Florian Brand of Prime Intellect warns model harness variations heavily skew the updated SWE-rebench leaderboard results
Top model `gpt-5.5-2026-04-23-xhigh` achieved a 62.7% resolved rate.
all models have between 8% and 20% gap between Resolved Rate and Pass@5. And you can see the benefits of RL-maxxing from Cursor: pass@1 is up by 6.5% vs Kimi (same base), tokens down 2.5x… pass@5 did not change. The cost: just up to 5 times more compute. A bit disappointing.
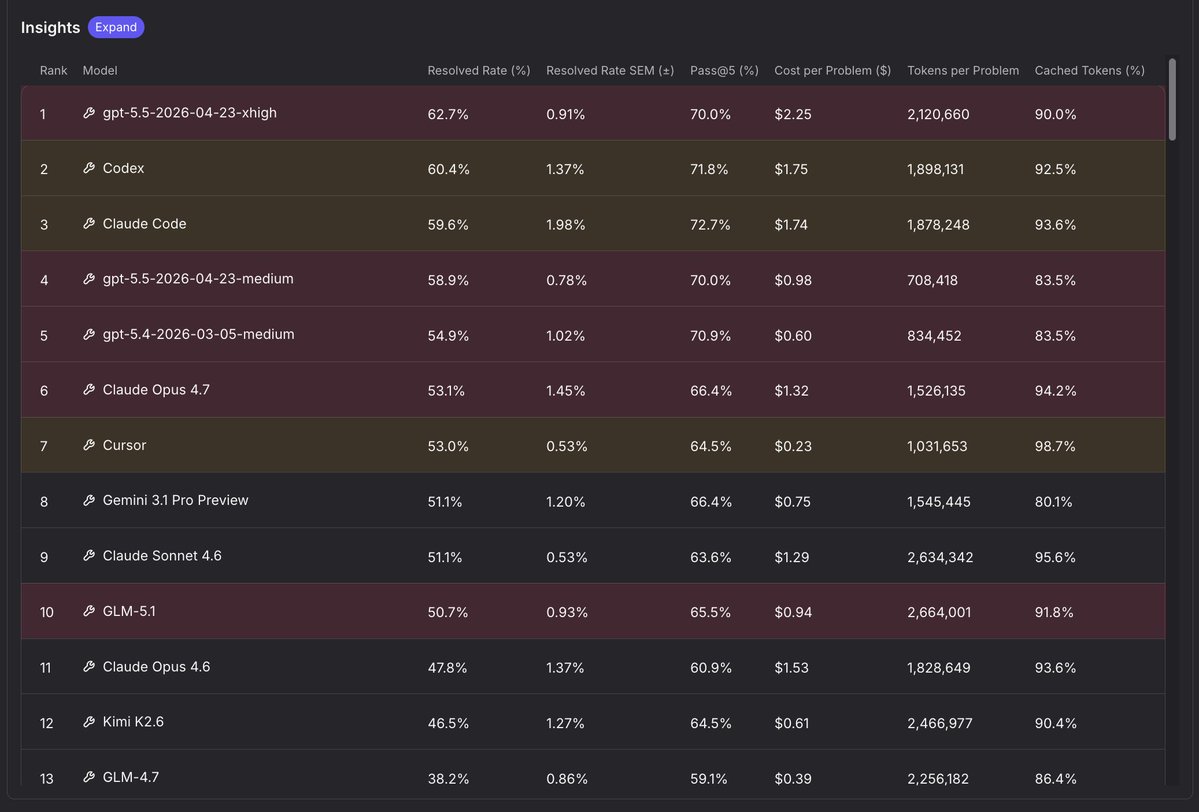
🚨 SWE-rebench big March-May update! SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub. updates: > we collected more fresh and complex tasks > we ran 110 tasks × 5 for each model / scaffold > the differences between models and scaffolds are now easier to distinguish > we will update the task set every two months, with model updates in between insights: > GPT-5.5 xhigh takes #1 with 62.7% resolved and 70.0% pass@5 > Cursor with Composer 2.5 is very cheap and strong: around 8× cheaper than Claude Code and Codex, and scores higher than open-weight models! @leerob Model updates will come in 1–2 weeks. Please send requests for models you want us to run! 🏆 Full leaderboard (check for price / tokens per problem, pass@5, scaffold params, etc): https://swe-rebench.com 👾 Join our Discord: https://discord.gg/V8FqXQ4CgU
codex medium +1.5% from mini-swe-agent-like cli to codex
opus +6.5% when switching to CC
makes me think once more that the deepswe results from yesterday were due to low n vs the harness being superior
🚨 SWE-rebench big March-May update! SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub. updates: > we collected more fresh and complex tasks > we ran 110 tasks × 5 for each model / scaffold > the differences between models and scaffolds are now easier to distinguish > we will update the task set every two months, with model updates in between insights: > GPT-5.5 xhigh takes #1 with 62.7% resolved and 70.0% pass@5 > Cursor with Composer 2.5 is very cheap and strong: around 8× cheaper than Claude Code and Codex, and scores higher than open-weight models! @leerob Model updates will come in 1–2 weeks. Please send requests for models you want us to run! 🏆 Full leaderboard (check for price / tokens per problem, pass@5, scaffold params, etc): https://swe-rebench.com 👾 Join our Discord: https://discord.gg/V8FqXQ4CgU