Kog Delivers 3,000 Tokens Per Second LLM Inference On Standard GPUs
Some truly massive inference numbers here.
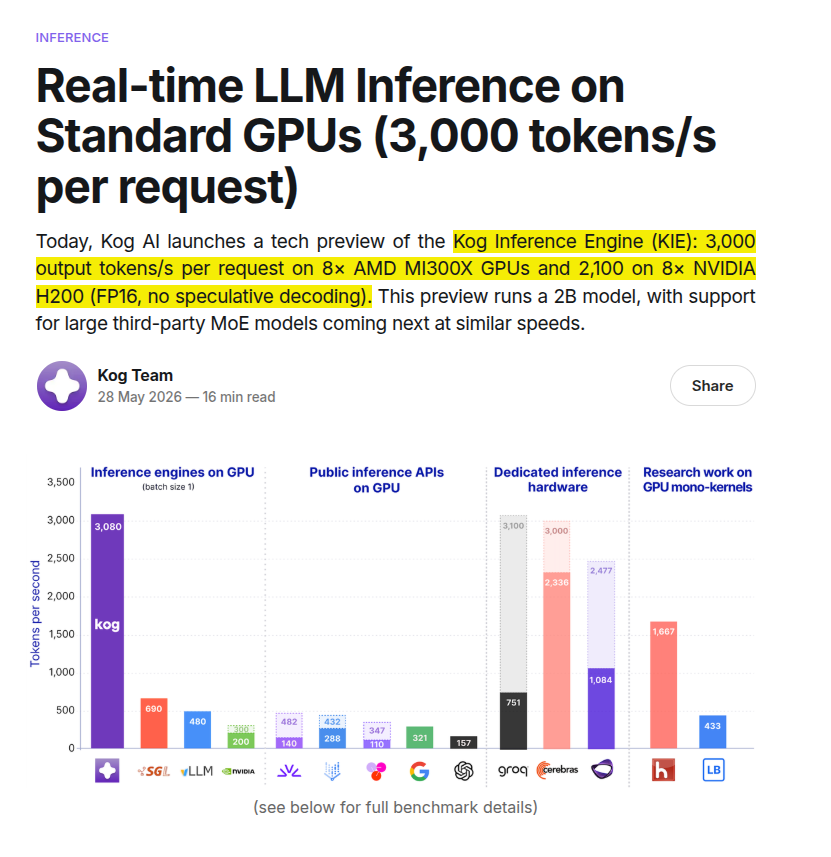
@Kog__AI just achieved 3,000 tokens/s on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding) with a 2B model.
For comparison, typical GPU decoding speed for 2B to 8B models on high-end GPUs is around 100 to 300 tokens/s per sec.
They achieved it by treating LLM decoding as a memory-streaming problem: keep the whole token-generation loop inside one persistent GPU program, so kernel launches, CPU scheduling, intermediate memory writes, and sampling interruptions mostly disappear.
Then they cut synchronization waste by making each compute unit wait only for the exact data it needs, while mapping memory access to the MI300X’s chiplet topology so the GPU stops paying avoidable cross-die latency.
Finally, their model architecture delays tensor-parallel communication so all-reduce work happens in the background instead of blocking every layer, which is why the runtime, GPU code, and model design all have to be co-designed.
🚀 Launch today: Kog generates 3,000+ output tokens/s per single request, on standard datacenter GPUs. We are bringing real-time LLM inference to hardware that companies already run in production. The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X. Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next. Try our Playground → http://playground.kog.ai 💥 Why that matters, and how we did it → http://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request 📖 Monokernel deep dive → http://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus 📖 Delayed Tensor Parallelism research → http://blog.kog.ai/delayed-tensor-parallelism-for-faster-transformer-inference read the thread 👇
Try their Playground → http://playground.kog.ai
- How they did it → http://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request
📖 Monokernel deep dive → http://blog.kog.ai/building-a-single-kernel-latency-optimized-llm-inference-engine-on-amd-mi300x-gpus
📖 Delayed Tensor Parallelism research → https://blog.kog.ai/delayed-tensor-parallelism-for-faster-transformer-inference/
Some truly massive inference numbers here. @Kog__AI just achieved 3,000 tokens/s on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding) with a 2B model. For comparison, typical GPU decoding speed for 2B to 8B models on high-end GPUs is around 100 to 300 tokens/s per sec. They achieved it by treating LLM decoding as a memory-streaming problem: keep the whole token-generation loop inside one persistent GPU program, so kernel launches, CPU scheduling, intermediate memory writes, and sampling interruptions mostly disappear. Then they cut synchronization waste by making each compute unit wait only for the exact data it needs, while mapping memory access to the MI300X’s chiplet topology so the GPU stops paying avoidable cross-die latency. Finally, their model architecture delays tensor-parallel communication so all-reduce work happens in the background instead of blocking every layer, which is why the runtime, GPU code, and model design all have to be co-designed.