Kog AI Hits 3000 Tokens Per Second On 8x AMD MI300X GPUs
Try their Playground → http://playground.kog.ai
Their main technical report/blog - https://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request/
Now, why is 3,000 tokens/s so hard?
At batch size 1, LLM decoding is mostly memory movement, not raw compute. Every new token needs the model’s active weights streamed from high-bandwidth memory, and at this speed the whole system gets only ~333 microseconds per token.
That is why small delays suddenly become huge: a few microseconds lost at every layer can destroy the whole speed target.
I had to test it myself to believe this unreal inference speed. 3,000 tokens/s for 1 user on standard datacenter GPUs. They leveraged a hidden efficiency gap in how GPUs generate tokens. @Kog__AI just achieved 3,000 tokens/s on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding). Their tech preview is on a 2B model, and they show how their techniques will scale to large frontier MoE models at similar speeds. That's a huge number because normal low-batch GPU decoding for 2B to 8B models is usually closer to 100 to 300 tokens/s per request, so Kog is claiming something like a 10X to 30X jump in the speed one user actually feels. Their trick: they are getting the speed by treating LLM decoding as a memory streaming problem, not mainly a math problem. For 1 user at batch size 1, the GPU is not doing big, efficient matrix-matrix work like in training or large-batch serving; it is repeatedly pulling the model’s active weights from high-bandwidth memory for each new token, so speed depends on how smoothly those weights keep flowing. Normal inference stacks keep breaking that flow. They run many separate GPU programs for different parts of the model, move intermediate results through memory, wait at synchronization points, talk back to the CPU for scheduling or sampling, and then repeat this token after token. Kog’s answer is to co-design 3 things that are usually tuned separately: the runtime, the low-level GPU code, and the model architecture. The biggest engineering move is the monokernel, where the whole decode pass runs as 1 persistent GPU-resident program, including sampling, so the system does not keep stopping for kernel launches, CPU scheduling, and intermediate memory round trips. They also rebuilt synchronization, because their own measurements say grid sync was eating around 35% of token-generation time; instead of making every compute unit wait at a broad barrier, each unit waits only for the exact data it needs. On AMD MI300X, they also map memory access around the chiplet layout, because memory latency changes depending on which die makes the request. Then their Laneformer model uses Delayed Tensor Parallelism, which lets cross-GPU communication happen in the background instead of blocking every layer.
The monokernel idea was one of their powerful trick.
Instead of launching many small GPU programs for normalization, attention, feed-forward layers, sampling, and communication, Kog keeps the whole decode loop inside 1 long-running GPU program.
With a monokernel, weights for the next stage can start loading while the current stage is still finishing, so the GPU behaves more like a pipeline and less like a machine constantly being paused and restarted.
If a Transformer layer is broken into many small GPU programs, the system can burn a scary amount of its budget just stopping, starting, syncing, writing, reloading, and waiting, before doing useful token generation.
The monokernel tries to remove that stop-start behavior.
Once it begins, it stays resident on the GPU and handles the full sequence, including prefill, decode, sampling, tensor-parallel communication, reductions, and internal state, without going back to the CPU for every little step.
The big gain is that weight streaming stays continuous.
For batch-size-1 inference, the GPU mostly needs to stream active model weights from high-bandwidth memory into compute units as smoothly as possible. Read more about their “monokernel” implementation here.

Try their Playground → http://playground.kog.ai Their main technical report/blog - https://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request/ Now, why is 3,000 tokens/s so hard? At batch size 1, LLM decoding is mostly memory movement, not raw compute. Every new token needs the model’s active weights streamed from high-bandwidth memory, and at this speed the whole system gets only ~333 microseconds per token. That is why small delays suddenly become huge: a few microseconds lost at every layer can destroy the whole speed target.
Their grid sync trick is probably the most underrated part.
A normal barrier makes the whole GPU wait, while Kog’s version lets each compute unit wait only for the data it actually depends on.
Instead of forcing the whole GPU to wait at one big barrier, they make each compute unit wait only for the exact value it needs.
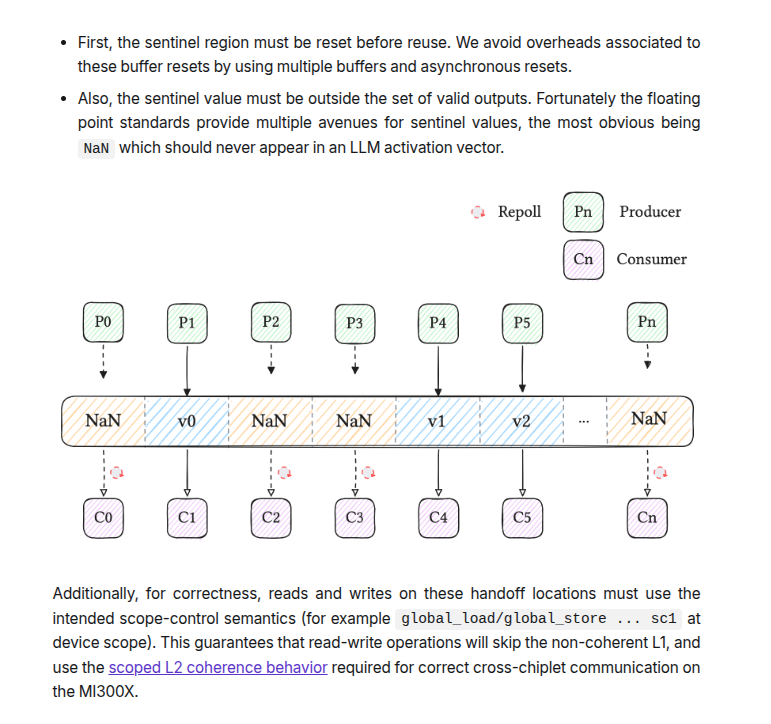
This image is showing their grid sync idea in the simplest way: instead of making the whole GPU wait together, each compute unit checks only the small piece of data it needs.
The NaN boxes mean “not ready yet,” and the v0, v1, v2 boxes mean “real data is ready now.”
So the sync signal is built into the data itself, which is why they can reduce broad waiting and cut grid sync from around 7 microseconds to under 1 microsecond.
Read more about grid sync here -
The monokernel idea was one of their powerful trick. Instead of launching many small GPU programs for normalization, attention, feed-forward layers, sampling, and communication, Kog keeps the whole decode loop inside 1 long-running GPU program. With a monokernel, weights for the next stage can start loading while the current stage is still finishing, so the GPU behaves more like a pipeline and less like a machine constantly being paused and restarted. If a Transformer layer is broken into many small GPU programs, the system can burn a scary amount of its budget just stopping, starting, syncing, writing, reloading, and waiting, before doing useful token generation. The monokernel tries to remove that stop-start behavior. Once it begins, it stays resident on the GPU and handles the full sequence, including prefill, decode, sampling, tensor-parallel communication, reductions, and internal state, without going back to the CPU for every little step. The big gain is that weight streaming stays continuous. For batch-size-1 inference, the GPU mostly needs to stream active model weights from high-bandwidth memory into compute units as smoothly as possible. Read more about their “monokernel” implementation here. https://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus/
Delayed Tensor Parallelism changes the model so cross-GPU communication does not sit directly on the critical path.
Standard tensor parallelism often waits for all GPUs to combine their partial results after a module, but DTP delays that combine step so useful work can continue.
Read more about their “Delayed Tensor Parallelism” here -

Their grid sync trick is probably the most underrated part. A normal barrier makes the whole GPU wait, while Kog’s version lets each compute unit wait only for the data it actually depends on. Instead of forcing the whole GPU to wait at one big barrier, they make each compute unit wait only for the exact value it needs. This image is showing their grid sync idea in the simplest way: instead of making the whole GPU wait together, each compute unit checks only the small piece of data it needs. The NaN boxes mean “not ready yet,” and the v0, v1, v2 boxes mean “real data is ready now.” So the sync signal is built into the data itself, which is why they can reduce broad waiting and cut grid sync from around 7 microseconds to under 1 microsecond. Read more about grid sync here - https://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus/
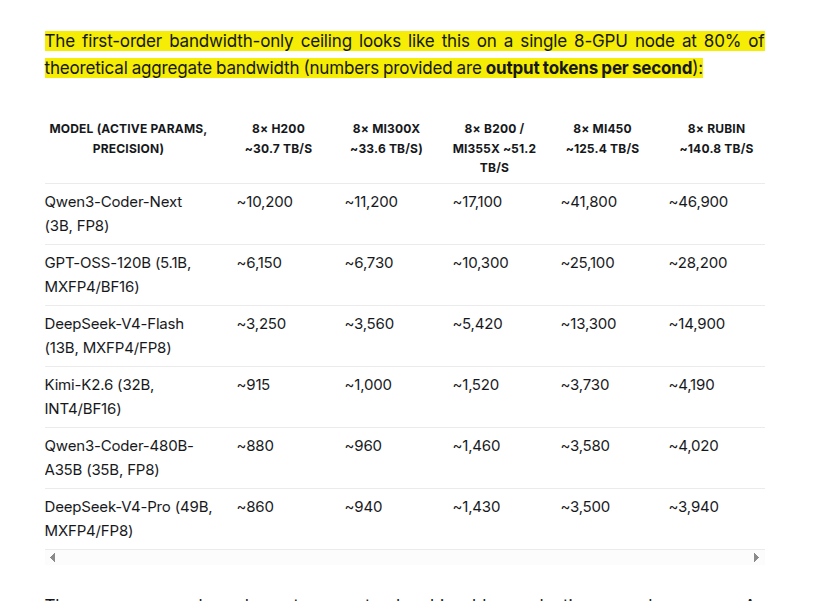
Now what about scaling to other large third-party MoE models
- at batch size 1, GPT-OSS-120B has 5.1B active parameters - in FP8, it's in the same size ballpark than their 2B model in FP16 (5.1 GB vs 4GB), on which their preview experiment was run.
- Similarly, DeepSeek V4 Flash has 13B in mixed FP4/FP8, so let's say ballpark around 3x bigger than 4GB - so Kog could reach >1,000 tok/s on it with MI300X/H200 and up to 4k on next generation GPUs.
Delayed Tensor Parallelism changes the model so cross-GPU communication does not sit directly on the critical path. Standard tensor parallelism often waits for all GPUs to combine their partial results after a module, but DTP delays that combine step so useful work can continue. Read more about their “Delayed Tensor Parallelism” here - https://blog.kog.ai/delayed-tensor-parallelism-for-faster-transformer-inference/
Try it right now on their playground →
Main Blog -
How they did it → http://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request
📖 Monokernel deep dive → http://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus
📖 Delayed Tensor Parallelism research →
Now what about scaling to other large third-party MoE models - at batch size 1, GPT-OSS-120B has 5.1B active parameters - in FP8, it's in the same size ballpark than their 2B model in FP16 (5.1 GB vs 4GB), on which their preview experiment was run. - Similarly, DeepSeek V4 Flash has 13B in mixed FP4/FP8, so let's say ballpark around 3x bigger than 4GB - so Kog could reach >1,000 tok/s on it with MI300X/H200 and up to 4k on next generation GPUs.