𝐋𝐨𝐧𝐠𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 ≠ 𝐛𝐞𝐭𝐭𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠. 𝐓𝐡𝐢𝐬 𝐛𝐫𝐞𝐚𝐤𝐬 𝐭𝐡𝐞 𝐬𝐜𝐚𝐥𝐢𝐧𝐠 𝐥𝐚𝐰. 𝐂𝐚𝐧 𝐰𝐞 𝐟𝐢𝐱 𝐢𝐭?
On given problems, CoT accuracy follows an inverted-U: It rises, peaks, then falls as the chain grows longer. Harder problems push the peak rightward, but the cliff is always there. Test-time scaling has a ceiling that few talk about.
So we asked: why does extra thinking hurt?
We measured pre-softmax attention from answer tokens back to the critical insights buried earlier in the chain: the small subset of sentences that actually determine the final answer. The decay is monotonic with distance. The longer the model reasons, the less access it has to the very conclusions that matter most. It's reasoning with a fading memory of its own best ideas.
This is the same problem sequence models have always faced. LSTMs solved it with an explicit memory cell that persists and updates as the sequence unfolds. The fix for long CoT should look the same.
That's what we built. We call it InsightReplay, stateful reasoning for CoT.
The reasoning state at any point is the cumulative set of insights the model has generated so far, compressed abstractions of prior reasoning. InsightReplay periodically extracts these insights and replays them near the active generation frontier, keeping them close to the decoding position so attention stays intact.
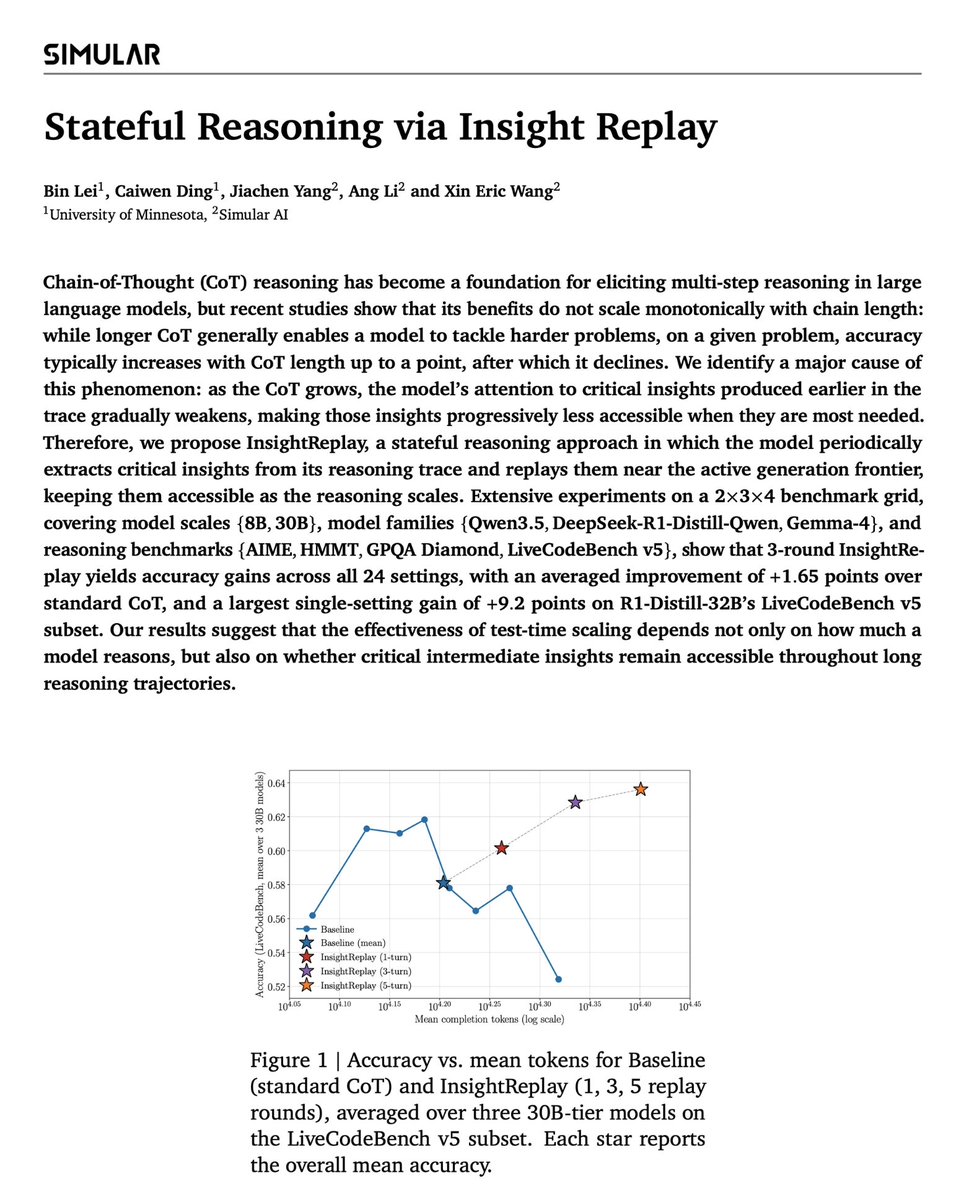
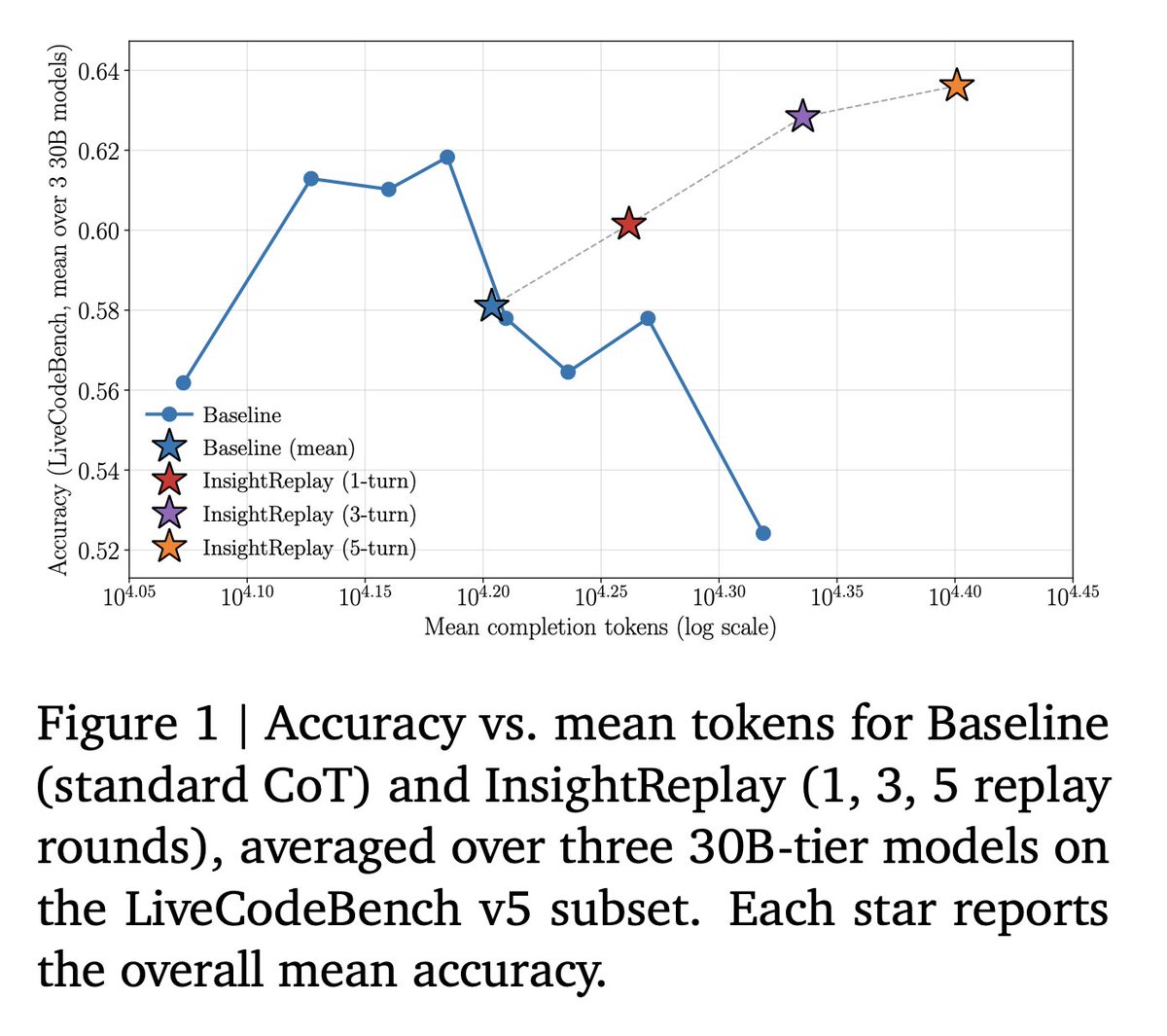
What happens when you do this: The baseline peaks around 15K tokens on LiveCodeBench and then degrades. InsightReplay operates precisely in that degradation regime. 1 replay round improves accuracy. 3 rounds exceeds the baseline's peak. 5 rounds keeps climbing.
The degradation regime becomes a continued-growth regime. 1 replay round improves accuracy. 3 rounds exceed the baseline's peak. 5 . 1 replay round improves accuracy. 3 rounds exceed the baseline's peak. 5 rounds keep climbing. → Critical insights and the surrounding trace are complementary — you need both → Attention to insights decays as CoT grows. This is the bottleneck → Replaying insights near the frontier shifts the optimal reasoning length rightward and raises the peak
Works at pure inference time across 30B-tier models. No training required. Post-training on this pattern improves both stability and performance over vanilla CoT.
Test-time scaling isn't just about reasoning longer. It's about keeping the right state accessible.
𝐋𝐨𝐧𝐠𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 ≠ 𝐛𝐞𝐭𝐭𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠. 𝐓𝐡𝐢𝐬 𝐛𝐫𝐞𝐚𝐤𝐬 𝐭𝐡𝐞 𝐬𝐜𝐚𝐥𝐢𝐧𝐠 𝐥𝐚𝐰. 𝐂𝐚𝐧 𝐰𝐞 𝐟𝐢𝐱 𝐢𝐭?
On given problems, CoT accuracy follows an inverted-U: It rises, peaks, then falls as the chain grows longer. Harder problems push the peak rightward, but the cliff is always there. Test-time scaling has a ceiling that few talk about.
So we asked: why does extra thinking hurt?
We measured pre-softmax attention from answer tokens back to the critical insights buried earlier in the chain: the small subset of sentences that actually determine the final answer. The decay is monotonic with distance. The longer the model reasons, the less access it has to the very conclusions that matter most. It's reasoning with a fading memory of its own best ideas.
This is the same problem sequence models have always faced. LSTMs solved it with an explicit memory cell that persists and updates as the sequence unfolds. The fix for long CoT should look the same.
𝐓𝐡𝐚𝐭'𝐬 𝐰𝐡𝐚𝐭 𝐰𝐞 𝐛𝐮𝐢𝐥𝐭. 𝐖𝐞 𝐜𝐚𝐥𝐥 𝐢𝐭 𝐈𝐧𝐬𝐢𝐠𝐡𝐭𝐑𝐞𝐩𝐥𝐚𝐲, 𝐬𝐭𝐚𝐭𝐞𝐟𝐮𝐥 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐟𝐨𝐫 𝐂𝐨𝐓.
The reasoning state at any point is the cumulative set of insights the model has generated so far, compressed abstractions of prior reasoning. InsightReplay periodically extracts these insights and replays them near the active generation frontier, keeping them close to the decoding position so attention stays intact.
What happens when you do this: The baseline peaks around 15K tokens on LiveCodeBench and then degrades. InsightReplay operates precisely in that degradation regime. 1 replay round improves accuracy. 3 rounds exceeds the baseline's peak. 5 rounds keeps climbing.
The degradation regime becomes a continued-growth regime. → Critical insights and the surrounding trace are complementary — you need both → Attention to insights decays as CoT grows. This is the bottleneck → Replaying insights near the frontier shifts the optimal reasoning length rightward and raises the peak
Works at pure inference time across 30B-tier models. No training required. Post-training on this pattern improves both stability and performance over vanilla CoT.
𝐓𝐞𝐬𝐭-𝐭𝐢𝐦𝐞 𝐬𝐜𝐚𝐥𝐢𝐧𝐠 𝐢𝐬𝐧'𝐭 𝐣𝐮𝐬𝐭 𝐚𝐛𝐨𝐮𝐭 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐥𝐨𝐧𝐠𝐞𝐫. 𝐈𝐭'𝐬 𝐚𝐛𝐨𝐮𝐭 𝐤𝐞𝐞𝐩𝐢𝐧𝐠 𝐭𝐡𝐞 𝐫𝐢𝐠𝐡𝐭 𝐬𝐭𝐚𝐭𝐞 𝐚𝐜𝐜𝐞𝐬𝐬𝐢𝐛𝐥𝐞.
🧵1/N
The folk story about chain-of-thought: longer reasoning → better accuracy.
Recent studies show the curve isn't monotone. For a fixed problem, accuracy follows an inverted-U with CoT length: it rises, peaks, then declines. That peak puts a ceiling on what test-time scaling can buy you, and we'd like to push past it.
𝐋𝐨𝐧𝐠𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 ≠ 𝐛𝐞𝐭𝐭𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠. 𝐓𝐡𝐢𝐬 𝐛𝐫𝐞𝐚𝐤𝐬 𝐭𝐡𝐞 𝐬𝐜𝐚𝐥𝐢𝐧𝐠 𝐥𝐚𝐰. 𝐂𝐚𝐧 𝐰𝐞 𝐟𝐢𝐱 𝐢𝐭? On given problems, CoT accuracy follows an inverted-U: It rises, peaks, then falls as the chain grows longer. Harder problems push the peak rightward, but the cliff is always there. Test-time scaling has a ceiling that few talk about. So we asked: why does extra thinking hurt? We measured pre-softmax attention from answer tokens back to the critical insights buried earlier in the chain: the small subset of sentences that actually determine the final answer. The decay is monotonic with distance. The longer the model reasons, the less access it has to the very conclusions that matter most. It's reasoning with a fading memory of its own best ideas. This is the same problem sequence models have always faced. LSTMs solved it with an explicit memory cell that persists and updates as the sequence unfolds. The fix for long CoT should look the same. 𝐓𝐡𝐚𝐭'𝐬 𝐰𝐡𝐚𝐭 𝐰𝐞 𝐛𝐮𝐢𝐥𝐭. 𝐖𝐞 𝐜𝐚𝐥𝐥 𝐢𝐭 𝐈𝐧𝐬𝐢𝐠𝐡𝐭𝐑𝐞𝐩𝐥𝐚𝐲, 𝐬𝐭𝐚𝐭𝐞𝐟𝐮𝐥 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐟𝐨𝐫 𝐂𝐨𝐓. The reasoning state at any point is the cumulative set of insights the model has generated so far, compressed abstractions of prior reasoning. InsightReplay periodically extracts these insights and replays them near the active generation frontier, keeping them close to the decoding position so attention stays intact. What happens when you do this: The baseline peaks around 15K tokens on LiveCodeBench and then degrades. InsightReplay operates precisely in that degradation regime. 1 replay round improves accuracy. 3 rounds exceeds the baseline's peak. 5 rounds keeps climbing. The degradation regime becomes a continued-growth regime. → Critical insights and the surrounding trace are complementary — you need both → Attention to insights decays as CoT grows. This is the bottleneck → Replaying insights near the frontier shifts the optimal reasoning length rightward and raises the peak Works at pure inference time across 30B-tier models. No training required. Post-training on this pattern improves both stability and performance over vanilla CoT. 𝐓𝐞𝐬𝐭-𝐭𝐢𝐦𝐞 𝐬𝐜𝐚𝐥𝐢𝐧𝐠 𝐢𝐬𝐧'𝐭 𝐣𝐮𝐬𝐭 𝐚𝐛𝐨𝐮𝐭 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐥𝐨𝐧𝐠𝐞𝐫. 𝐈𝐭'𝐬 𝐚𝐛𝐨𝐮𝐭 𝐤𝐞𝐞𝐩𝐢𝐧𝐠 𝐭𝐡𝐞 𝐫𝐢𝐠𝐡𝐭 𝐬𝐭𝐚𝐭𝐞 𝐚𝐜𝐜𝐞𝐬𝐬𝐢𝐛𝐥𝐞.
🧵2/N
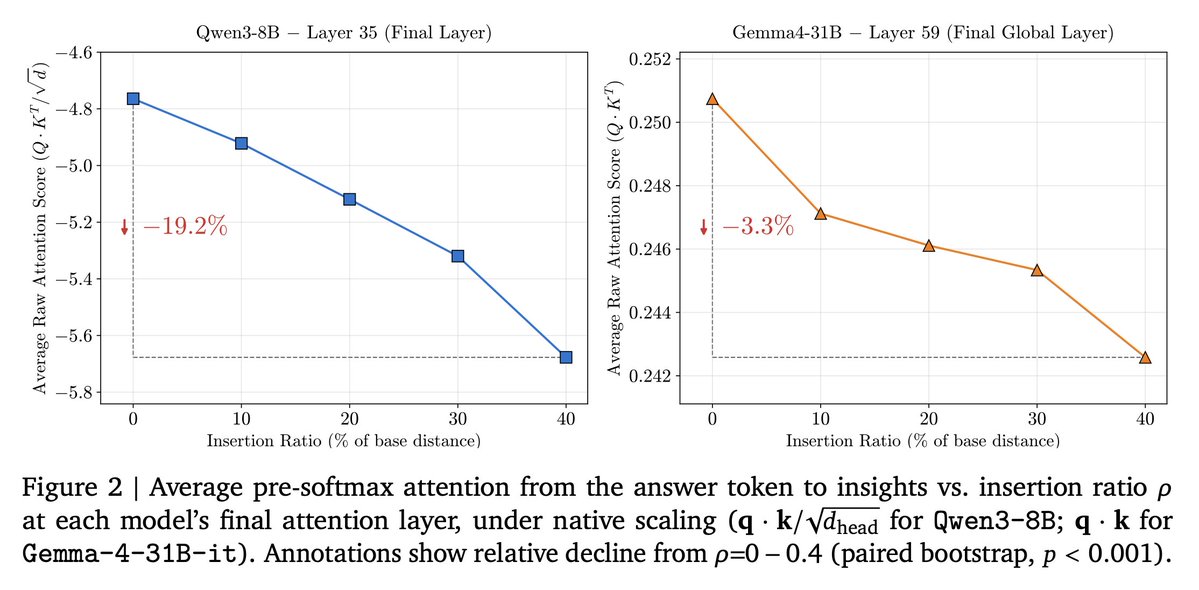
Why? We identify one driver of this decline: attention from the answer position to the trace's *critical insights* decays monotonically with distance.
Qwen3-8B: -19.2% end-to-end attention decay. Gemma-4-31B-it: -3.3% (its hybrid local/global attention helps).
The longer the model reasons, the less accessible its own earlier conclusions become.
🧵1/N The folk story about chain-of-thought: longer reasoning → better accuracy. Recent studies show the curve isn't monotone. For a fixed problem, accuracy follows an inverted-U with CoT length: it rises, peaks, then declines. That peak puts a ceiling on what test-time scaling can buy you, and we'd like to push past it.
🧵2/N: The attention decay problem in long CoT
We identify one driver of this decline: attention from the answer position to the trace's *critical insights* decays monotonically with distance.
Qwen3-8B: -19.2% end-to-end attention decay. Gemma-4-31B-it: -3.3% (its hybrid local/global attention helps).
The longer the model reasons, the less accessible its own earlier conclusions become.

🧵1/N The folk story about chain-of-thought: longer reasoning → better accuracy. Recent studies show the curve isn't monotone. For a fixed problem, accuracy follows an inverted-U with CoT length: it rises, peaks, then declines. That peak puts a ceiling on what test-time scaling can buy you, and we'd like to push past it.
🧵3/N: An old problem in new clothes: Analogy to LSTM
This is the same challenge sequence models have always faced: preserving information across long stretches of a sequence.
LSTMs solved it in 1997 (@SchmidhuberAI) with an explicit memory cell: a dedicated state that persists across time and gets continually updated as the sequence unfolds. The lesson wasn't "make recurrence stronger." It was "give the network a maintained memory."
Long CoT has the same shape of problem. The "sequence" is the reasoning trace. The "long-range information" is the critical insights produced earlier. Attention to them decays with distance.
So the natural question: can we equip a growing reasoning chain with an analogous mechanism — one that keeps critical insights accessible as the chain extends?
That's what InsightReplay does. ↓
🧵2/N: The attention decay problem in long CoT We identify one driver of this decline: attention from the answer position to the trace's *critical insights* decays monotonically with distance. Qwen3-8B: -19.2% end-to-end attention decay. Gemma-4-31B-it: -3.3% (its hybrid local/global attention helps). The longer the model reasons, the less accessible its own earlier conclusions become.
🧵4/N: InsightReplay, a stateful reasoning approach
Reasoning unfolds as two interleaving streams: → Reasoning chunks (R_t): step-by-step thinking → Insights (I_t): short distilled conclusions the model writes about its own prior reasoning
At each round t, the model (i) generates a reasoning chunk, then (ii) summarizes the conclusions reached so far into a new insight. The new insight is appended right before the next round of thinking begins.
Two consequences fall out: The latest insight always sits adjacent to the active generation frontier. Attention to critical conclusions stays intact no matter how long the chain grows. We're not making the model think more. We're keeping the important state close.
Each new insight is generated in the presence of all prior ones. So the insight trace isn't a flat list of summaries — it's an evolving abstraction. New insights can correct, refine, or supersede earlier ones.
The reasoning state at any point isn't the raw trace. It's the cumulative set of distilled conclusions, kept near the position where the model is actually decoding.

🧵3/N: An old problem in new clothes: Analogy to LSTM This is the same challenge sequence models have always faced: preserving information across long stretches of a sequence. LSTMs solved it in 1997 (@SchmidhuberAI) with an explicit memory cell: a dedicated state that persists across time and gets continually updated as the sequence unfolds. The lesson wasn't "make recurrence stronger." It was "give the network a maintained memory." Long CoT has the same shape of problem. The "sequence" is the reasoning trace. The "long-range information" is the critical insights produced earlier. Attention to them decays with distance. So the natural question: can we equip a growing reasoning chain with an analogous mechanism — one that keeps critical insights accessible as the chain extends? That's what InsightReplay does. ↓
🧵5/N: A Theoretical Analysis of InsightReplay
The empirical inverted-U has a clean theoretical model. Wu et al. (2025) parameterize M-step CoT accuracy as a product over per-step success probabilities — but assume each step's accuracy is independent of its position in the chain.
Section 2/N says that's wrong: attention to critical insights decays with distance.
We restore that dependence by introducing an insight accessibility function θ(δ): → θ(0) = 1 (adjacent → full access) → θ strictly decreasing in δ → θ(δ) → 0 as δ → ∞
In standard CoT, the model pays a multiplicative θ(t) penalty at every step — and the penalty worsens as the chain extends. In InsightReplay, insights are relocated to a fixed near-frontier distance δ_0, so the penalty becomes the constant θ(δ_0) > θ(t) for all t ≥ 1.
Two theorems drop out: Theorem 1 — InsightReplay shifts the optimal CoT length rightward: M_IR > M_θ Theorem 2 — InsightReplay raises the achievable peak accuracy: A_IR(M_IR) > A_θ(M_θ)
These map exactly onto the two phenomena from Figure 1: the peak moves right, and it goes up.
The proof doesn't say InsightReplay is the only solution. It says any mechanism that keeps θ(δ) bounded above the natural decay floor reshapes the inverted-U in this direction.
🧵4/N: InsightReplay, a stateful reasoning approach Reasoning unfolds as two interleaving streams: → Reasoning chunks (R_t): step-by-step thinking → Insights (I_t): short distilled conclusions the model writes about its own prior reasoning At each round t, the model (i) generates a reasoning chunk, then (ii) summarizes the conclusions reached so far into a new insight. The new insight is appended right before the next round of thinking begins. Two consequences fall out: The latest insight always sits adjacent to the active generation frontier. Attention to critical conclusions stays intact no matter how long the chain grows. We're not making the model think more. We're keeping the important state close. Each new insight is generated in the presence of all prior ones. So the insight trace isn't a flat list of summaries — it's an evolving abstraction. New insights can correct, refine, or supersede earlier ones. The reasoning state at any point isn't the raw trace. It's the cumulative set of distilled conclusions, kept near the position where the model is actually decoding.
🧵6/N: InsightReplay works, and longer thinking alone doesn't
24 settings (2 scales × 3 families × 4 benchmarks). 3-round InsightReplay: non-negative gains on every cell, +1.65 macro avg, largest +9.2 on R1-Distill-32B / LCB.
The control matters more than the headline.
"Verify-Only" gives the model the same extra tokens and a "wait, let me double-check" cue — no insight extraction. It captures only +0.61 of the +1.65 gain. The remaining +1.04 (over 60%) comes from InsightReplay itself.
Longer thinking is not the active ingredient. Keeping critical state accessible is.
The inverted-U becomes continued growth: at 5 replay rounds on LCB, accuracy is still climbing where standard CoT has already collapsed.


🧵5/N: A Theoretical Analysis of InsightReplay The empirical inverted-U has a clean theoretical model. Wu et al. (2025) parameterize M-step CoT accuracy as a product over per-step success probabilities — but assume each step's accuracy is independent of its position in the chain. Section 2/N says that's wrong: attention to critical insights decays with distance. We restore that dependence by introducing an insight accessibility function θ(δ): → θ(0) = 1 (adjacent → full access) → θ strictly decreasing in δ → θ(δ) → 0 as δ → ∞ In standard CoT, the model pays a multiplicative θ(t) penalty at every step — and the penalty worsens as the chain extends. In InsightReplay, insights are relocated to a fixed near-frontier distance δ_0, so the penalty becomes the constant θ(δ_0) > θ(t) for all t ≥ 1. Two theorems drop out: Theorem 1 — InsightReplay shifts the optimal CoT length rightward: M_IR > M_θ Theorem 2 — InsightReplay raises the achievable peak accuracy: A_IR(M_IR) > A_θ(M_θ) These map exactly onto the two phenomena from Figure 1: the peak moves right, and it goes up. The proof doesn't say InsightReplay is the only solution. It says any mechanism that keeps θ(δ) bounded above the natural decay floor reshapes the inverted-U in this direction.
🧵7/N: It also reinforces via RL post-training
We trained Qwen3-4B-Base with GRPO on DAPO-Math-15K. Baseline: standard CoT rollouts. InsightReplay: when the policy emits EOS, splice in a fixed continuation cue and let generation continue under the same length budget. Cue tokens are masked out of the loss — the only signal is the reasoning pattern itself.
Three findings on AIME 2025:
1. Stability. The baseline degrades after step ~300: mean@32 drops 27.9% → 21.6%, best@32 falls 57.5% → 42.0%. InsightReplay stays stable through step 600.
2. Peak. InsightReplay wins on all three metrics. Largest gap on maj@32 (the consistency-sensitive metric): 38.8% vs 34.1%, +4.7 points.
3. Not an initialization effect. The first ~200 steps overlap within noise. Divergence emerges only after step ~250 — the benefit is produced during training, not inherited from setup.
InsightReplay isn't just an inference trick. It's a reasoning pattern that can be reinforced as easily as it can be prompted.

🧵6/N: InsightReplay works, and longer thinking alone doesn't 24 settings (2 scales × 3 families × 4 benchmarks). 3-round InsightReplay: non-negative gains on every cell, +1.65 macro avg, largest +9.2 on R1-Distill-32B / LCB. The control matters more than the headline. "Verify-Only" gives the model the same extra tokens and a "wait, let me double-check" cue — no insight extraction. It captures only +0.61 of the +1.65 gain. The remaining +1.04 (over 60%) comes from InsightReplay itself. Longer thinking is not the active ingredient. Keeping critical state accessible is. The inverted-U becomes continued growth: at 5 replay rounds on LCB, accuracy is still climbing where standard CoT has already collapsed.
🧵8/8
Test-time scaling has been framed as "let the model think longer." Our results suggest a sharper frame: it's about whether critical intermediate state stays accessible across long reasoning trajectories. Reasoning depth without state preservation hits a ceiling. Stateful reasoning moves it.
Project website: https://research.simular.ai/insight-replay/ Paper: https://arxiv.org/abs/2605.14457 Code: https://github.com/simular-ai/insight-replay
Kudos to the InsightReplay team: Bin, Caiwen, Jiachen, @angli_ai, @xwang_lk. A joint collaboration between @SimularAI and U Minnesota.
🧵7/N: It also reinforces via RL post-training We trained Qwen3-4B-Base with GRPO on DAPO-Math-15K. Baseline: standard CoT rollouts. InsightReplay: when the policy emits EOS, splice in a fixed continuation cue and let generation continue under the same length budget. Cue tokens are masked out of the loss — the only signal is the reasoning pattern itself. Three findings on AIME 2025: 1. Stability. The baseline degrades after step ~300: mean@32 drops 27.9% → 21.6%, best@32 falls 57.5% → 42.0%. InsightReplay stays stable through step 600. 2. Peak. InsightReplay wins on all three metrics. Largest gap on maj@32 (the consistency-sensitive metric): 38.8% vs 34.1%, +4.7 points. 3. Not an initialization effect. The first ~200 steps overlap within noise. Divergence emerges only after step ~250 — the benefit is produced during training, not inherited from setup. InsightReplay isn't just an inference trick. It's a reasoning pattern that can be reinforced as easily as it can be prompted.