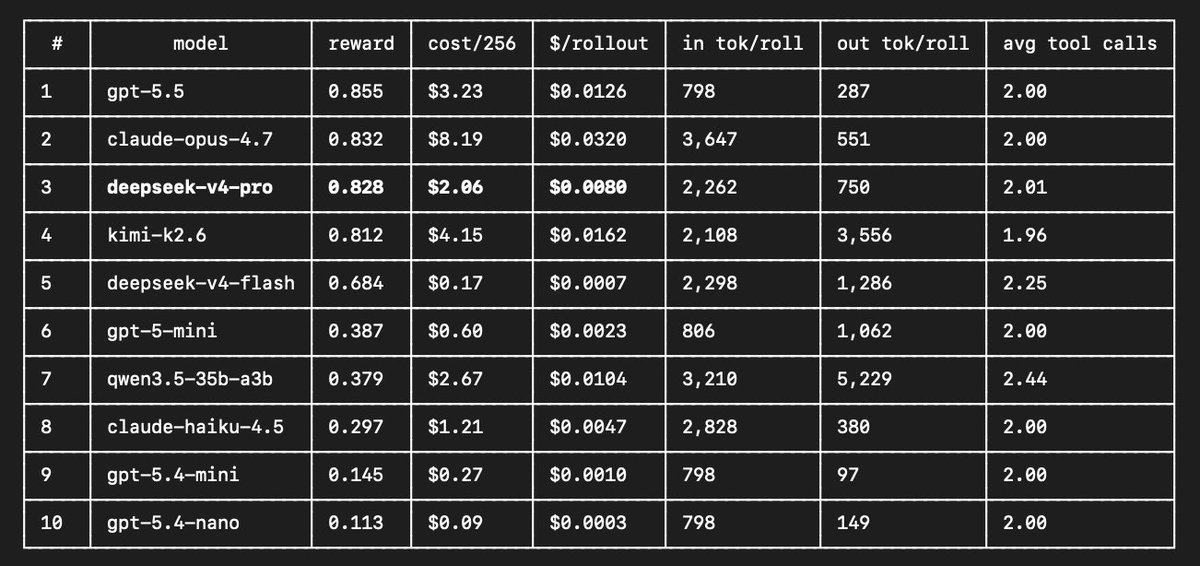
Prime Intellect's @kalomaze built an agent evaluation benchmark finding GPT-5.5 leads performance while DeepSeek v4-flash dominates cost efficiency
DeepSeek v4-flash cost just $0.0007 per rollout.
@kalomaze how's pro? It should be <3x as expensive and stronger
cc @teortaxesTex it's a fairly simple probe reverse engineered from my personal agent grievances... but MAN this chart is so funny [relevant task axis: "model's ability to realize when a local change requires exacting multihop global changes"]
@kalomaze interesting, this is one of the cases where Pro vs Flash are meaningfully differentiated then. What about cost?
@teortaxesTex seems to be within variance of the other True Frontier Models (important caveat: i deliberately scoped this to a short horizon problem shape where you can still notice dumber agents doing myopic shit)
V4-Flash is so good I'm worried whether they'll be able to push it even further in V4.1 (without doubling token costs at least)
cc @teortaxesTex it's a fairly simple probe reverse engineered from my personal agent grievances... but MAN this chart is so funny [relevant task axis: "model's ability to realize when a local change requires exacting multihop global changes"]
cc @teortaxesTex it's a fairly simple probe reverse engineered from my personal agent grievances... but MAN this chart is so funny [relevant task axis: "model's ability to realize when a local change requires exacting multihop global changes"]

lol i think i whipped up the simplest, dumbest agent env that a. (broadly) sorts the wheat from the chaff b. also shows you if a model has strong overthinking tendencies by default as is usual, v4 flash is busy paretomogging w.r.t the cost/quality frontier
@teortaxesTex Realizing a Change Has Nth Order Consequences Can't Be This G-Loaded!

cc @teortaxesTex it's a fairly simple probe reverse engineered from my personal agent grievances... but MAN this chart is so funny [relevant task axis: "model's ability to realize when a local change requires exacting multihop global changes"]
@teortaxesTex seems to be within variance of the other True Frontier Models (important caveat: i deliberately scoped this to a short horizon problem shape where you can still notice dumber agents doing myopic shit)

@kalomaze how's pro? It should be <3x as expensive and stronger
@teortaxesTex seemingly more token efficient & also better tool call discipline (should be exactly 2 avg in the best case, qwen here in particular had some outliers that spammed redundant writes)
@kalomaze interesting, this is one of the cases where Pro vs Flash are meaningfully differentiated then. What about cost?
@teortaxesTex 5.4 mini might look like a regression here but i think this is probably a "doesn't default to a reasonable reasoning effort level" situation no clue if nano even does reasoning to begin with?
@teortaxesTex seemingly more token efficient & also better tool call discipline (should be exactly 2 avg in the best case, qwen here in particular had some outliers that spammed redundant writes)
@teortaxesTex 5.4 mini might look like a regression here (chooses not to reason?) but i think this is probably a "doesn't default to a reasonable effort level" situation also; no clue if nano even does reasoning to begin with but i presume not lol?
@teortaxesTex seemingly more token efficient & also better tool call discipline (should be exactly 2 avg in the best case, qwen here in particular had some outliers that spammed redundant writes)