Stanford researchers release EXPO-FT, an open-source method for RL finetuning of Vision-Language-Action models
It achieved perfect success rates across real-world physical tasks.
EXPO-FT builds on EXPO (https://arxiv.org/abs/2507.07986)
The first idea of EXPO is to train a small Gaussian policy, to edit the VLA's actions.
We also continuously distill successful trajectories into the base VLA.

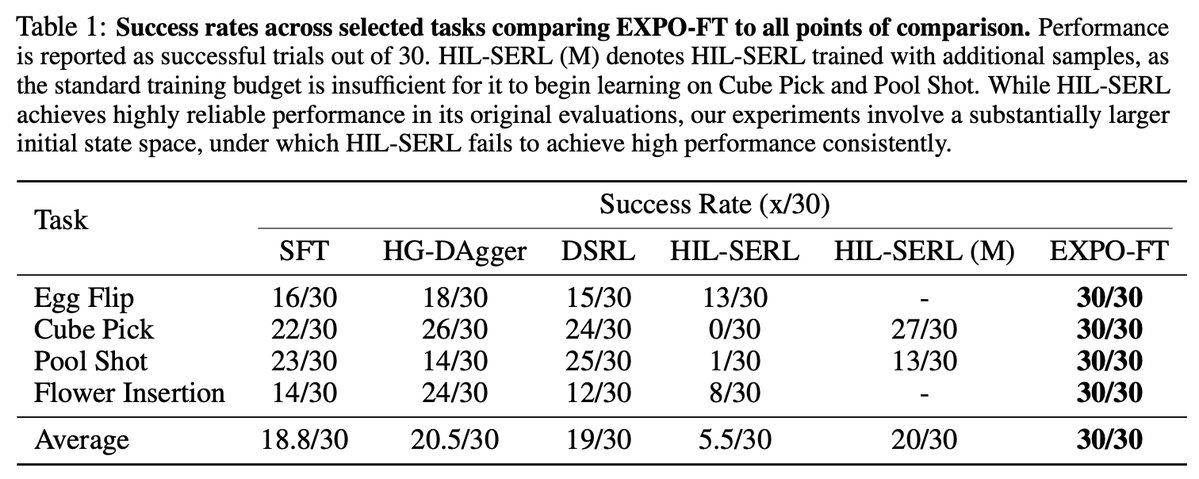
How can VLAs achieve 95+% reliability? Using RL post-training with EXPO-FT: - π0.5 improves to 30/30 success on all 8 tasks tested - uses only 19 min of RL data on average Paper & videos: https://pd-perry.github.io/expo-ft/
How can VLAs achieve 95+% reliability?
Using RL post-training with EXPO-FT: - π0.5 improves to 30/30 success on all 8 tasks tested - uses only 19 min of RL data on average
Paper & videos: https://pd-perry.github.io/expo-ft/
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning! EXPO-FT unlocks π0.5 for challenging manipulation tasks: Routing string lights & inserting the power connector to illuminate them Striking pool ball into pocket Inserting flower into wine bottle (1/5)
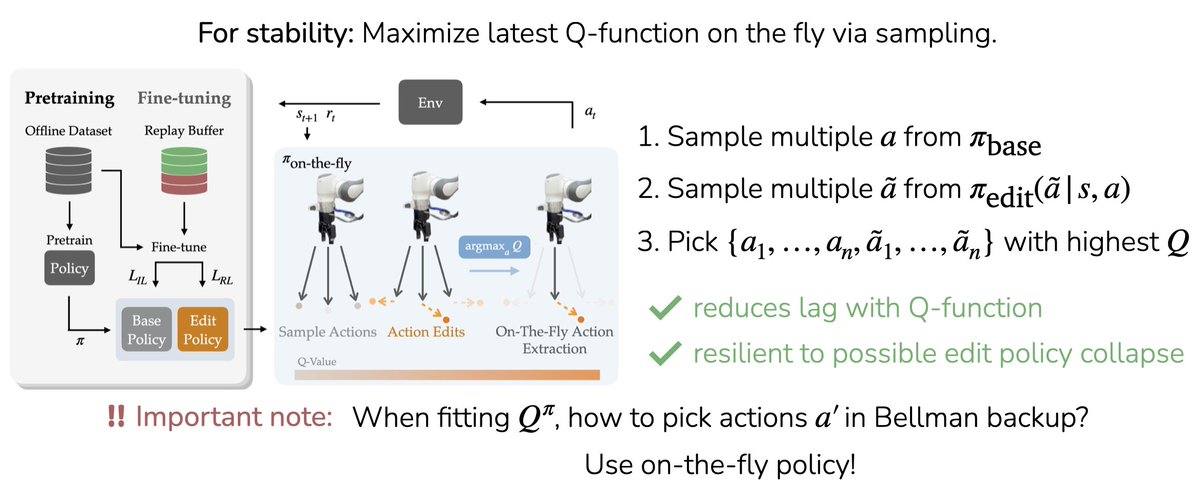
The second idea of EXPO is to maximize Q-values on the fly, with best-of-N sampling.
It's important to do this both at test time, and when sampling actions for the Q-function targets.
EXPO-FT builds on EXPO (https://arxiv.org/abs/2507.07986) The first idea of EXPO is to train a small Gaussian policy, to edit the VLA's actions. We also continuously distill successful trajectories into the base VLA.
Project led by @perryadong and @khhung906, with @TianGao_19, @DorsaSadigh @StanfordAILab
Check out the paper and website for many more details and cool robot videos! 🤖 https://pd-perry.github.io/expo-ft/ https://arxiv.org/abs/2605.25477
EXPO-FT extends EXPO to fine-tune VLAs in the real world, using image observations, action chunking, and DAgger data. Compared to past methods, EXPO-FT - reaches higher reliability with less data - handles wider set of initial states
EXPO-FT extends EXPO to fine-tune VLAs in the real world, using image observations, action chunking, and DAgger data.
Compared to past methods, EXPO-FT - reaches higher reliability with less data - handles wider set of initial states
The second idea of EXPO is to maximize Q-values on the fly, with best-of-N sampling. It's important to do this both at test time, and when sampling actions for the Q-function targets.