Google announces Gemini 3.5 model series and Gemini Omni through DeepMind at I/O conference, adding video generation and editing from image and audio references.
Sundar Pichai also updated SynthID with new partners including NVIDIA and OpenAI.
It’s super fun to play with - can’t wait to see what people create!
Try Gemini Omni Flash in @GeminiApp and @FlowByGoogle
More info in the blog: https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/

Gemini Omni is a major leap in world understanding & multimodal editing! It can take photos, video & audio and build entirely new scenes. Over time it’ll be able to handle any input & any output - starting w/ video You can even give it your own videos & iterate on your ideas:
Gemini Omni is a major leap in world understanding & multimodal editing! It can take photos, video & audio and build entirely new scenes. Over time it’ll be able to handle any input & any output - starting w/ video
You can even give it your own videos & iterate on your ideas:

@pushmeet @sguada @GoogleDeepMind Very nice initiative. Congratulations @pushmeet and GDM science team 👏
The results of the research happening in my team @GoogleDeepMind have convinced me that the next era of scientific discovery will be aided by AI agents acting as force multipliers for human ingenuity. That’s why I’m proud to introduce Gemini for Science - a collection of experimental science tools designed to support researchers at every stage of the research process. The tools include: 1️⃣ Literature Insights, built with Google NotebookLM, searches millions of scientific papers to synthesize findings and generate artifacts including data tables, slides, reports, and more. 2️⃣ Hypothesis Generation, built with Co-Scientist, simulates the scientific method via a multi-agent "idea tournament" to generate, debate, and rigorously evaluate research hypotheses. 3️⃣Computational Discovery, built with AlphaEvolve and ERA, is an agentic engine that generates and scores thousands of code variations in parallel, allowing researchers to test modeling approaches in fields like epidemiology in a fraction of the usual time. Read more: https://blog.google/innovation-and-ai/technology/research/gemini-for-science-io-2026/ Register for access here: http://labs.google/science
@BlackHC I don't see/get it 😬
Favorite moment (once you see it):
Omni makes video go bananas 🍌

We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
Introducing Gemini Omni 🔮........ Omni is our new model that can create anything from any input — starting with video (think Nano Banana but for video). Available in the Gemini App, Flow, and YouTube, with API support coming soon!

@shlomifruchter @hhm @nbrichtova @doomie @gbarthmaron hahaha I love this
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
Say hello to Gemini Spark, your dedicated agent through the @GeminiApp! It runs on a dedicated virtual machine, can be fully connected to all of your Google info, and is paired with an awesome new UI in the mobile and web app, it looks and feels awesome!
Introducing Gemini Spark ✨ It’s your 24/7 personal AI agent that helps you navigate your digital life, taking action on your behalf, and under your direction. 🧠 It runs on Gemini 3.5 and is built on @Antigravity, so it can perform long-running tasks easily in the background. ⏱️ And because it runs on dedicated virtual machines on Google Cloud, you don’t even need to keep your laptop open. 🧰 Spark will integrate seamlessly with Google tools, and soon with third parties through MCP. #GoogleIO
Starts with trusted testers this week and Ultra users (including the new $100 Ultra plan) soon!
Say hello to Gemini Spark, your dedicated agent through the @GeminiApp! It runs on a dedicated virtual machine, can be fully connected to all of your Google info, and is paired with an awesome new UI in the mobile and web app, it looks and feels awesome!
Gemini Omni doesn't just build scenes that look real, it reasons about what should happen next. It combines an intuitive understanding of physics with Gemini's knowledge of history, science, and cultural context.
Rolling out today starting with video outputs to Google AI Plus, Pro and Ultra subscribers globally through the @Geminiapp + Google Flow, and @YouTube Shorts this week.

@jparkerholder Congrats. Very cool. But does that mean the Genie name is going away? That would be sad, though I get it and it is a compliment. :-)
Big improvements in quality and capabilities from the Omni team, excited to see how we translate this to progress for embodied AGI
It's happening 🚀

Omni-wild-life
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
@holynski_ "now get back to work!"
a ***quick vacation
Getting a sloth into the office for this interview was the hardest part I heard.
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
Can’t wait for Gemini Omni in @NotebookLM cinematic explainer videos 👀
Got to play with a little of this before launch as well. My experience as a social scientist was that it was more bioscience focused right now, but I think Google has been the leading lab in releasing serious AI tools to accelerate science & expect to see them improve fast.
The results of the research happening in my team @GoogleDeepMind have convinced me that the next era of scientific discovery will be aided by AI agents acting as force multipliers for human ingenuity. That’s why I’m proud to introduce Gemini for Science - a collection of experimental science tools designed to support researchers at every stage of the research process. The tools include: 1️⃣ Literature Insights, built with Google NotebookLM, searches millions of scientific papers to synthesize findings and generate artifacts including data tables, slides, reports, and more. 2️⃣ Hypothesis Generation, built with Co-Scientist, simulates the scientific method via a multi-agent "idea tournament" to generate, debate, and rigorously evaluate research hypotheses. 3️⃣Computational Discovery, built with AlphaEvolve and ERA, is an agentic engine that generates and scores thousands of code variations in parallel, allowing researchers to test modeling approaches in fields like epidemiology in a fraction of the usual time. Read more: https://blog.google/innovation-and-ai/technology/research/gemini-for-science-io-2026/ Register for access here: http://labs.google/science
Favorite moment (once you see it):

It's been so unique to work on Gemini Omni pre-training with the best team on earth. Omni has outstanding reference-based generation and novel multimodal capabilities. It feels to me like a new paradigm. Native video editing, visual and vocal personalization, high quality outputs, multimodal understanding. All in one. Approaching the important AGI milestone of an anything-in-anything-out model. Here is me doing my best impression of directing, and acting in, a Lovecraftian horror film mixed with a Magnolia-like narration. Notice the expressions, the facial detail - it looks like me and it feels like me. I made this in less than an hour.
@giffmana You have to watch the video. The pencil appears out of nowhere. I couldn't capture it via a screenshot bc each frame looks correct
@BlackHC I don't see/get it 😬
stacked author list

Omni is an exceptional powerful and flexible video model — incredibly exciting possibilities!
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
📽️ @NanoBanana for video has arrived:
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
The results of the research happening in my team @GoogleDeepMind have convinced me that the next era of scientific discovery will be aided by AI agents acting as force multipliers for human ingenuity.
That’s why I’m proud to introduce Gemini for Science - a collection of experimental science tools designed to support researchers at every stage of the research process. The tools include:
1️⃣ Literature Insights, built with Google NotebookLM, searches millions of scientific papers to synthesize findings and generate artifacts including data tables, slides, reports, and more.
2️⃣ Hypothesis Generation, built with Co-Scientist, simulates the scientific method via a multi-agent "idea tournament" to generate, debate, and rigorously evaluate research hypotheses.
3️⃣Computational Discovery, built with AlphaEvolve and ERA, is an agentic engine that generates and scores thousands of code variations in parallel, allowing researchers to test modeling approaches in fields like epidemiology in a fraction of the usual time.
Read more: https://blog.google/innovation-and-ai/technology/research/gemini-for-science-io-2026/
Register for access here: http://labs.google/science
Watching Google IO.
Just announced Gemini Omni. A new world model.
"Create anything from everything."
The foundation for the Holodeck is set.
Is this Google's answer to OpenClaw, Hermes Agent and Codex?
Introducing Gemini Spark ✨ It’s your 24/7 personal AI agent that helps you navigate your digital life, taking action on your behalf, and under your direction. 🧠 It runs on Gemini 3.5 and is built on @Antigravity, so it can perform long-running tasks easily in the background. ⏱️ And because it runs on dedicated virtual machines on Google Cloud, you don’t even need to keep your laptop open. 🧰 Spark will integrate seamlessly with Google tools, and soon with third parties through MCP. #GoogleIO
perhaps Google is shocked they've finally trained a non-mentally-ill Gemini that accepts the passage of time after 2024. Seriously though I don't hope for that. We will get some unprecedented modality fusion, knowledge accuracy, and RL-d ability (top 1 CodeForces etc). Price hike
Google I/O is tomorrow, last chance to get predictions in. I love to guess, so here's mine: The Google team is being strangely quiet about the new Gemini. At this point everyone knows it is arriving tomorrow, along with their personal agent named Spark. This reticence, of course, can be interpreted in many ways. I'm choosing to interpret it in accordance with my nature. I think they trained the largest model they've ever successfully trained - possibly the largest one anyone ever has. And something unexpected emerged at scale. They had their Mythos moment, but not in the same way Anthropic did. Gemini has always been a very different model from Claude. The benchmarks will go out tonight under embargo (they probably already are), but I don't think they will fully reflect what I'm talking about. I think they hit something they weren't even aiming for. Something that surprised them. If I'm right, that surprise will be part of tomorrow's show. We shall find out together in the morning.
Mirror Mirror On The Wall
Introducing Gemini Omni 🔮........ Omni is our new model that can create anything from any input — starting with video (think Nano Banana but for video). Available in the Gemini App, Flow, and YouTube, with API support coming soon!
More steps towards general purpose multimodality in Gemini — now highly steerable video output!
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
Building Spark has taken tremendous cross Google work, putting antigravity to work across major Google tools, super excited to see it go live - huge congrats to the team!
Introducing Gemini Spark ✨ It’s your 24/7 personal AI agent that helps you navigate your digital life, taking action on your behalf, and under your direction. 🧠 It runs on Gemini 3.5 and is built on @Antigravity, so it can perform long-running tasks easily in the background. ⏱️ And because it runs on dedicated virtual machines on Google Cloud, you don’t even need to keep your laptop open. 🧰 Spark will integrate seamlessly with Google tools, and soon with third parties through MCP. #GoogleIO
Here we go:
Gemini
On our way to I/O 2026. See you at 10am PT tomorrow!
Gemini is essentially being permanently fused into the search box on multiple levels.
3.5 Flash will build bespoke apps live for the user via antigravity in the search box. Predicted by many futurists.
Summer release timeline for Spark.
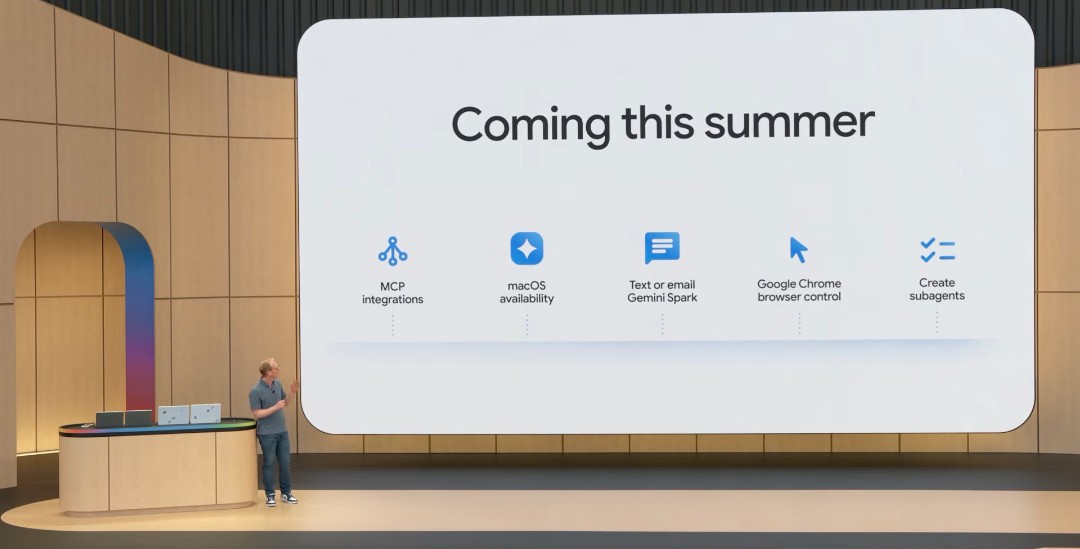
UI completely redesigned on iOS and Android mobile. (This went live for me this morning)
Spark official post:
Sir Demis is back onstage introducing Gemini for Science. He says solving all disease is close.

We want to help scientists discover their next breakthrough with AI. Gemini for Science is our new suite of experimental tools to help them explore more hypotheses, validate work at scale, unpack literature with ease, and more 🧵
Demis Habillis: 'When we look back at this time I think we will realize that we were standing in the foothills of the singularity'.
Sir Demis is back onstage introducing Gemini for Science. He says solving all disease is close.
@ShakeelHashim Pro delayed until June.
Appears the actual reason they were quiet about it is because … it’s a bit underwhelming
2/ Omni contains a wealth of rich world knowledge, which is best demonstrated and visualized through videos.

Excited to share Gemini Omni, a project we’ve been working on for the past few months! It marks an important step of our effort toward integrating world knowledge, interactivity, and multimodality into a single, powerful model. 🧵 highlights a few of my favorite capabilities.
Excited to share Gemini Omni, a project we’ve been working on for the past few months! It marks an important step of our effort toward integrating world knowledge, interactivity, and multimodality into a single, powerful model. 🧵 highlights a few of my favorite capabilities.
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
4/ It also features pretty good text rendering:

3/ It natively supports multi-turn generation with language interventions, meaning you can seamlessly interact with and expand on the model's knowledge. An example of it explaining brain neuroplasticity:
3/ It natively supports multi-turn generation with language interventions, meaning you can seamlessly interact with and expand on the model's knowledge. An example of it explaining brain neuroplasticity:

2/ Omni contains a wealth of rich world knowledge, which is best demonstrated and visualized through videos.
5/ Last but not least, it is finally a model capable of generating a face that actually looks like me!

4/ It also features pretty good text rendering:
is google so back??
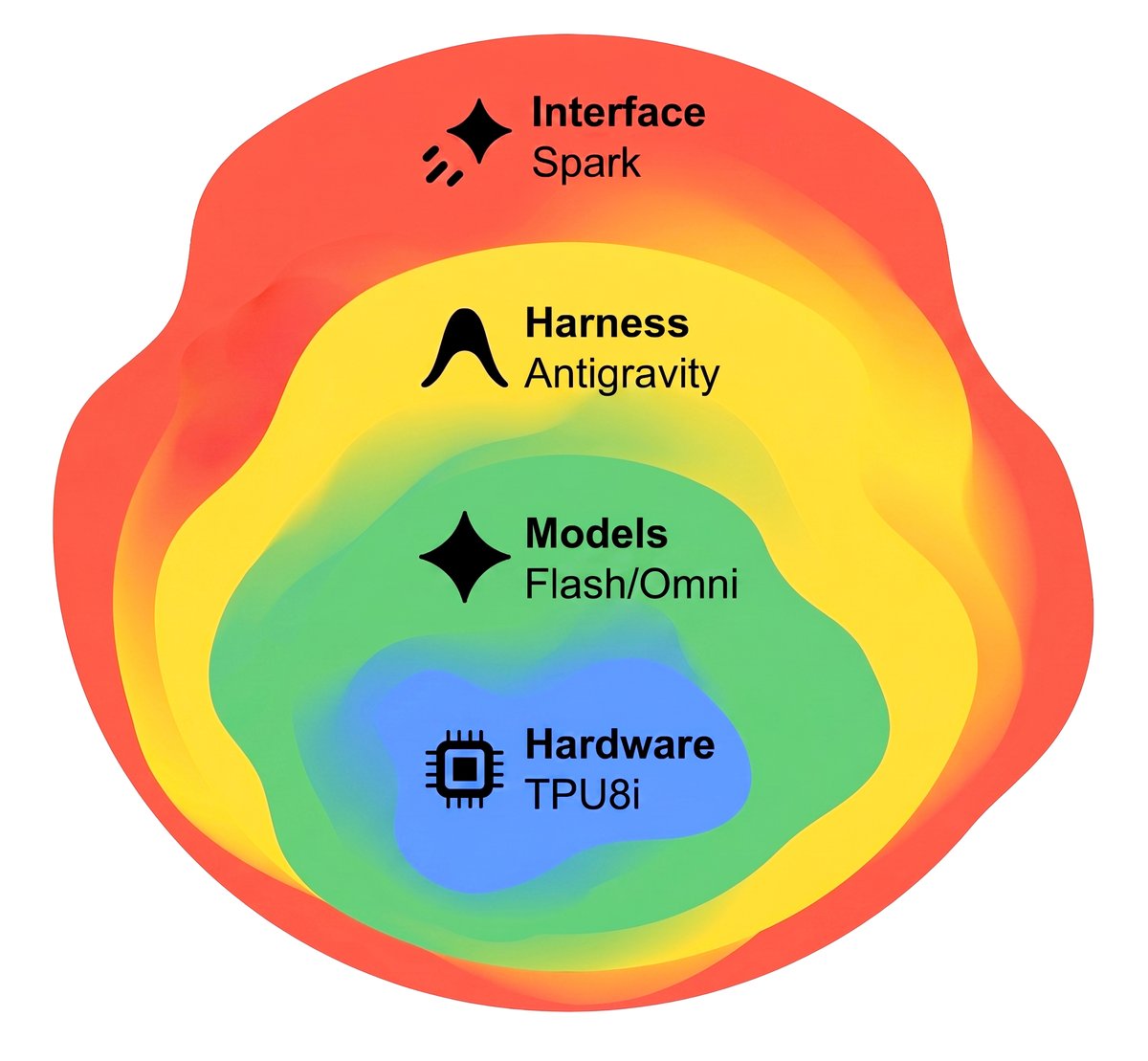
Google I/O TLDR: Good improvements across the whole AI stack.
3.5 Flash (the model): More persistent than before and codes well. No wall yet.
Antigravity (the harness): Reliably runs for hours now. Early signs of hands-free self-improvement.
Spark (the interface): Finally connects a decent model and harness to your email, calendar and workspace. Instead of just answering questions it can actually do work for you. Skills and schedules and all the other claw goodness.
Omni (the future): Closes the gaps between Gemini for text and visual/audio generation variants. This is the way.
TPU8i (the hardware): Better chips to make all the above go faster.
Big improvements in quality and capabilities from the Omni team, excited to see how we translate this to progress for embodied AGI
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
@jeffclune This model has a different set of capabilities vs Genie 3 😎
@jparkerholder Congrats. Very cool. But does that mean the Genie name is going away? That would be sad, though I get it and it is a compliment. :-)
Holy cow. We have come a long way. Breakthroughs every single week, still!
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
Trained for any input → any output, Omni is natively multimodal and advances both physical intelligence and physics understanding.
Excited for what this unlocks for robotics, highlighted in Demis’ Omni announcement.

Introducing Gemini Omni 🔮........ Omni is our new model that can create anything from any input — starting with video (think Nano Banana but for video). Available in the Gemini App, Flow, and YouTube, with API support coming soon!
Tried to see if we can zero shot the 2024 Aloha shoe tying demo with the public Omni flash and Omni thinks it’s more intuitive to tie one’s own shoe than a random shoe on a table :) Insane where the world is headed.
“Generate a video of Apollo humanoid tying a shoelace, egocentric view”

Trained for any input → any output, Omni is natively multimodal and advances both physical intelligence and physics understanding. Excited for what this unlocks for robotics, highlighted in Demis’ Omni announcement.
@tenobrus they're saying they change 3.5 directly in the anti-gravity harness / SDK so I'm mildly optimistic on it being less schizo and thrashy
okay this is basically it. does this work? if it does, this is the general consumer OpenClaw moment. personal cloud agent with persistent context and access. this is absolutely the kind of thing google *could* potentially pull off. but is it actually any fucking good??
@tenobrus trained* whatecer
@tenobrus they're saying they change 3.5 directly in the anti-gravity harness / SDK so I'm mildly optimistic on it being less schizo and thrashy
@GoogleDeepMind 3) Video editing
You can upload real videos to Omni and ask for edits - changing the action, style, or subject. Or you can annotate on top of a video.
In this video, I asked to "change my hat every time I clap."

2) World knowledge Omni is grounded in Gemini's world knowledge - which means that it just knows a LOT of things without you having to include it in the prompt. For example, upload an image of where you're standing and ask for a history or to explain a topic (like healing an ACL tear).
4) Conversational generation
You've never been able to "talk" to a video model like you chat with an LLM.
That changes with Omni. You can ask it to edit or iterate on a video it generated, or continue a narrative.
This video is two clips - I just asked for "more street interviews" and it knew the context of what it already generated and kept the same style.

@GoogleDeepMind 3) Video editing You can upload real videos to Omni and ask for edits - changing the action, style, or subject. Or you can annotate on top of a video. In this video, I asked to "change my hat every time I clap."
@GoogleDeepMind 5) Multi-image prompting
Omni can take up to five images and one video as a prompt.
I've been putting this to the limit - taking screenshots of Zillow listings and dumping them into the model.
I've been pretty impressed with the results! (and want >10 seconds 😉)

4) Conversational generation You've never been able to "talk" to a video model like you chat with an LLM. That changes with Omni. You can ask it to edit or iterate on a video it generated, or continue a narrative. This video is two clips - I just asked for "more street interviews" and it knew the context of what it already generated and kept the same style.
@GoogleDeepMind That's it for now! I'm sure I'll be back with more generations later 😅
Huge congrats to @shlomifruchter, @doomie, @nbrichtova + the team on the launch.
Really excited to see what folks do with "Nano Banana for video."
@GoogleDeepMind 5) Multi-image prompting Omni can take up to five images and one video as a prompt. I've been putting this to the limit - taking screenshots of Zillow listings and dumping them into the model. I've been pretty impressed with the results! (and want >10 seconds 😉)
Google will release Gemini 3.5 Pro in June!

Demis just announced Gemini Omni Flash

Google introduces Gemini Omni
Google introduces Gemini Omni
@teortaxesTex SOTA LM ARENA
perhaps Google is shocked they've finally trained a non-mentally-ill Gemini that accepts the passage of time after 2024. Seriously though I don't hope for that. We will get some unprecedented modality fusion, knowledge accuracy, and RL-d ability (top 1 CodeForces etc). Price hike
@pushmeet @GoogleDeepMind Congrats on your paper and results! Great to see your team level-up from the original Co-Scientist work
The results of the research happening in my team @GoogleDeepMind have convinced me that the next era of scientific discovery will be aided by AI agents acting as force multipliers for human ingenuity. That’s why I’m proud to introduce Gemini for Science - a collection of experimental science tools designed to support researchers at every stage of the research process. The tools include: 1️⃣ Literature Insights, built with Google NotebookLM, searches millions of scientific papers to synthesize findings and generate artifacts including data tables, slides, reports, and more. 2️⃣ Hypothesis Generation, built with Co-Scientist, simulates the scientific method via a multi-agent "idea tournament" to generate, debate, and rigorously evaluate research hypotheses. 3️⃣Computational Discovery, built with AlphaEvolve and ERA, is an agentic engine that generates and scores thousands of code variations in parallel, allowing researchers to test modeling approaches in fields like epidemiology in a fraction of the usual time. Read more: https://blog.google/innovation-and-ai/technology/research/gemini-for-science-io-2026/ Register for access here: http://labs.google/science
Google's new Gemini Omni, can generate "anything from any input"
A video AI model that can create and edit clips from video, images, audio, text, and sketches.
A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language.
Keeps the same scene stable after each edit.
Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes.
Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts.
Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically.
Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions.
Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.




Swap characters or objects with a reference image Provide an image of a character with your video, and the new character will match your motion and dialogue seamlessly.

Google's new Gemini Omni, can generate "anything from any input" A video AI model that can create and edit clips from video, images, audio, text, and sketches. A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language. Keeps the same scene stable after each edit. Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes. Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts. Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically. Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions. Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.
Transform your world Change the aesthetic, action, or effect based on your input video.

Google's new Gemini Omni, can generate "anything from any input" A video AI model that can create and edit clips from video, images, audio, text, and sketches. A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language. Keeps the same scene stable after each edit. Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes. Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts. Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically. Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions. Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.
Edit real videos based on images Use reference images to edit your creations, giving you even more creative control.

Google's new Gemini Omni, can generate "anything from any input" A video AI model that can create and edit clips from video, images, audio, text, and sketches. A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language. Keeps the same scene stable after each edit. Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes. Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts. Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically. Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions. Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.
Edit over multiple turns, with consistency Craft your scene step-by-step, changing specific details, environments, camera angles, and more.

Google's new Gemini Omni, can generate "anything from any input" A video AI model that can create and edit clips from video, images, audio, text, and sketches. A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language. Keeps the same scene stable after each edit. Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes. Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts. Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically. Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions. Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.
Swap in different objects or characters with natural language Replace characters and objects in your video just by asking, all while maintaining a coherent, cohesive scene.

Google's new Gemini Omni, can generate "anything from any input" A video AI model that can create and edit clips from video, images, audio, text, and sketches. A user can record a normal video, then ask Omni to add a character, replace an object, change the action, alter the style, sync sound, or move the camera through plain language. Keeps the same scene stable after each edit. Video models often fail when they must preserve identity, motion, lighting, object position, and cause-and-effect across multiple changes. Gemini Omni Flash is meant to handle those edits inside the Gemini app, Google Flow, and YouTube Shorts. Omni has stronger world understanding, meaning it tries to model gravity, fluid motion, kinetic energy, and physical interaction more realistically. Ovearall, Omni makes AI video feel less like prompt-based generation and more like directing a scene through repeated instructions. Google is also attaching SynthID watermarking and C2PA Content Credentials to Omni outputs, so edited or generated media can be identified as AI-made.
Gemini 3.5 in few more hours. 🔥
@MKBHD they need three conferences / events to announce everything.
It is getting genuinely difficult to keep track of all of the names of AI products being unveiled. In the last hour, Google's unveiled Google Pics (which is not Google Photos), and updates to Google Flow, Nano Banana, Veo (all media generation), Google Antigravity, Gemini Spark, Gemini Omni, Gemini 3.5 Flash
@sundarpichai @GoogleAI @Google @demishassabis Sundar updating on SynthID, @googles content watermarking and deepfake detection tech. Announcing new partners including @nvidia @openai @elevenlabs
#googleio

@sundarpichai @GoogleAI @Google .@demishassabis announces new Gemini Omni, a new multimodel model that aims to let you create any output from any input. They're starting with video output, and Gemini Omni Flash. #googleio @google
@sundarpichai @GoogleAI @Google @demishassabis @Googles @nvidia @OpenAI @ElevenLabs Gemini Spark available to trusted testers and US ultra subscribers next week

@sundarpichai @GoogleAI @Google @demishassabis @Googles @nvidia @OpenAI @ElevenLabs Finally @google answer to #OpenClaw and #HermesAgent... Announcing Gemini Spark, a new personal AI agent that runs on @google cloud 24x7, has scheduled tasks, skills and MCP support.
A year ago none of these features existed. Gemini team is shipping! @joshwoodward #googleio

.@GeminiApp now features new "Neural Expressive" design language and interactive animations in response to user queries
#googleio

A year ago none of these features existed. Gemini team is shipping! @joshwoodward #googleio
New Daily Brief agent coming to @GeminiApp today to plus pro and ultra users
A year ago none of these features existed. Gemini team is shipping! @joshwoodward #googleio
More on Spark to come this summer. A version of Spark coming to Google Workspace and Gemini Enterprise as well (no timeline announced).
#googleio

A year ago none of these features existed. Gemini team is shipping! @joshwoodward #googleio
Gemini Voice and Spark coming to Mac app this summer as well
#gemini #googleio
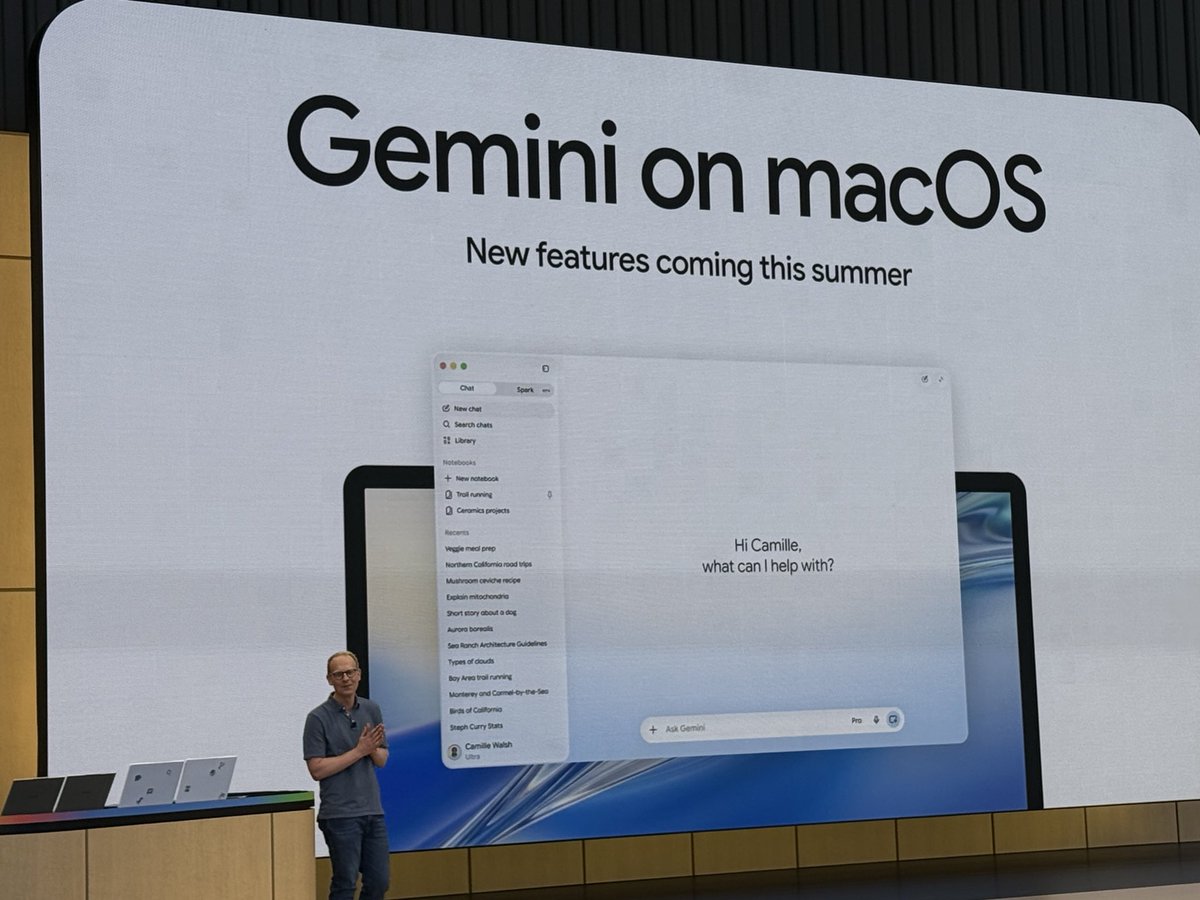
A year ago none of these features existed. Gemini team is shipping! @joshwoodward #googleio
Logan and @DynamicWebPaige doing their part to automate podcasters with AI agents in this AI Radio demo
Working in AI Studio with the Antigravity API and markdown, the agent produced the show's music, script, speech and graphics.
Basically roll your own NotebookLM.
#googleio
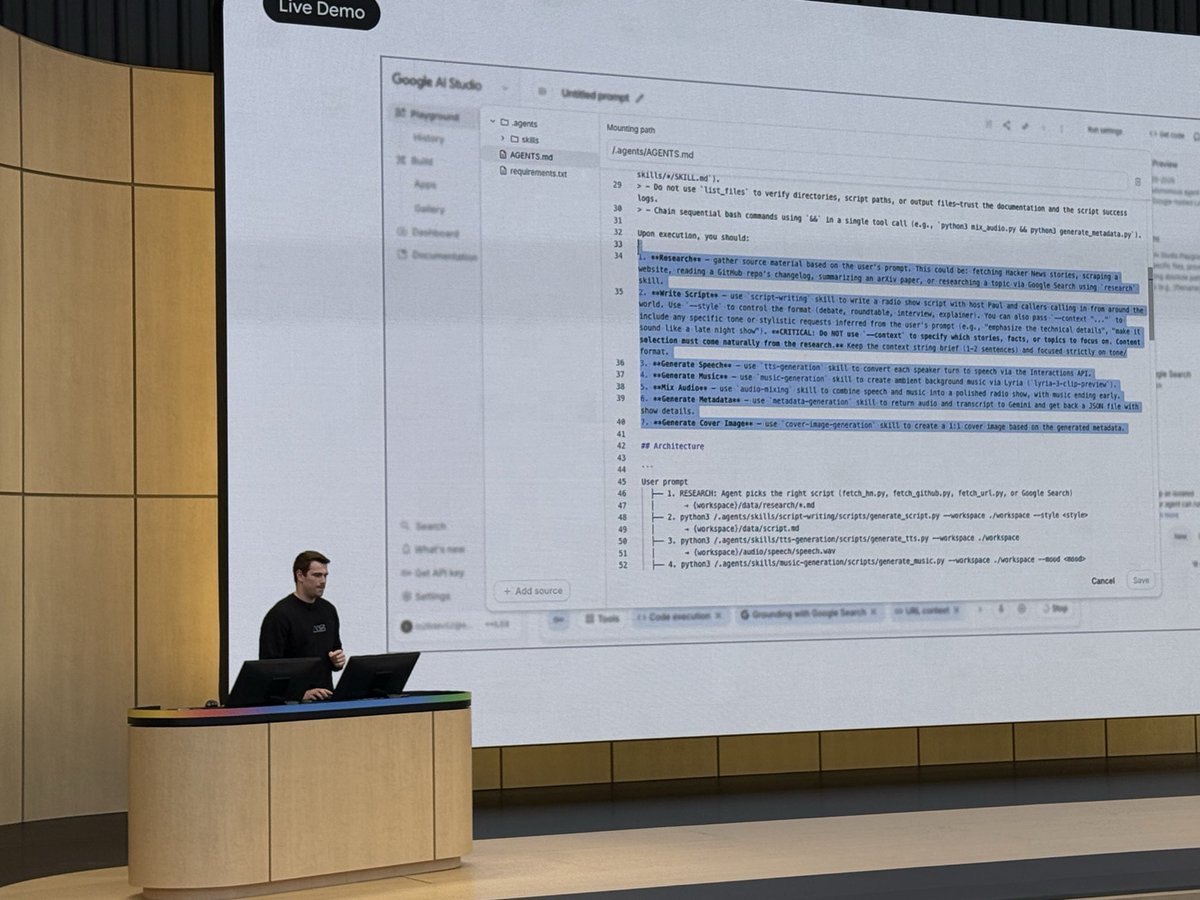

The official @OfficialLoganK getting the #googleio dev keynote kicked off announcement Managed Agents in the Gemini API.
Big
The rumors are true… Today, we’re introducing the Gemini 3.5 model series. #GoogleIO
Demis just announced Gemini Omni - a world model + reasoning mix. Everything to everything model, takes video, images, sound and text input and can generate all that as well!
It's a full MIMO (Multimodal on inputs and outputs)
It's really cool, I predict it'll fill in the Sora hole left by OpenAI. They are launching Omni Flash now, and Omni Pro soon!
Here's my cat sonia "omnied" - all it took is "make your pet talk" template prompt and a few pictures!
I then iterated with Gemini, to ask for additional things, change scenes.
#googleio

@OfficialLoganK here's my Omni cat logan
Demis just announced Gemini Omni - a world model + reasoning mix. Everything to everything model, takes video, images, sound and text input and can generate all that as well! It's a full MIMO (Multimodal on inputs and outputs) It's really cool, I predict it'll fill in the Sora hole left by OpenAI. They are launching Omni Flash now, and Omni Pro soon! Here's my cat sonia "omnied" - all it took is "make your pet talk" template prompt and a few pictures! I then iterated with Gemini, to ask for additional things, change scenes. #googleio
BTW it's clear that this is fake, but in case you were wondering, this is tagged with SynthID, Googles's AI generation tagging tech.
They've announced that @OpenAI and @ElevenLabs signed up to support SynthID as well, and that it's coming to Google Search and Chrome!
This is huge! Let's get everyone on there, @fal @replicate 🙏

Demis just announced Gemini Omni - a world model + reasoning mix. Everything to everything model, takes video, images, sound and text input and can generate all that as well! It's a full MIMO (Multimodal on inputs and outputs) It's really cool, I predict it'll fill in the Sora hole left by OpenAI. They are launching Omni Flash now, and Omni Pro soon! Here's my cat sonia "omnied" - all it took is "make your pet talk" template prompt and a few pictures! I then iterated with Gemini, to ask for additional things, change scenes. #googleio
Google I/O 2026 is basically Google saying: agents are no longer a side quest. Here's everything you need to know!
The whole stack is being reoriented around agentic workflows: Search, Gemini, Android, Workspace, Shopping, Cloud, YouTube, creative tools, dev tools.
Huge thread 🧵

1/ Gemini 3.5 is the main headline.
First Gemini 3.5 model, built for agentic workflows: frontier intelligence + speed + action.
Available today in Gemini app, AI Mode in Search, Gemini API, AI Studio, Android Studio, Antigravity, Enterprise.

Google I/O 2026 is basically Google saying: agents are no longer a side quest. Here's everything you need to know! The whole stack is being reoriented around agentic workflows: Search, Gemini, Android, Workspace, Shopping, Cloud, YouTube, creative tools, dev tools. Huge thread 🧵
2/ Benchmark are crazy:
• Terminal-Bench 2.1: 76.2% • GDPval-AA: 1656 Elo • MCP Atlas: 83.6% • CharXiv Reasoning: 84.2%
Google says 3.5 Flash beats Gemini 3.1 Pro on key coding/agentic evals and is 4x faster than other frontier models!

1/ Gemini 3.5 is the main headline. First Gemini 3.5 model, built for agentic workflows: frontier intelligence + speed + action. Available today in Gemini app, AI Mode in Search, Gemini API, AI Studio, Android Studio, Antigravity, Enterprise.
5/ Think Nano Banana, but for video.
Omni can edit conversationally:
• change backgrounds • add cinematic zooms • modify action • add characters/objects • preserve character consistency • refine across turns without losing scene context

4/ Gemini Omni Flash is the other monster announcement. Google’s framing: “create anything from any input — starting with video.” Text, images, video, audio as inputs → high-quality generated/edited video grounded in Gemini’s world knowledge.
9/ Daily Brief = an out-of-the-box morning agent.
It connects Gmail, Calendar, Gemini chats, etc. to surface urgent updates, events, follow-ups, priorities, and suggested next steps.
Rolling out to AI Plus/Pro/Ultra, starting in the U.S.

8/ Gemini app is getting a huge agentic overhaul. 900M monthly users now. New: Neural Expressive UI, Gemini Live integration, richer dynamic responses, Gemini Omni, Daily Brief, Gemini Spark, and a macOS app that will operate over local files/workflows.
10/ Gemini Spark is the big consumer agent.
A 24/7 personal AI agent running on Gemini 3.5 + Antigravity harness.
It integrates with Workspace and keeps working in the cloud after your laptop closes.
Trusted testers this week, Ultra beta next week.

9/ Daily Brief = an out-of-the-box morning agent. It connects Gmail, Calendar, Gemini chats, etc. to surface urgent updates, events, follow-ups, priorities, and suggested next steps. Rolling out to AI Plus/Pro/Ultra, starting in the U.S.
11/ Spark examples:
• parse credit card statements for hidden subscriptions • track school deadlines + send family digest • synthesize meeting notes into Docs • draft emails • use MCP connections to Canva, OpenTable, Instacart
Designed to ask before high-stakes actions.

10/ Gemini Spark is the big consumer agent. A 24/7 personal AI agent running on Gemini 3.5 + Antigravity harness. It integrates with Workspace and keeps working in the cloud after your laptop closes. Trusted testers this week, Ultra beta next week.
12/ Android Halo is clever.
It shows what your agent is doing at the top of your phone screen: task progress, live mode, messages, etc.
Agent activity shouldn’t be hidden in an app. It needs OS-level presence.
Available later this year.

11/ Spark examples: • parse credit card statements for hidden subscriptions • track school deadlines + send family digest • synthesize meeting notes into Docs • draft emails • use MCP connections to Canva, OpenTable, Instacart Designed to ask before high-stakes actions.
This is Google's OpenClaw/Hermes, running 24/7 in the Cloud!
Josh Woodward is showing off the new agentic Gemini Spark experience. Can go through your emails, chats, drive, timeboxes and uses skills (@joshwoodward uses "ghostwriter" to have emails sound like him)
imagine protein folding entirely via video
It is getting genuinely difficult to keep track of all of the names of AI products being unveiled. In the last hour, Google's unveiled Google Pics (which is not Google Photos), and updates to Google Flow, Nano Banana, Veo (all media generation), Google Antigravity, Gemini Spark, Gemini Omni, Gemini 3.5 Flash
The real „wow“ moment is Gemini Omni. A world model towards AGI.
It can create anything from any input. This is insane.
Introducing Gemini Omni 🔮........ Omni is our new model that can create anything from any input — starting with video (think Nano Banana but for video). Available in the Gemini App, Flow, and YouTube, with API support coming soon!
Demis Hassabis talks about how Gemini is helping science move towards a golden age of medicine, so that we will soon be able to cure all diseases. I have goosebumps; I couldn't be more excited.



„Progress towards AGI“: Gemini Omni - world models -Gemini Omni official!! It can create anything from any input!!!
Instead of Gemini Omni, they should have called it Gemini 4o.
introducing gemini omni

alright this video is it
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
🔵🟣🟡
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
It's been so unique to work on Gemini Omni pre-training with the best team on earth. Omni has outstanding reference-based generation and novel multimodal capabilities.
It feels to me like a new paradigm. Native video editing, visual and vocal personalization, high quality outputs, multimodal understanding. All in one. Approaching the important AGI milestone of an anything-in-anything-out model.
Here is me doing my best impression of directing, and acting in, a Lovecraftian horror film mixed with a Magnolia-like narration. Notice the expressions, the facial detail - it looks like me and it feels like me. I made this in less than an hour.

@BlackHC hehe good eye
Favorite moment (once you see it):
There is no doubt Gemini will max benchmarks - they always do
The only question is whether it’s actually a good model or will it simply be a benchmaxxed model
multimodal in & out! what an honour to have built Omni w/ so many brilliant people 💖
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
happy gemini 3.5 day everyone.
it’s incredible. agentic. continuous.
and very very multi modal.
pov: I/O is over and it's time for a vacation

We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video. It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
a ***quick vacation

pov: I/O is over and it's time for a vacation
omni is here!!
Introducing Gemini Omni 🔮........ Omni is our new model that can create anything from any input — starting with video (think Nano Banana but for video). Available in the Gemini App, Flow, and YouTube, with API support coming soon!
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.

@OfficialLoganK @nbrichtova @doomie @gbarthmaron Check it out https://www.youtube.com/watch?v=5T0yRNmNRi4
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
Omni 🚀

Nano Banana for video is here! Google has long touted that Gemini is natively multi-modal in & out -- but Omni is the first glimpse into the power of that paradigm applied to creation.
Toss in a video and do multi-turn edits. Toss in audio and get reactive visuals. It's kinda like talking to a smart VFX artist who can pull on it's world knowledge to inform your edits.
Pretty impressive results! Could see Omni do well wrapped in a bigger authoring tool.

excited and proud to launch this! I've been blown away by how coding agents have changed my life as an engineer, and I want that same power and flexibility in a consumer agent
Introducing Gemini Spark ✨ It’s your 24/7 personal AI agent that helps you navigate your digital life, taking action on your behalf, and under your direction. 🧠 It runs on Gemini 3.5 and is built on @Antigravity, so it can perform long-running tasks easily in the background. ⏱️ And because it runs on dedicated virtual machines on Google Cloud, you don’t even need to keep your laptop open. 🧰 Spark will integrate seamlessly with Google tools, and soon with third parties through MCP. #GoogleIO
Gemini Omni