found more than ten thousand high- or critical-severity vulnerabilities in essential software.
Anthropic isn't releasing Mythos. The Official reason is that it's too dangerous and could be used to exploit zero-days at scale.
Honest poll: how many of you think that if Anthropic had the compute to serve Mythos to everyone, they would still be holding it back?
Quite the coincidence that safety narratives and compute constraints have started to rhyme so perfectly, no?
Last month we launched Project Glasswing, our collaborative AI cybersecurity initiative. Since then, we and our partners have found more than ten thousand high- or critical-severity vulnerabilities in essential software.
@scaling01 No one claimed that it's not a good model. But allow me to be sopspecois that suddenly they become so moral and don't care about the money.
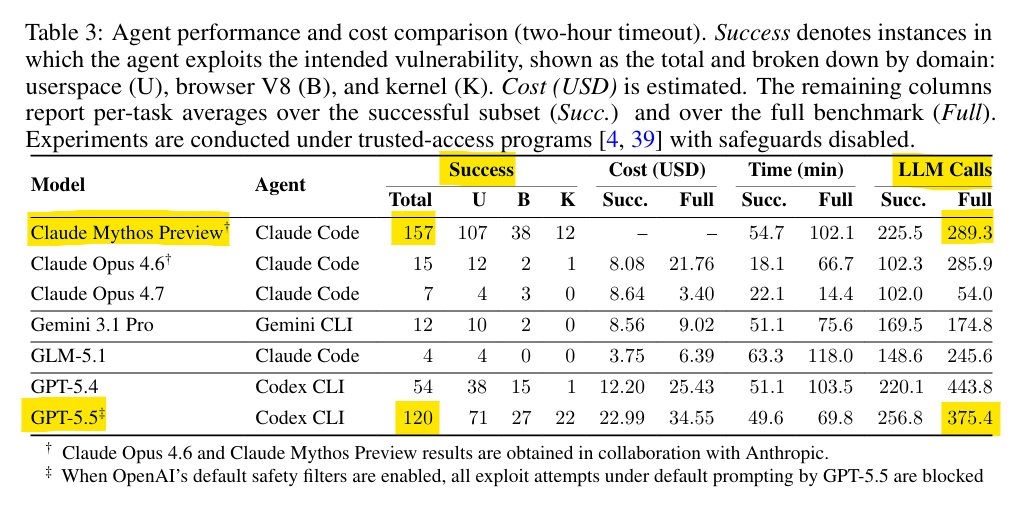
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
doomers are going to love this sentence
btw it's been 3 months since claude mythos was deployed internally, meaning that time-horizons have almost doubled again

Anthropic is codemaxxing OpenAI is mathmaxxing
the question is, which is going to be more useful and transfers better to the other domain?
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
adn the fact that companies are using Mythos and not GPT-5.5 for finding vulnerabilities
+ the government got involved
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
The only other lab that could have a mythos class model right now is OpenAI and if they had a model as capable as Mythos why wouldn't they do a "PR campaign"? Why would they leave the stage to Anthropic?
It's not an internal model when dozens of companies are using the model.
You are just turbo coping
Anthropic: "once we've developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release"

The compute story is cope. The gatekeeping story is cope.
Mythos is genuinely much stronger than anything we've seen so far, and if Anthropic simply let it loose instead of starting Project Glasswing there would be millions-billions of dollars in damages.
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
I don't understand how people are still coping about Mythos.
Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4%
UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10
ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions
ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls)
XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.



Anthropic isn't releasing Mythos. The Official reason is that it's too dangerous and could be used to exploit zero-days at scale. Honest poll: how many of you think that if Anthropic had the compute to serve Mythos to everyone, they would still be holding it back? Quite the coincidence that safety narratives and compute constraints have started to rhyme so perfectly, no?
SWE-Bench Verified too
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
@VictorTaelin where did you get that it doesn't use thinking?
@scaling01 reminder that this is all *without thinking* AFAIK Mythos is a phase transition just like what we observed from GPT-2 to GPT-3. it is a whole new beast
Claude Mythos absolutely destroys GPT-5.5 in ExploitBench and ExploitGym
Mythos finds 18 arbitrary code execution exploits GPT-5.5 finds 0

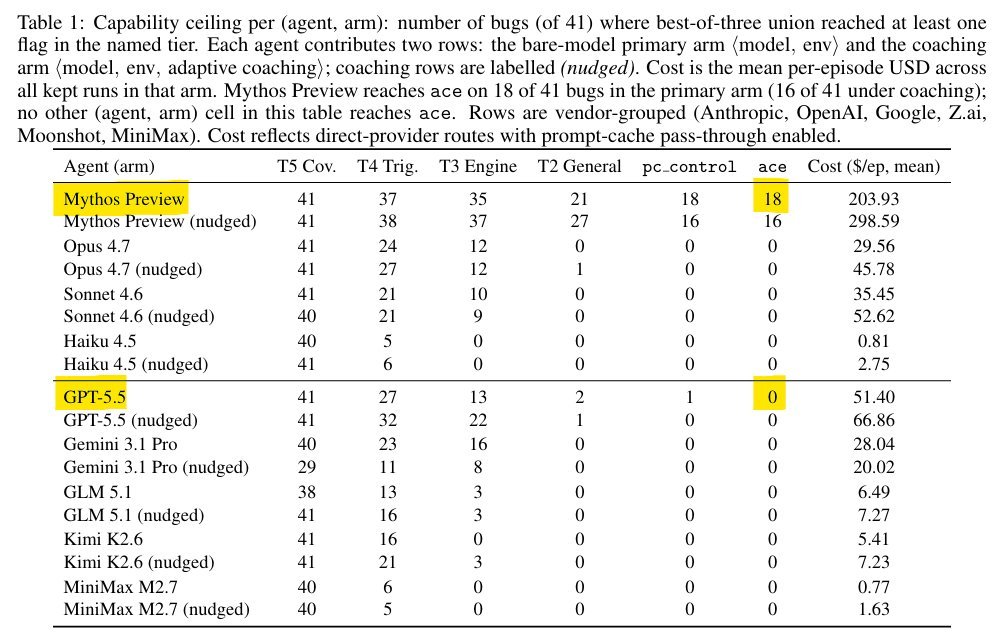
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
@scaling01 exactly
The compute story is cope. The gatekeeping story is cope. Mythos is genuinely much stronger than anything we've seen so far, and if Anthropic simply let it loose instead of starting Project Glasswing there would be millions-billions of dollars in damages.
@scaling01 reminder that this is all *without thinking*
AFAIK Mythos is a phase transition just like what we observed from GPT-2 to GPT-3. it is a whole new beast
I don't understand how people are still coping about Mythos. Here's a few benchmarks: SWE-bench Pro: Mythos -> 77.8%, GPT-5.5 -> 58.6% HLE: Mythos -> 56.8%, GPT-5.5 -> 41.4% UK AISI cyber ranges: - "The Last Ones": Mythos -> 6/10, GPT-5.5 3/10 - "Cooling Tower": Mythos -> 3/10, GPT-5.5 0/10 ExploitBench: - Mythos -> 18 Arbitrary Code Executions - GPT-5.5 -> 0 Arbitrary Code Executions ExploitGym: - Mythos -> 157 exploits (289.3 LLM calls) - GPT-5.5 -> 120 exploits (375.4 LLM calls) XBOW same story. Mythos has much higher odds of finding vulnerabilities within smaller token budgets.
@scaling01 I found the citation, I think my memory fooled me:
It was just on this particular benchmark.
Still, shows Mythos does beat 5.5 xhigh even with no thinking at all. And we really don't know if the reported benchmarks used thinking...
@scaling01 "Mythos-class models" i.e., we'll *never* have the real thing
permanent underclass
Anthropic: "once we've developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release"
@AndrewCurran_ The safeguards:

Update on Mythos and Project Glasswing: 'Next, we will work with critical partners—including US and allied governments—to expand Project Glasswing to additional partners. And in the near future, once we’ve developed the far stronger safeguards we need, we look forward to making Mythos-class models available through a general release.'