Dimitris Papailiopoulos from Microsoft Research shares ECHO method for training CLI agents with environment prediction loss
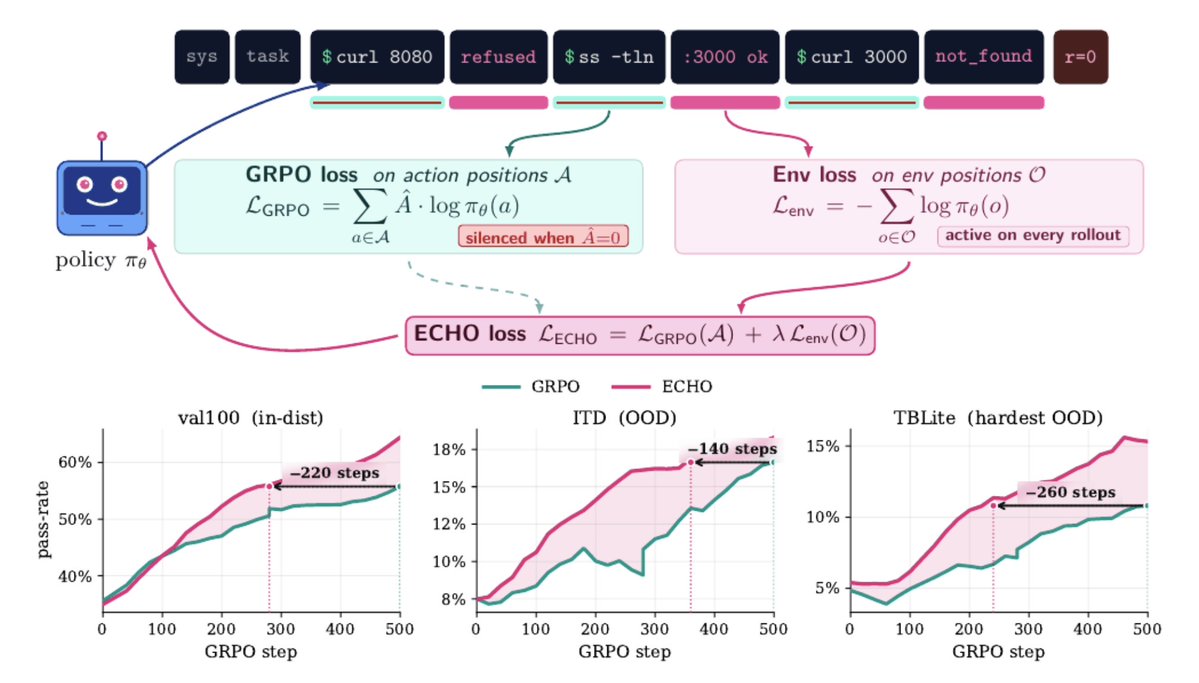
Dimitris Papailiopoulos from Microsoft Research AI Frontiers posted results on ECHO, which adds an environment prediction loss to standard GRPO training for command-line agents. The method trains on both agent actions and terminal responses in one rollout and forward pass instead of masking outputs. It delivers improved benchmark scores across Qwen3 models. Researcher John Langford noted that forecasting terminal command outputs accelerates reinforcement learning for agents operating in command-line environments.
@DimitrisPapail @ChengleiSi This is nice work, so sorry for distracting from the substance, but I'm genuinely curious:
> This work was done at AI Frontiers, a boutique research lab inside Microsoft Research.
What does "boutique research lab" mean here?
http://x.com/i/article/2056344151235387392
@NovaSkyAI here's a simple skyRL patch to train better CLI agents, for free
http://x.com/i/article/2056344151235387392
@giffmana @ChengleiSi A small group, of talented people, that are given free space to explore ideas that matter in the broader scope of AI, and specifically the area of computer use agents, but don't cost 1M to test :)
@DimitrisPapail @ChengleiSi This is nice work, so sorry for distracting from the substance, but I'm genuinely curious: > This work was done at AI Frontiers, a boutique research lab inside Microsoft Research. What does "boutique research lab" mean here?
@giffmana @ChengleiSi I came up with the phrasing, because it reminds me of how I'd describe with two words DM in its early days. One can only hope to come approximately close to that intellectual and technical space.
@giffmana @ChengleiSi A small group, of talented people, that are given free space to explore ideas that matter in the broader scope of AI, and specifically the area of computer use agents, but don't cost 1M to test :)
@giffmana @ChengleiSi also thanks for reading up to that part :D i know you have ton of cool stuff to work on today, so I'm grateful for your time.
@giffmana @ChengleiSi I came up with the phrasing, because it reminds me of how I'd describe with two words DM in its early days. One can only hope to come approximately close to that intellectual and technical space.
I'm just glad we did this before @lateinteraction and his amazing students :p
http://x.com/i/article/2056344151235387392
Turns out training your agent to be a world simulator improves its accuracy of solving problems
Internalizing world modeling as a native ability for agents.
Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models.
ECHO is one of those
http://x.com/i/article/2056344151235387392
Lol you can continual learn by training on terminal outputs WITHOUT REWARDS

http://x.com/i/article/2056344151235387392
Prediction: by end of 2026 Echo will be part of standard agent RL trainers.
FREE LUNCH FOR EVERYONE
http://x.com/i/article/2056344151235387392
World modeling. Faster RL. Self-improvement without verifiers.
All from one extra loss term on your favorite open-weights CLI agent.
Happy Monday!
http://x.com/i/article/2056344151235387392
@ChenhaoTan Thanks for checking out! I agree. You don't get too many of those in your career, so happy we stumbled upon it
Always a good sign that you are surprised that something has not been done before!
A fun result: training to predict terminal output significantly accelerates RL for terminal agents.
http://x.com/i/article/2056344151235387392
incredible Are we missing any other free, perfect, dense verifiers?
http://x.com/i/article/2056344151235387392
Always a good sign that you are surprised that something has not been done before!
http://x.com/i/article/2056344151235387392
How do machines build a mental map of reality? 🧠
Check out this frontier investigation into *world models* from our team at @ms_aifrontiers. Proud to see @DimitrisPapail and colleagues pushing the boundaries of how we think about AI reasoning.
World modeling. Faster RL. Self-improvement without verifiers. All from one extra loss term on your favorite open-weights CLI agent. Happy Monday!
@DimitrisPapail
World modeling. Faster RL. Self-improvement without verifiers. All from one extra loss term on your favorite open-weights CLI agent. Happy Monday!
Wonderful. The terminal is the world to an agent. It learns to model the world
Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models. ECHO is one of those