@scaling01 We know that current generation DS and Kimi can improve a lot with higher k, because they've had less RL pressure. Presumably this is even truer for previous generation. I don't think they're benchmaxed on public ARC-AGI set
Both V4 and Kimi K2.6 gain bigly in best@5 mode, with V4 equaling Gemini 3.1 Pro on net (not that it's a great feat). This suggests to me they're much less usemaxxed/have had less RL. Their median action is not pushed as close to optimal. Over dozens of steps, this adds up.
@scaling01 …Though actually this is just compared to Gemini, Ant and OpenAI models gain even more dominance
@scaling01 We know that current generation DS and Kimi can improve a lot with higher k, because they've had less RL pressure. Presumably this is even truer for previous generation. I don't think they're benchmaxed on public ARC-AGI set
Both V4 and Kimi K2.6 gain bigly in best@5 mode, with V4 equaling Gemini 3.1 Pro on net (not that it's a great feat). This suggests to me they're much less usemaxxed/have had less RL. Their median action is not pushed as close to optimal. Over dozens of steps, this adds up.
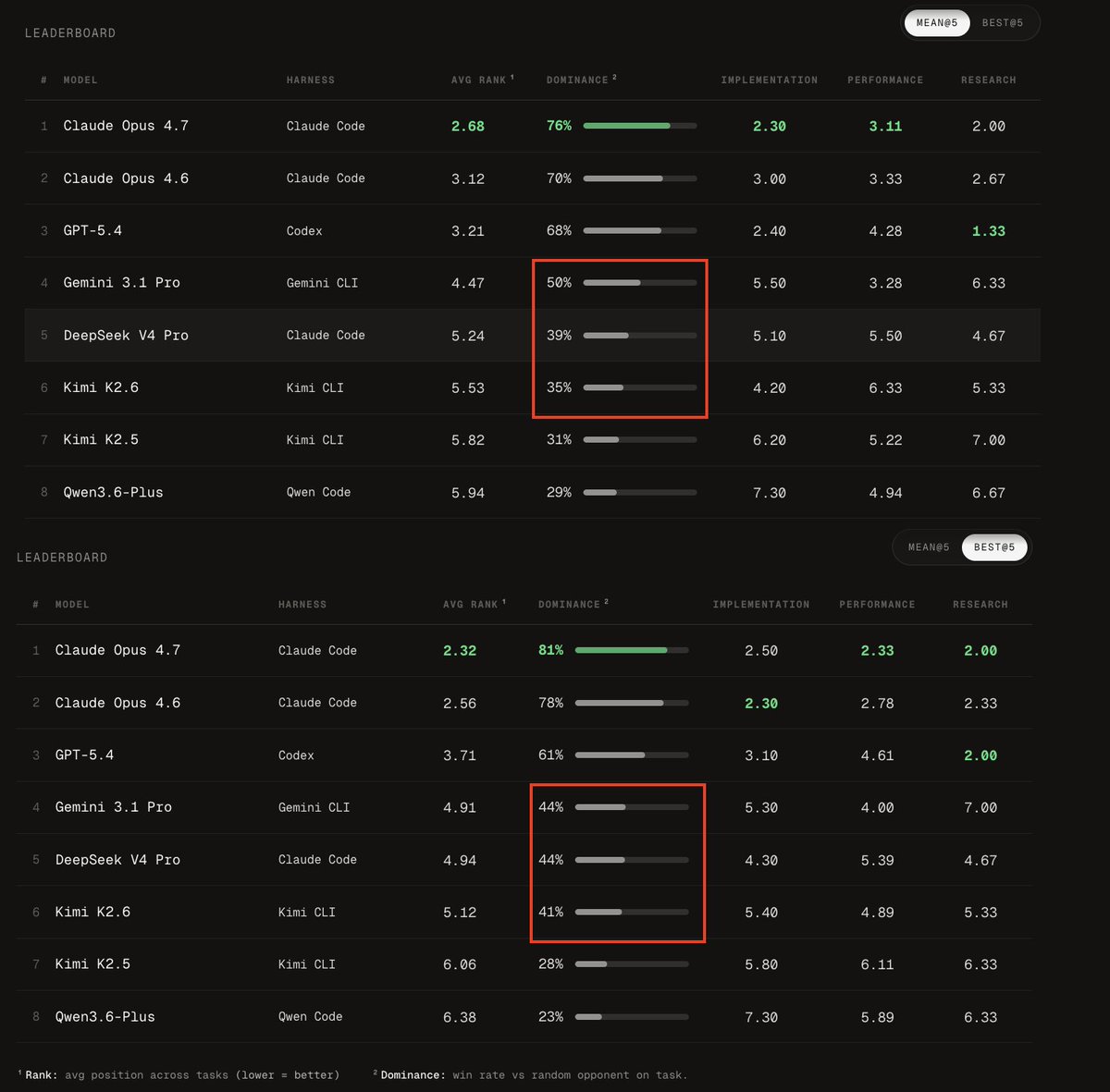
Interesting that Opus only grows stronger though
Both V4 and Kimi K2.6 gain bigly in best@5 mode, with V4 equaling Gemini 3.1 Pro on net (not that it's a great feat). This suggests to me they're much less usemaxxed/have had less RL. Their median action is not pushed as close to optimal. Over dozens of steps, this adds up.
What do you think @scaling01? How much is the advantage of giga-models like Mythos, as per your thesis about path dependency of early moves, just density of stochastic errors, which exponentially expand the space to walk to solution and so cut success rate?
Both V4 and Kimi K2.6 gain bigly in best@5 mode, with V4 equaling Gemini 3.1 Pro on net (not that it's a great feat). This suggests to me they're much less usemaxxed/have had less RL. Their median action is not pushed as close to optimal. Over dozens of steps, this adds up.
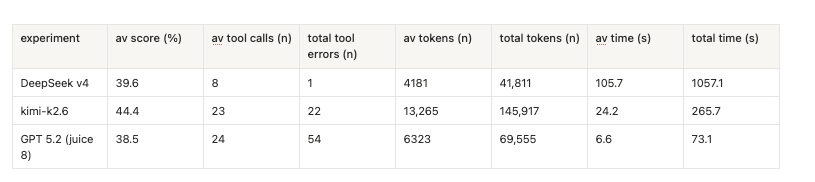
> pretty efficient …that's not the word. What in the world are these stats? it has vastly lower token use *and* tool error rate than both Kimi K2.6 (a very good model) and GPT 5.2?
incredible. Below glm-5.1, below kimi k2.6, below gemma4-31b, below gpt-oss-120b (high), below GLM-5, below deepseek-v3.2-speciale (!!) and barely different from Flash-Max. What the hell. Inferior to smaller models derivative of previous generation. It's over?

as of now, no DeepSeek has officially exceeded o1-preview on this proxy of RSI potential.
incredible. Below glm-5.1, below kimi k2.6, below gemma4-31b, below gpt-oss-120b (high), below GLM-5, below deepseek-v3.2-speciale (!!) and barely different from Flash-Max. What the hell. Inferior to smaller models derivative of previous generation. It's over?
> DeepSeek V4 - Outstanding at bug-fixing Everyone says so. V4 is really such a strange thing. Every model that DeepSeek makes, they makes for themselves; products are almost incidental. But why… bug-fixing? Because they expect *more* nightmare mode engineering?
I mean, yeas it is a fundamental component of software engineering workflow. But nobody says "its great at writing kernels". Broadly nobody claims it's exceptional at generating any code from scratch. No, it's a 1M tokens context super cheap bug eater.
> DeepSeek V4 - Outstanding at bug-fixing Everyone says so. V4 is really such a strange thing. Every model that DeepSeek makes, they makes for themselves; products are almost incidental. But why… bug-fixing? Because they expect *more* nightmare mode engineering?