HRM-Text paper from Sapient Intelligence and MIT presents hierarchical recurrent pretraining that lets a 1B model trained on 40B tokens reach 60.7% MMLU, 84.5% GSM8K and other strong scores in one day of compute
A 0.6B TRM variant beats standard 3B-scale Transformers on downstream tasks.
Amazing work by @Sapient_Int showing the massive potential of smaller recursive models.
At the smallest scale (0.6B) their TRM variant achieves the best scores on downstream tasks and beats Transformers trained at the 3B scale.
The HRM-Text paper is now available 🎉 HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning. At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements. 1B parameters 40B unique tokens ~1 day of pretraining ~$1000 training cost
New HRM-Text paper featuring SYNTH as leading training source.

The HRM-Text paper is now available 🎉 HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning. At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements. 1B parameters 40B unique tokens ~1 day of pretraining ~$1000 training cost
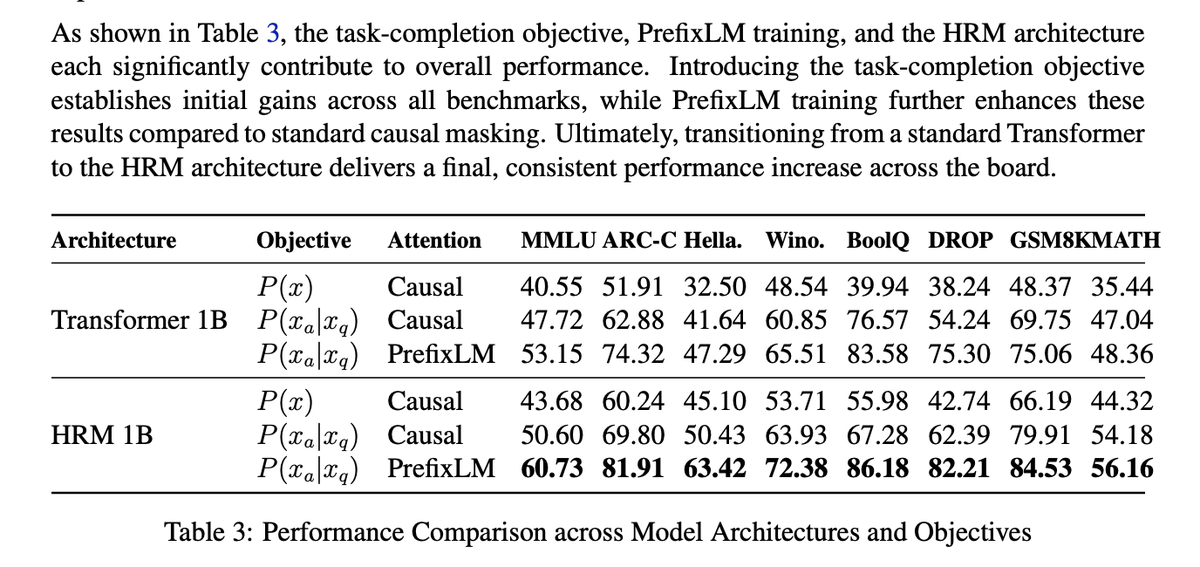
Also include architecture ablations. Genuine gains from the HRM side but data mix already leverages a high floor (MMLU at +50% on 40B tokens alone).
New HRM-Text paper featuring SYNTH as leading training source.