Researchers introduce Simulation Distillation to pretrain world models in simulation for rapid adaptation in real-world robotic reinforcement learning
Method targets long-horizon contact-rich tasks via arXiv paper.
Punchline: distill world models from simulation to enable fast, stable real-world robot adaptation.
Simulation is nearly always wrong. But in Simulation Distillation, we ask a simple question:
How do we perform simulation pretraining such that real-world adaptation becomes trivially easy?
Let's take a closer look (1/n)

Real-world RL is still pretty hard for long-horizon, contact-rich robotics. A few minutes of robot data is not enough to relearn rewards, values, representations, dynamics, and action selection end-to-end.
And when we try, finetuning can destroy useful structure learned during pretraining. (2/n)

Punchline: distill world models from simulation to enable fast, stable real-world robot adaptation. Simulation is nearly always wrong. But in Simulation Distillation, we ask a simple question: How do we perform simulation pretraining such that real-world adaptation becomes trivially easy? http://sim-dist.github.io Let's take a closer look (1/n)
The key idea in SimDist is simple:
Move the hard RL problem into simulation, and transfer a high-coverage latent world model rather than only a policy.
In simulation, we can train this model with privileged state, dense rewards, value functions, resets, perturbations, failures, and recoveries at scale. (3/n)

Real-world RL is still pretty hard for long-horizon, contact-rich robotics. A few minutes of robot data is not enough to relearn rewards, values, representations, dynamics, and action selection end-to-end. And when we try, finetuning can destroy useful structure learned during pretraining. (2/n)
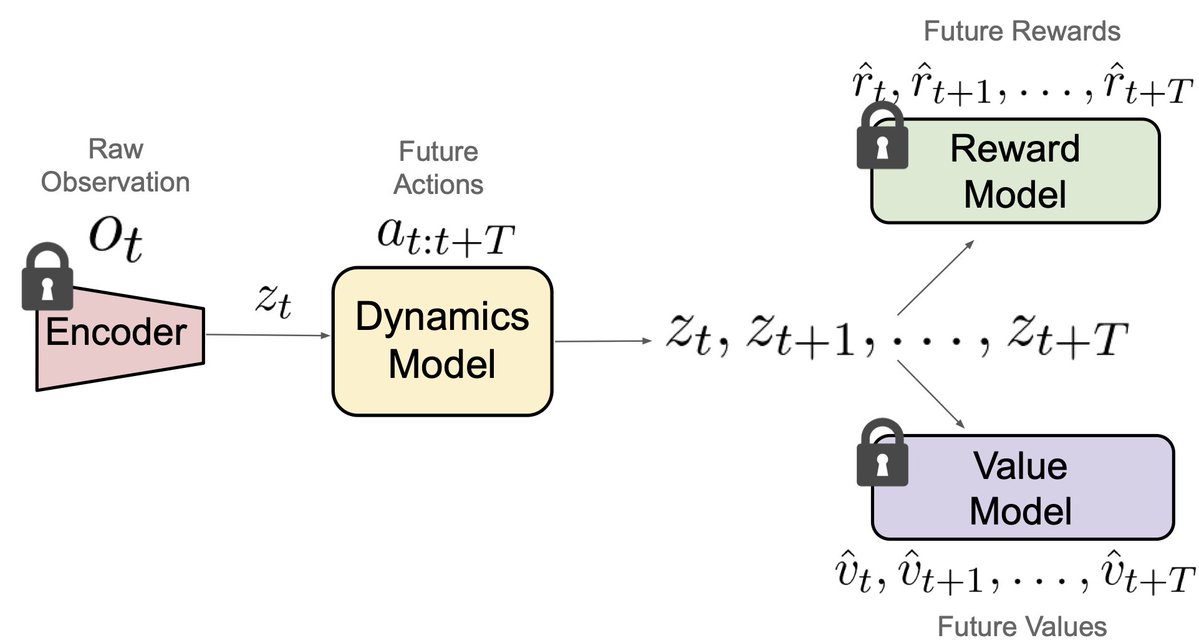
At deployment, we can then freeze the parts that encode task structure — the encoder, reward model, and value function — and only adapt the latent dynamics model where the simulation imperfections lie. Performance is then naturally improved, just by performing short-horizon planning in this adapted model.
So real-world adaptation becomes literally short-horizon supervised learning than long-horizon RL from scratch. (4/n)

The key idea in SimDist is simple: Move the hard RL problem into simulation, and transfer a high-coverage latent world model rather than only a policy. In simulation, we can train this model with privileged state, dense rewards, value functions, resets, perturbations, failures, and recoveries at scale. (3/n)
This is especially important for contact-rich tasks. The value function may already know that “peg aligned with hole” or “leg has stable foothold” is good, capturing the global structure of the task solution. What changes in the real world is often the details of local dynamics: friction, compliance, slip, contact, calibration. SimDist adapts exactly this part using real world data. (5/n)

At deployment, we can then freeze the parts that encode task structure — the encoder, reward model, and value function — and only adapt the latent dynamics model where the simulation imperfections lie. Performance is then naturally improved, just by performing short-horizon planning in this adapted model. So real-world adaptation becomes literally short-horizon supervised learning than long-horizon RL from scratch. (4/n)
Visualizing the value function is useful here, it transfers quite well and capture successes and failures as well as the orderings of which state is best. Importantly, this value function is trained with high-coverage, so only local repair of dynamics is needed - no OOD extrapolation errors! (6/n)

This is especially important for contact-rich tasks. The value function may already know that “peg aligned with hole” or “leg has stable foothold” is good, capturing the global structure of the task solution. What changes in the real world is often the details of local dynamics: friction, compliance, slip, contact, calibration. SimDist adapts exactly this part using real world data. (5/n)
One detail that matters during pre-training: Simulation data should not only contain successful expert trajectories. A planner asks counterfactual questions at test time: What if I push here? What if I slip? So the world model needs failures, perturbations, and recoveries too.
This is where simulation is super useful. We can cheaply generate the messy off-policy experience that would be painful or unsafe to collect on real robots, then distill it into a model that supports real-world planning and rapid adaptation. (7/n)

Visualizing the value function is useful here, it transfers quite well and capture successes and failures as well as the orderings of which state is best. Importantly, this value function is trained with high-coverage, so only local repair of dynamics is needed - no OOD extrapolation errors! (6/n)
The perspective I find useful: Simulation gives broad structure and coverage, real-world data fixes the local details. SimDist reduces adaptation to just what needs to change, while avoiding many of the extrapolation and instability issues that appear in offline-to-online RL finetuning. (9/n)

Across precise manipulation and quadruped locomotion, SimDist adapts from just 15-30 min of real-world data by planning with transferred reward/value structure and finetuning only dynamics. The adaptation is stable because it is supervised learning, rather than online RL over the full policy/value/reward stack. (8/n)
Across precise manipulation and quadruped locomotion, SimDist adapts from just 15-30 min of real-world data by planning with transferred reward/value structure and finetuning only dynamics.
The adaptation is stable because it is supervised learning, rather than online RL over the full policy/value/reward stack. (8/n)


One detail that matters during pre-training: Simulation data should not only contain successful expert trajectories. A planner asks counterfactual questions at test time: What if I push here? What if I slip? So the world model needs failures, perturbations, and recoveries too. This is where simulation is super useful. We can cheaply generate the messy off-policy experience that would be painful or unsafe to collect on real robots, then distill it into a model that supports real-world planning and rapid adaptation. (7/n)
Big kudos to Jacob Levy and @ty_westenbroek for leading this, along with Kevin Huang, Fernando Palafox, @patrickhyin , Dong-Ki Kim, Shayegan Omidshafiei, and David Fridovich-Keil.
They also made a fantastic website to help understand the work, where you can play with model behavior and performance:
Website: http://sim-dist.github.io Paper: https://arxiv.org/abs/2603.15759
See you at RSS 2026 to talk more about this work! (10/n)
The perspective I find useful: Simulation gives broad structure and coverage, real-world data fixes the local details. SimDist reduces adaptation to just what needs to change, while avoiding many of the extrapolation and instability issues that appear in offline-to-online RL finetuning. (9/n)
Special note to highlight that @ty_westenbroek is on the job market for research scientist roles! Hire him, he does fantastic work :)
Big kudos to Jacob Levy and @ty_westenbroek for leading this, along with Kevin Huang, Fernando Palafox, @patrickhyin , Dong-Ki Kim, Shayegan Omidshafiei, and David Fridovich-Keil. They also made a fantastic website to help understand the work, where you can play with model behavior and performance: Website: http://sim-dist.github.io Paper: https://arxiv.org/abs/2603.15759 See you at RSS 2026 to talk more about this work! (10/n)
@ty_westenbroek Sim2real 🤝 World Models 🤝 RL, we have all the buzzwords! 🎉🎉🎉🥳
Special note to highlight that @ty_westenbroek is on the job market for research scientist roles! Hire him, he does fantastic work :)
@Vikashplus Currently with a known task distribution, since it needs to get the VFs in simulation. But would be fun to get rid of that requirement :)
@abhishekunique7 Do we need to know the task distribution, or can it be trained agnostic to the distribution ahead of times?
@abhishekunique7 Do we need to know the task distribution, or can it be trained agnostic to the distribution ahead of times?
Punchline: distill world models from simulation to enable fast, stable real-world robot adaptation. Simulation is nearly always wrong. But in Simulation Distillation, we ask a simple question: How do we perform simulation pretraining such that real-world adaptation becomes trivially easy? http://sim-dist.github.io Let's take a closer look (1/n)
the shortest path to general robotics could be leveraging learned world models to cross the sim2real gap
Real-world RL is still too brittle and data-hungry for long-horizon, contact-rich tasks. We introduce Simulation Distillation (SimDist), which turns large-scale simulated experience into reusable world-model priors for rapid real-world adaptation. By combining online planning with dynamics adaptation, SimDist achieves high success rates on tasks requiring precision, force, and reactivity. Play with our interactive visualization to see for yourself: https://sim-dist.github.io (1/n)