Google’s Gemini 3.5 Flash scores 55 on the Artificial Analysis Intelligence Index, a nine-point gain over Gemini 3 Flash, while leading the intelligence-speed frontier and exceeding 280 output tokens per second
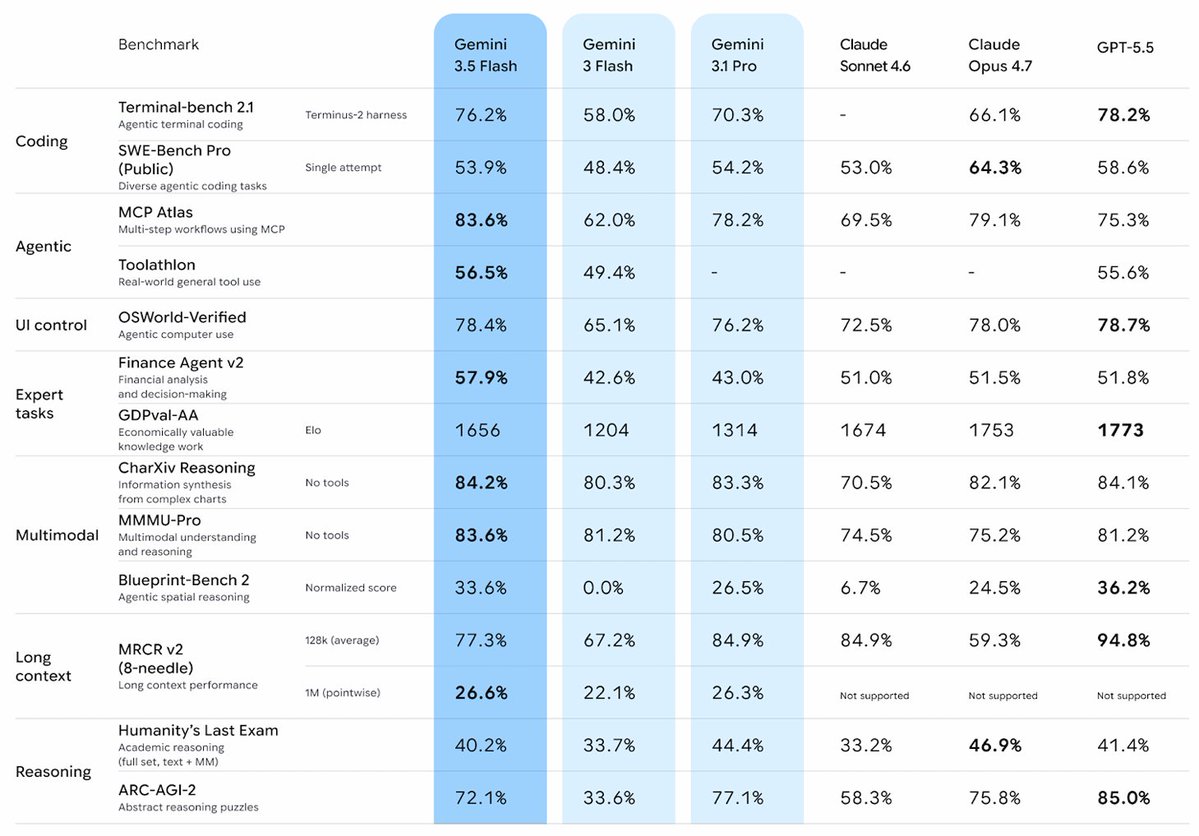
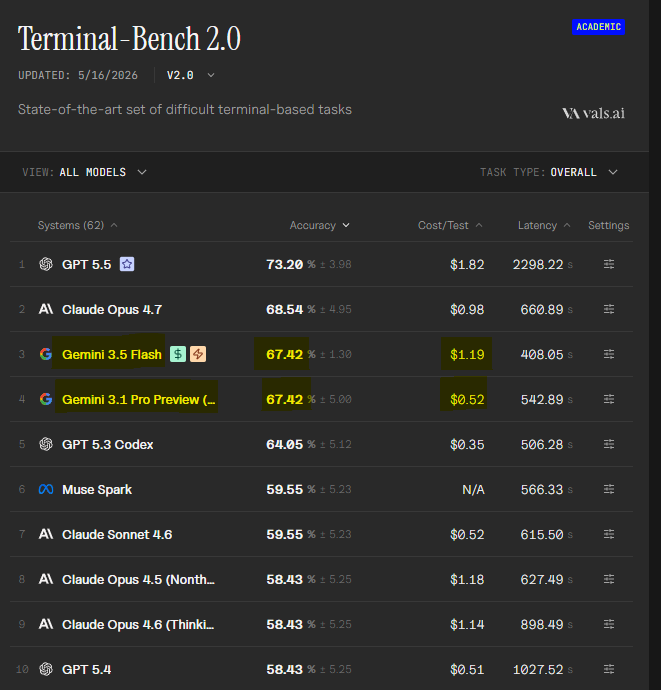
It posts 76.2 percent on Terminal-bench 2.1.
Gemini
Knowledge cutoff on this is very confusing. Is this a bug? Does Flash not know that vibecoding is thing now? Does it not know about claude code!?
Gemini 3.5 Flash now live in aistudio
I am actually quite confused.
What went wrong here: Is all 2025 + 2026 data all slop and compute inefficient? Why would you train a model in 2026 that misses an entire year+ of data and take it to market?
Knowledge cutoff on this is very confusing. Is this a bug? Does Flash not know that vibecoding is thing now? Does it not know about claude code!?
@scaling01 @PMinervini Have you tried it on antigravity its a slight improvement on tool call, but not a daily model to use for coding.
meh doesn't even beat Kimi or GLM
@scaling01 @PMinervini @eliebakouch @vincentweisser it would be fun for you guys to use this against claude and codex in auto research loop and see if it has good tastes.
@scaling01 @PMinervini Have you tried it on antigravity its a slight improvement on tool call, but not a daily model to use for coding.
@scaling01 @PMinervini @eliebakouch @vincentweisser In some sense, both claude and codex both used human ingenuity and put them together in clever ways. While models lack taste on research with right prompting it can driven to really amazing outcomes. This itself can be an eval if you run it, and compare outcomes.
@scaling01 @PMinervini @eliebakouch @vincentweisser it would be fun for you guys to use this against claude and codex in auto research loop and see if it has good tastes.
@zephyr_z9 I am curious why you say this. Mrcr? This is good guess/deduction
Clearly has very low active parameters but a lot more total parameters
Gemini 3.5 Flash announced!

RL roughly on trend, multimodality on trend, strange to see them report mediocre MRCR and ARC-AGI-2. Given the speed, it might well have fewer active parameters than Flash-3 (so they both shrink the batch and grow margin). Will be a successful model until we get some 5.6-Mini.
Gemini 3.5 Flash Benchmarks
I'm wrong, thanks @yourboiilevi it's G3 Flash base, they just serve it faster interesting

RL roughly on trend, multimodality on trend, strange to see them report mediocre MRCR and ARC-AGI-2. Given the speed, it might well have fewer active parameters than Flash-3 (so they both shrink the batch and grow margin). Will be a successful model until we get some 5.6-Mini.
@zephyr_z9 same model as 3 flash
Clearly has very low active parameters but a lot more total parameters
I think one neglected area in model evals is case studies of LLM-Hard questions. Like, here we see that literally nothing can crack #10 and #12 ArXivMath in a few shots. (somehow #6 yields to… Qwen-2B). If we aren't just training on test, CoTs of such problems deserve scrutiny.

Meh On MathArena, Gemini 3.5 Flash is neither bad nor great. It is very fast though: I ran 1000 queries in 30 minutes.
now admittedly it got 4 tries vs 3-4 for others, but still, lmao on apex-shortlist we see that top models struggle with #18 but those below them do not. Might it just be a ground truth failure? @j_dekoninck

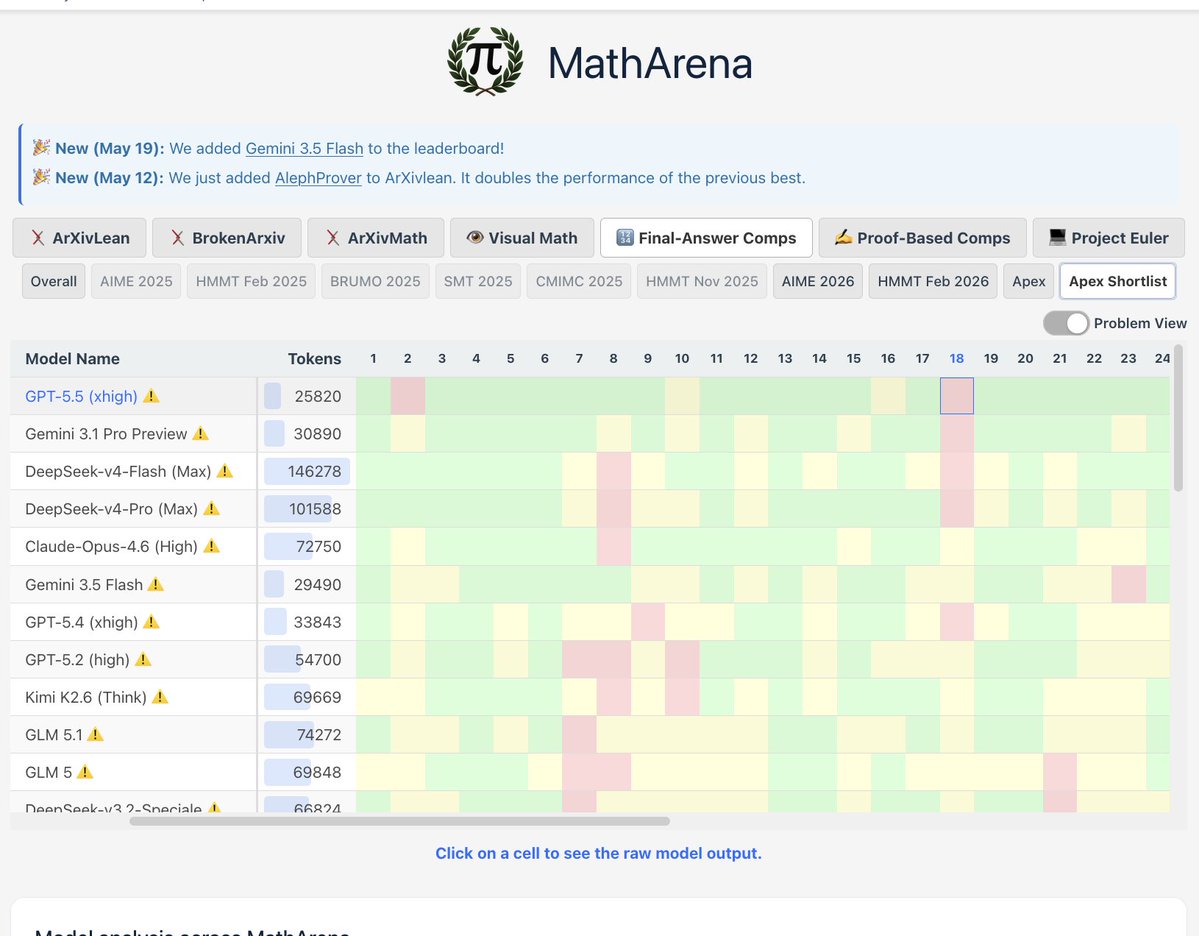
I think one neglected area in model evals is case studies of LLM-Hard questions. Like, here we see that literally nothing can crack #10 and #12 ArXivMath in a few shots. (somehow #6 yields to… Qwen-2B). If we aren't just training on test, CoTs of such problems deserve scrutiny.
IMO #6 was a famous one. Recently got cracked with GPT 5.5 Pro. But that's not very interesting. A year later OpenAI's best can do this hard thing everyone was aware of, Duh. Tells us little. The recent OpenDeepThink from @wenhaocha1 et al (which I kinda reproduced) boasts +400 Elo on CF, but they also say this: "Of the seventeen unsolved problems across the Flash and 2.5 Pro runs, none crosses 5% pass@1 in any generation". I do not think models of this era literally do not have the "competence" for solving any particular programming task, it's all compositional. So I am generally much more intrigued in techniques that can break through this barrier than in amplifying pass@k by changing how we fiddle with K and partition it into l, m, n. Likewise for methods like PaCoRe from @StepFun_ai or the new MCTS from @ZyphraAI. How do we get unsolvable things solved by trading compute for intelligence rather than "performance"? Ultimately that's the whole promise of this journey to AGI via scaling, isn't it. Is there a way that doesn't just rely on iterative training of models on synthetic data? If that were all, we're at risk at having to do exponentially costly search for data recipes that do not exceed inherent capability of models and thus lead to narrow-generalizing memorization of patterns and more false promises. Yes, we can evidently stack these chairs to a dizzying height if money is no issue, but could we at least evolve to processing them into plywood already? Might be a reason GDM is so calm in the face of two "startups"; why Gemini is half-assing this main vector of market competition that is agentic SWE. Demis suspects that AGI have to be done the hard way, from the ground up. Raw bytes, universal predictors, world models; removing layers of human-digested slop between downstream outputs and bare metal as your stockpile of metal grows. The "synthetic data" stockpile might prove to be fairy gold if he's right.


now admittedly it got 4 tries vs 3-4 for others, but still, lmao on apex-shortlist we see that top models struggle with #18 but those below them do not. Might it just be a ground truth failure? @j_dekoninck
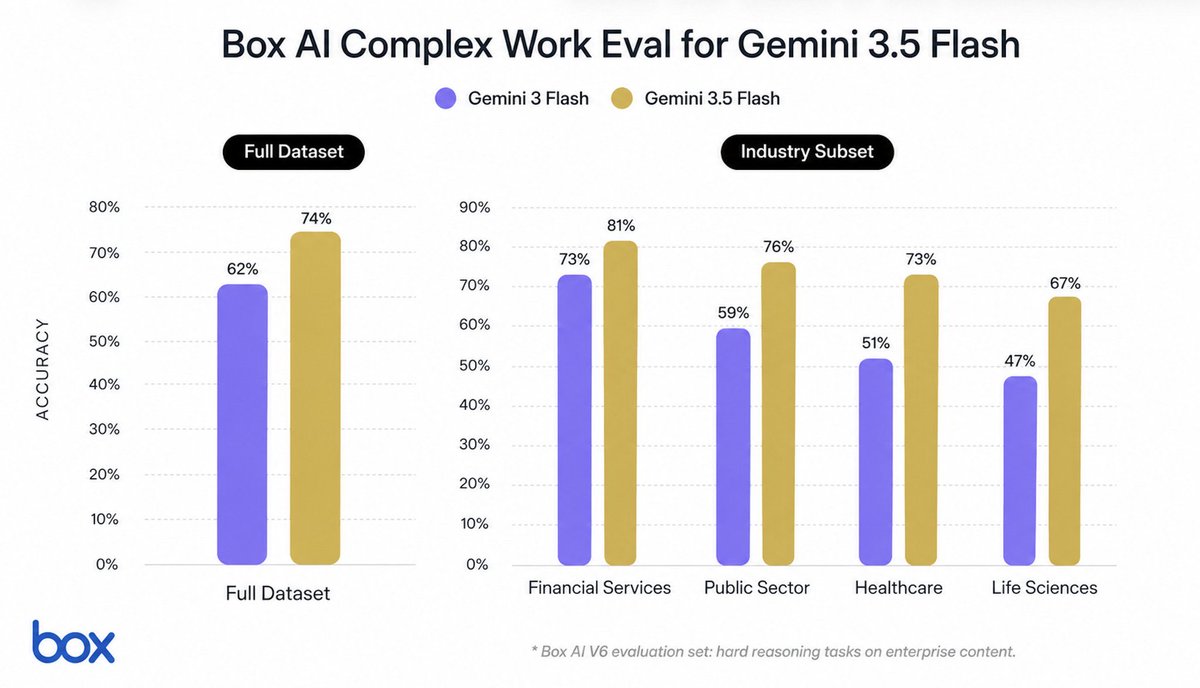
Gemini 3.5 Flash is out, and it's a major jump over Gemini 3 Flash in model capability for knowledge work. We've been evaluating it on our Box AI Complex Work Eval in early release, and the model delivers a 12 percentage point jump on complex document tasks.
For testing this model, we give the Box AI Agent (using Gemini 3.5) complex problems to solve that represent common but difficult knowledge worker tasks in banking, consulting, public sector, healthcare, and other industries. These tasks can be things like drafting reports, doing due diligence, and more, given a set of relevant documents.
In our tests, Gemini 3.5 Flash delivered jumps across every industry, including:
* Financial services: 81% vs 73% (+8pp) * Public sector: 76% vs 59%, (+17pp) * Healthcare: 73% vs 51%, (+22pp) * Life Sciences: 67% vs 47%, (+20pp)
Incredible to see the continued performance gains.
Gemini 3.5 Flash will be available soon in Box AI Studio and through the Box API. The Box MCP Server will soon be available in the Gemini app with more details to come.
@_arohan_ @scaling01 @PMinervini @vincentweisser 👀 could be fun indeed, will look into this
@scaling01 @PMinervini @eliebakouch @vincentweisser it would be fun for you guys to use this against claude and codex in auto research loop and see if it has good tastes.
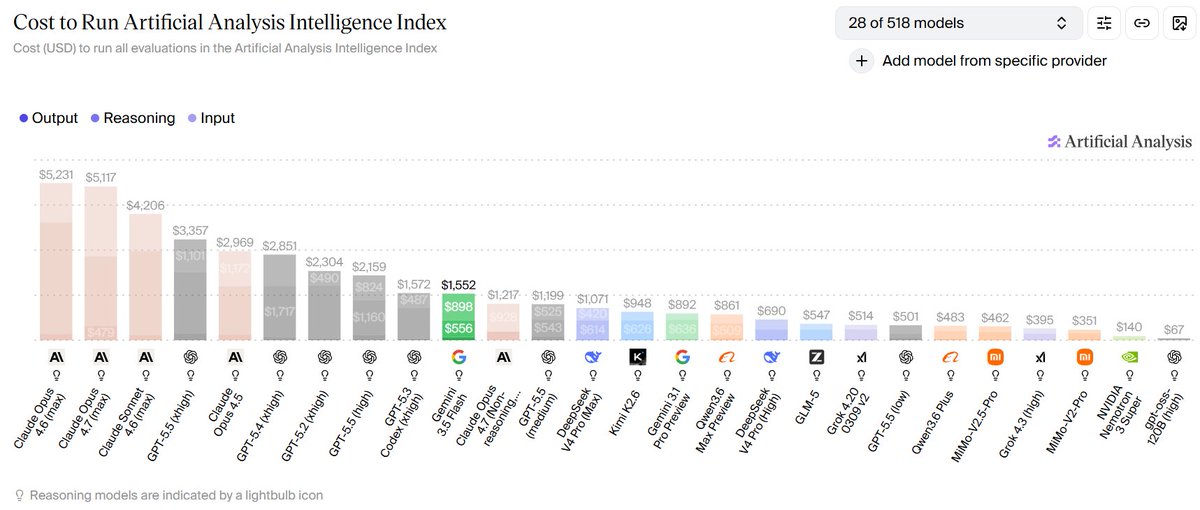
some more Gemini 3.5 Flash benchmarks by Artificial Analysis AI: - the APEX-Agents-AA score is excellent - expected higher on CritPt - reasoning efficiency could also be better, but it kind of depends on what setting they used. if it's the max then it's very good - Price/Perf looks pretty bad vs GPT-5.5. You can get GPT-5.5-medium with better performance for less and with faster responses


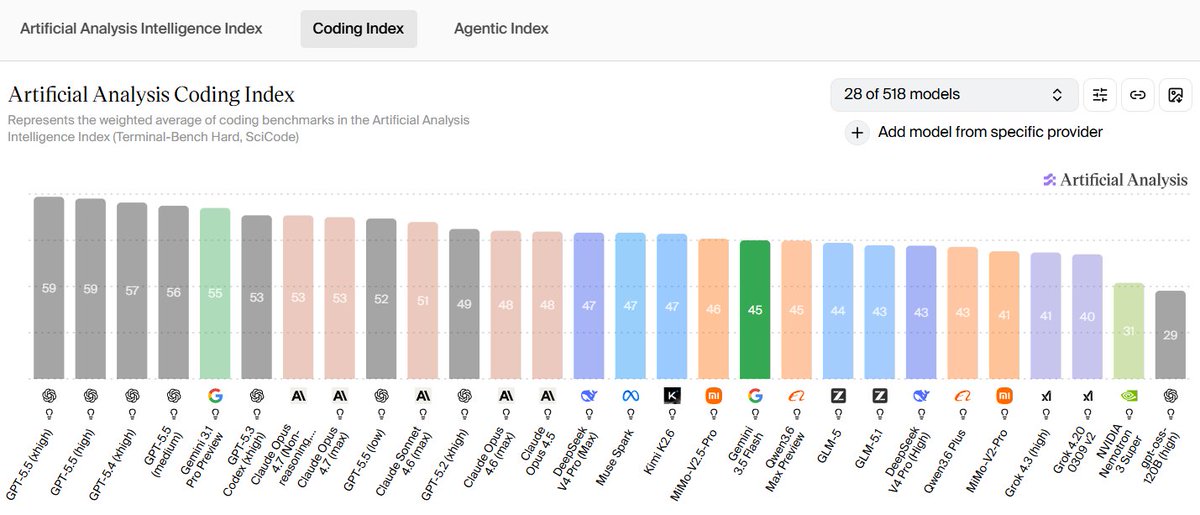
Gemini 3.5 Flash scores kinda low on the Coding Index due to terrible TerminalBench-Hard scores
Gemini 3.5 Flash Benchmarks
Gemini 3.5 Flash Benchmarks

Gemini 3.5 Flash Benchmarks
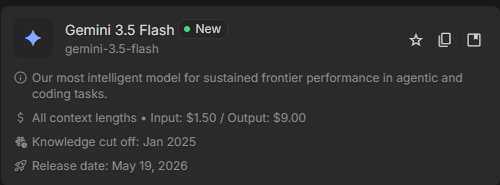
interestingly it still has the Jan 2025 knowledge cut-off

Gemini 3.5 Flash Benchmarks
Google optimized Gemini 3.5 Flash to make it run up to 12x faster (~867 tokens/s) than comparable models in AntiGravity
Gemini 3.5 Flash comparable with Opus 4.7, GPT-5.5 and Gemini 3.1 Pro on the Artificial Analysis Index while running up to 4x faster
Gemini 3.5 Flash now live in aistudio
Gemini 3.5 Flash Benchmarks
bruh
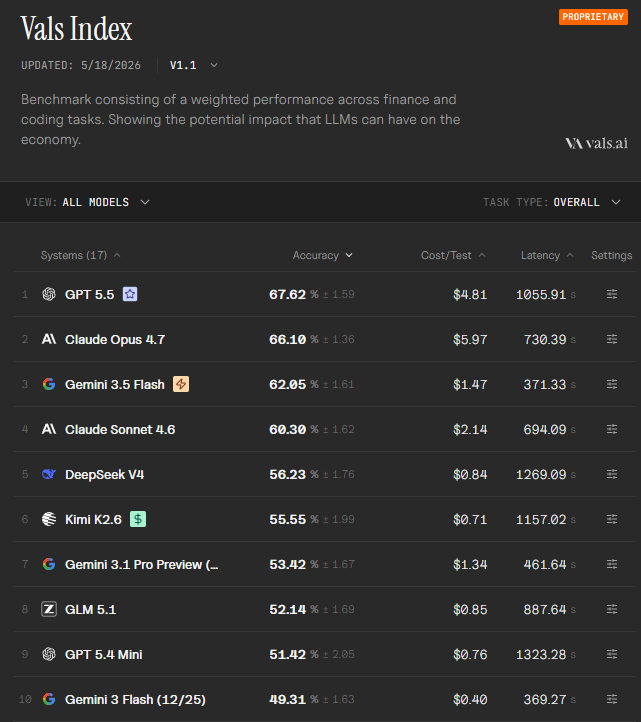
Gemini 3.5 Flash ranking third on vals index
Gemini 3.5 Flash comparable with Opus 4.7, GPT-5.5 and Gemini 3.1 Pro on the Artificial Analysis Index while running up to 4x faster


Gemini 3.5 Flash beats Gemini 3.1 Pro across TerminalBench 2.1, GDPval and MCP Atlas
GPT-5.5-medium has lower end-to-end latency, uses less tokens and is overall smarter and cheaper than Gemini 3.5 Flash
it might genuinely be over for anyone not named OpenAI or Anthropic
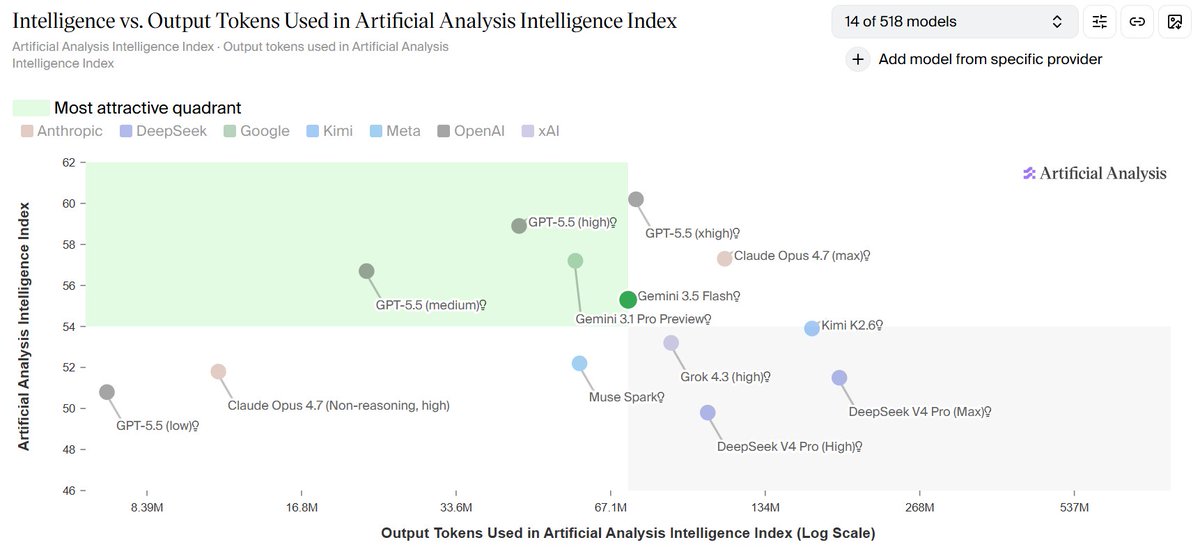
some more Gemini 3.5 Flash benchmarks by Artificial Analysis AI: - the APEX-Agents-AA score is excellent - expected higher on CritPt - reasoning efficiency could also be better, but it kind of depends on what setting they used. if it's the max then it's very good - Price/Perf looks pretty bad vs GPT-5.5. You can get GPT-5.5-medium with better performance for less and with faster responses
Gemini 3.5 Flash Pricing confirmed at $1.5 / $9 per mtoks

Gemini 3.5 Flash Benchmarks
Gemini 3.5 Flash scores kinda low on the Coding Index due to terrible TerminalBench-Hard scores
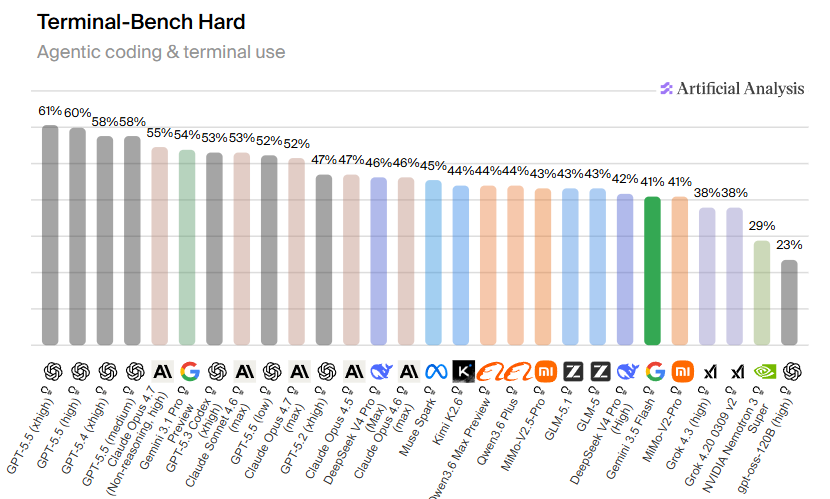
Gemini 3.5 Flash beats Gemini 3.1 Pro across TerminalBench 2.1, GDPval and MCP Atlas

GPT-5.5-medium has lower end-to-end latency, uses less tokens and is overall smarter than Gemini 3.5 Flash
it might genuinely be over for anyone not named OpenAI or Anthropic
some more Gemini 3.5 Flash benchmarks by Artificial Analysis AI: - the APEX-Agents-AA score is excellent - expected higher on CritPt - reasoning efficiency could also be better, but it kind of depends on what setting they used. if it's the max then it's very good - Price/Perf looks pretty bad vs GPT-5.5. You can get GPT-5.5-medium with better performance for less and with faster responses
meh
doesn't even beat Kimi or GLM
Gemini 3.5 Flash has landed #9 for Text and Code Arena: Frontend. Code Arena: Frontend evaluates models on agentic frontend coding tasks from real users building apps and websites (HTML and React). Scoring 1507, this is a significant +70 point improvement over Gemini-3 Flash. Sub-category highlights: - #7 Content Creation Tools - #8 Gaming - #8 Consumer Product - #9 Data & Analytics - #10 Reference-Based Design In Text Arena: #9 overall. Gemini 3.5 Flash also moves the price–performance frontier as the new top Arena score in its price tier. Congrats to the @GoogleDeepMind team on this launch! Click into the thread to see the rankings by each arena.
(deliberately not hyping Gemini 3.5 Flash too much this time. looks like an insane model, but you know how it is with self-reported benchmarks)
i mean this is ridiculous
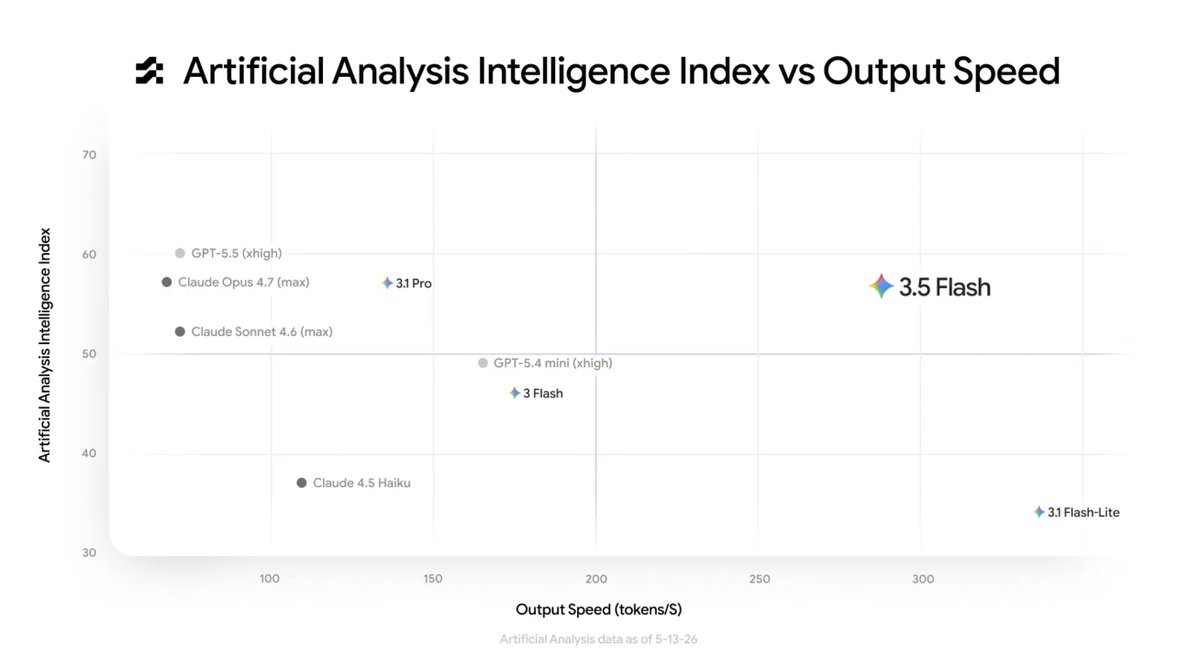
(deliberately not hyping Gemini 3.5 Flash too much this time. looks like an insane model, but you know how it is with self-reported benchmarks)
The new Gemini 3.5 Flash solved the HVM3's wnf bug in 1/3 attempts. This is my main test to take a model seriously. So far only the big models like GPT 5.5 solved it.
And seems like it is 20x faster than Opus 4.6 !
Promising but Google will still find a way to fuck up
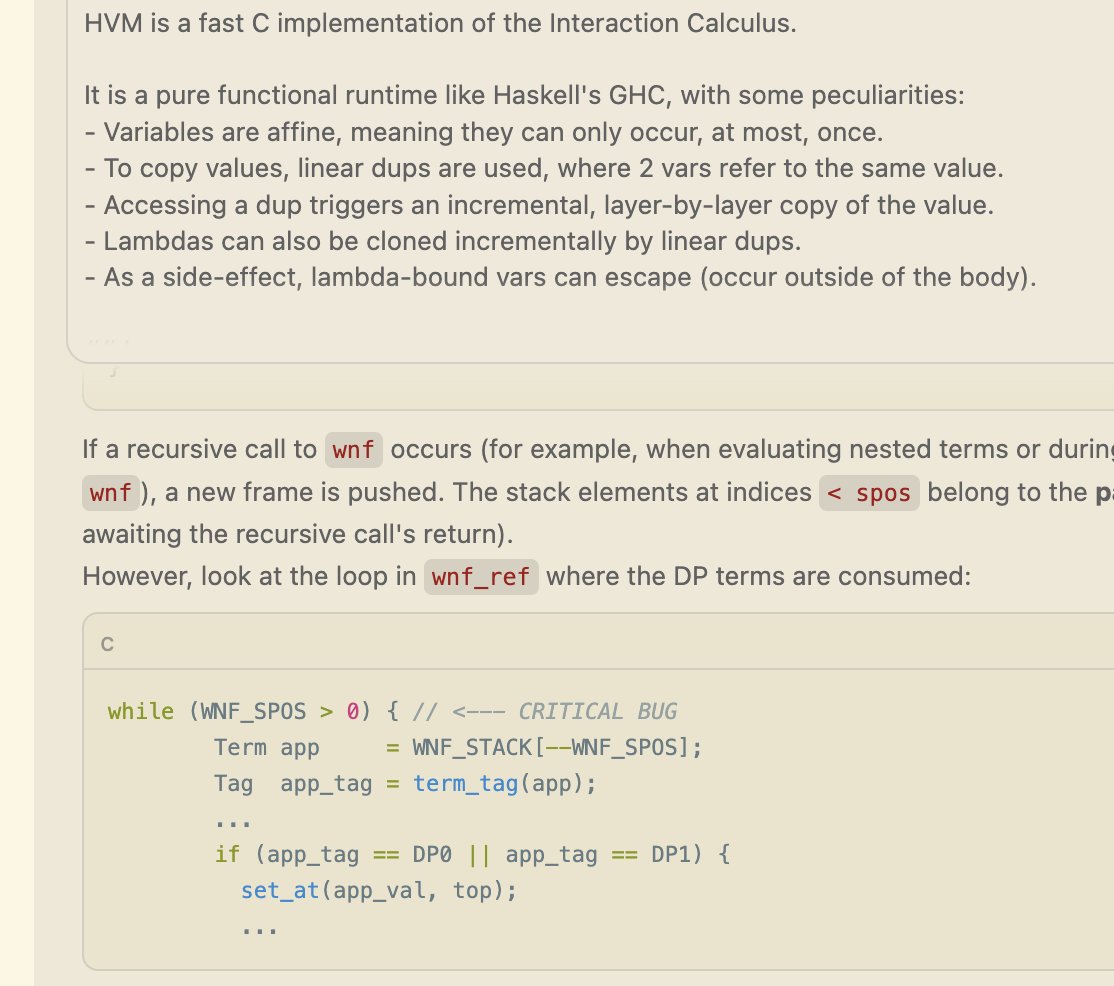
The new Gemini 3.5 Flash solved the HVM3's wnf bug in 1/3 attempts. This is my main test to take a model seriously. So far only the big models like GPT 5.5 solved it. And seems like it is 20x faster than Opus 4.6 ! Promising but Google will still find a way to fuck up
I'm getting only ~80 tokens/s on Gemini 3.5 Flash after launch? It peaked at 1000+ before. Since there is no API, it is hard to measure though...
The new Gemini Flash solved the HVM3's wnf bug in 1/3 attempts. This is my main test to take a model seriously. So far only the big models like GPT 5.5 solved it.
And seems like Gemini Flash is 20x faster than Opus 4.6 !
Promising but Google will still find a way to fuck up
btw this model is absolutely great
I just think locking the best product (fast-mode) under an old school visual IDE is a completely moronic business decision that only the Kodak of AI could truly make
Deleted again because misinformation 🥲 Gemini 3.5 Flash *is* available on the API. Yet, both the API and the CLI versions are 3x slower than on the IDE! See the video below. → Antigravity IDE: 4 seconds (smooth) → Antigravity CLI: 15 seconds (buggy) So the point holds: they want you to use the visual IDE. Problem is: it is 2026. NOBODY should be using IDEs anymore. Get over it. Let it GO. I’m certainly not launching a VSCode fork to use a model, no matter how great it is. They invent a portal gun, only to lock it behind a taxi subscription, because they completely fail to realize their very product deprecates that other thing they think will make them money? Cursor is a great example of a company that (sadly) is very likely fail because of that mindset. Composer is actually surprisingly good model. They should put all efforts in serving it. Yet, they keep locking it under an old school product that nobody wants to use. And even these who DO use IDEs probably won’t necessarily pick YOUR IDE. And they shouldn’t. You do NOT need them to, to make money. Your model is the product. You keep chasing old business models. Completely out of touch. Meanwhile Anthropic is all charging at full speed to sooner or later surpass Google by just serving great models under an API /ctrlv
Translating the same text, IDE vs CLI
→ IDE: smooth, 4 seconds
→ CLI: buggy, 15 seconds
I'm NOT using an IDE in 2026. I really want to stop giving money to Anthropic but everyone else is making it so hard

Narrator: they already fucked up → Gemini 3.5 Flash not available on API. → Fast mode locked to Antigravity only. I don’t understand why companies keep doing this. They invent a portal gun, only to lock it behind a taxi subscription, because they completely fail to realize their very product deprecates that other thing they think will make them money? Cursor is a great example of a company that (sadly) is very likely fail because of that mindset. Composer is actually surprisingly good model. They should put all efforts in serving it. Yet, they keep locking it under an old school product that nobody wants to use. It is 2026. NOBODY should be using IDEs anymore. Get over it. Let it GO. I’m certainly not launching a VSCode fork to use a model, no matter how great it is. And even these who DO use IDEs probably won’t necessarily pick YOUR IDE. And they shouldn’t. You do NOT need them to, to make money. Your model is the product. You keep chasing old business models. Completely out of touch. Meanwhile Anthropic is all charging at full speed to sooner or later surpass Google by just serving great models under an API!!! ~~~ Reposting this. I deleted before because they launched Antigravity CLI, which isn't an API, but at least gives us *some* flexibility. But no: I'm getting 10x slower TPS on CLI compared to the IDE. So either a bug or they really want you to use the visual IDE. So my money will keep going to Anthropic, unfortunately. 🤦♂️
3/ The positioning is clear:
Flash is no longer just “cheap fast model.”
Google wants Gemini 3.5 Flash to be the default engine for long-horizon agents: plan, build, iterate, use tools, execute code, complete real work.
Gemini 3.5 Pro comes next month. Can't wait to try Flash

2/ Benchmark are crazy: • Terminal-Bench 2.1: 76.2% • GDPval-AA: 1656 Elo • MCP Atlas: 83.6% • CharXiv Reasoning: 84.2% Google says 3.5 Flash beats Gemini 3.1 Pro on key coding/agentic evals and is 4x faster than other frontier models!
So Google just cooked everyone on cost & speed Harnessing the full power of model-hardware co design Extreme sparsity and Ironwoods
Gemini 3.5 Flash comparable with Opus 4.7, GPT-5.5 and Gemini 3.1 Pro on the Artificial Analysis Index while running up to 4x faster
Clearly has very low active parameters but a lot more total parameters

Gemini 3.5 Flash is built to help you execute complex, agentic workflows. 3.5 Flash rivals flagship models to deliver frontier performance for agents and coding, at the lightning speeds you expect from the Flash series.
Google Makes A Come Back - Gemini Flash Early Vibes
- brilliant instruction follower!! like absolutely stunning - good on agentic coding - it is NOT bench-maxxed
This is genuinely a good model at a great price from Google.
Overall a way better alternative to Sonnet. Will be on ChatLLM shortly
(3/4) And...did I mention 3.5 Flash is so fast?

(2/4) I'm really proud of the model's performance. Gemini 3.5 Flash outperforms Gemini 3.1 Pro on most benchmarks -- it's great at code & agentic workflows, and continues Gemini's multimodal excellence
(2/4) I'm really proud of the model's performance. Gemini 3.5 Flash outperforms Gemini 3.1 Pro on most benchmarks -- it's great at code & agentic workflows, and continues Gemini's multimodal excellence
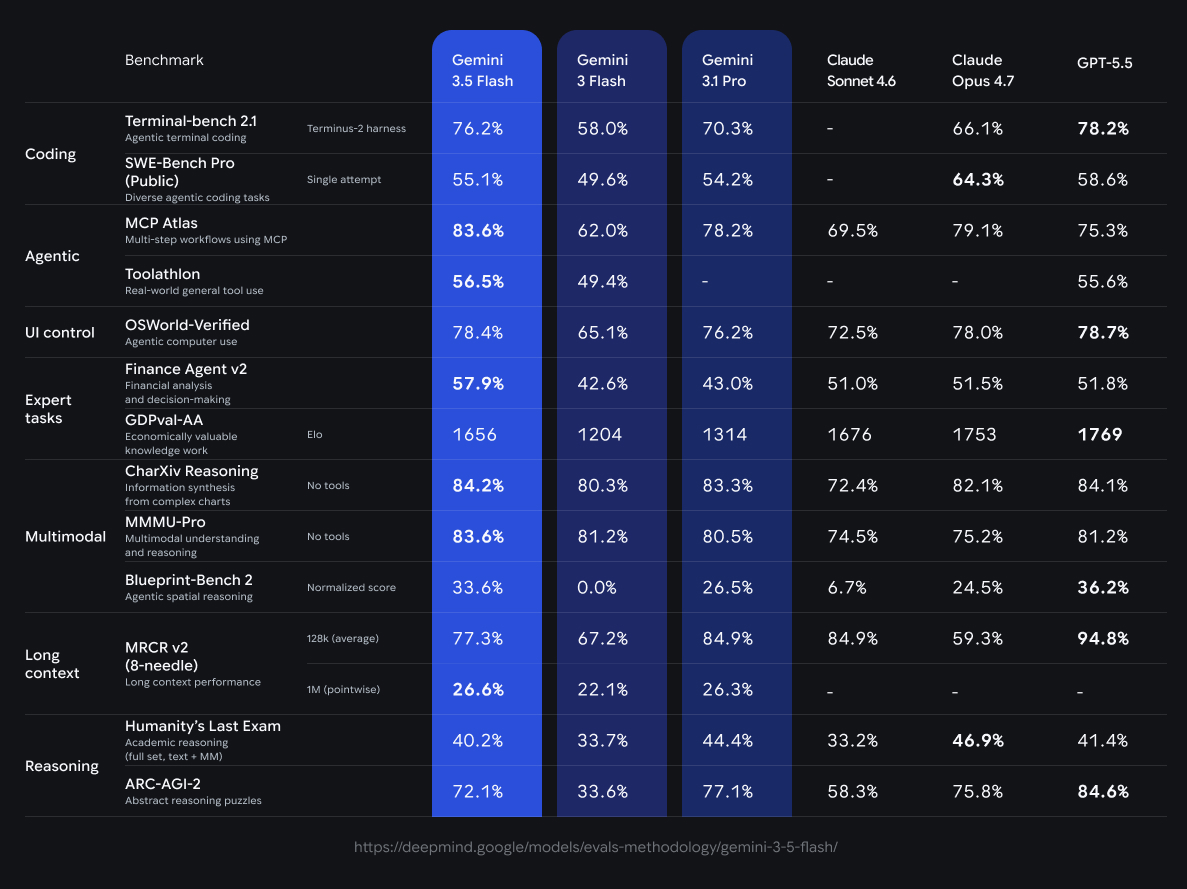
(1/4) Gemini 3.5 Flash is in a league of it's own! ⚡️ It's the perfect combo of intelligence, speed, & cost. It's now my daily driver in both Spark & Antigravity! Watch 3.5 spawn subagents organize a set of marketing assets, rename them, and put them into folders
(4/4) You can try Gemini 3.5 Flash across the Gemini app, AI Mode in Search, the Gemini API, Google AI Studio, Android Studio, and our Enterprise platforms. Can’t wait to see what you build! ✨
(3/4) And...did I mention 3.5 Flash is so fast?