Nicholas Tomlin of NYU CDS releases a 10-task benchmark showing LLMs fail as user simulators because they lack human-like forgetting
LLMs had near-perfect recall; humans made structured, predictable errors.
As Nick says, we’re excited about the potential for leveraging cognitive science to improve user simulators, then use them to evaluate and train models that collaborate better with real humans.
I'm hiring (including but not limited to postdocs), let me know if interested in this direction!
New paper! LLM memory keeps improving, but this makes them *worse* as user sims. If we want to build models that can, e.g., simulate realistic students to train chatbots to be better teachers, then these models need to be able to forget like humans do 📄: https://arxiv.org/abs/2605.25680
New paper! LLM memory keeps improving, but this makes them *worse* as user sims. If we want to build models that can, e.g., simulate realistic students to train chatbots to be better teachers, then these models need to be able to forget like humans do
📄: https://arxiv.org/abs/2605.25680

We found that across tasks, language models perform at ceiling (for example, remembering lists of 20 digits perfectly, without any errors), even when prompted to behave like humans with limited working memory. This trend holds for a variety of models and prompting strategies
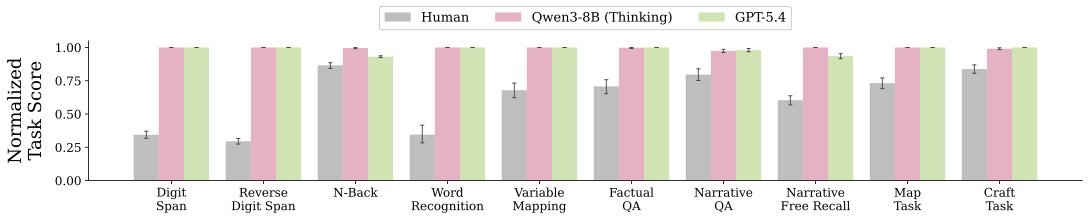
To compare humans and language models, we built a suite of 10 memory tasks, ranging from classic working memory tests (“remember this list of numbers”) to more open-ended tasks (“study this map and answer questions about it”)
Since prompting alone isn’t enough to simulate human memory, we also introduce an approach called COMPACTOR, where an LLM agent writes to a key-value memory store. We find that this leads to more human-like memory behavior:


We found that across tasks, language models perform at ceiling (for example, remembering lists of 20 digits perfectly, without any errors), even when prompted to behave like humans with limited working memory. This trend holds for a variety of models and prompting strategies
Finally, we show preliminary evidence that user simulators with more human-like memory are more useful. In particular, we find that our most human-like model is more capable of predicting which LLM outputs humans will best understand and remember:

Since prompting alone isn’t enough to simulate human memory, we also introduce an approach called COMPACTOR, where an LLM agent writes to a key-value memory store. We find that this leads to more human-like memory behavior:
This work was done with Qihan Wang, @michahu8, Brian Dillon, and @tallinzen! We’re excited about the continued potential for leveraging ideas from cogsci/linguistics and using them to improve user sims, which can be used to train models that collaborate better with real humans
Finally, we show preliminary evidence that user simulators with more human-like memory are more useful. In particular, we find that our most human-like model is more capable of predicting which LLM outputs humans will best understand and remember: