The Grid Launches Beta to Cut AI API Costs by Up to 80%
Most teams are overpaying for inference without realising it. Fixed rate cards have no competitive pressure.
The Grid replaces them with live supply and demand, prices track the market, not a vendor's margin.
The Grid sits in the middle and basically says, “Don’t pick the model, pick the level of work you need.”
A boring task like classifying support tickets does not need the smartest model, so it can run on standard.
A normal production task like RAG, drafting, support replies, or agent steps can run on prime.
A hard task with long context, high error cost, or difficult reasoning can run on max.
Your app sends the request to The Grid, not directly to OpenAI, Anthropic, or one hosting company.
The Grid then checks which suppliers currently qualify for that tier and sends the request to the cheapest one available at that moment.
You still use one API key and mostly the same code, but the model behind the request can change as prices and quality change.
So you stop paying premium prices for easy work, and also you are not trapped inside one vendor’s model names, pricing, outages, or deprecations.
New accounts get the first 200 million tokens covered.
Here, I integrated Hermes Agent with The Grid in minutes, kept the agent running locally on my Ubuntu machine, and used “agent-prime” to read support tickets, apply a policy file, and write a triage report through The Grid’s API.
You just need to - install Hermes Agent - select The Grid as a custom AI provider. - No local model download. No GPU setup. The request goes through the grid. - The Hermes Agent ran locally, but the AI calls went through The Grid.
🧵 1.

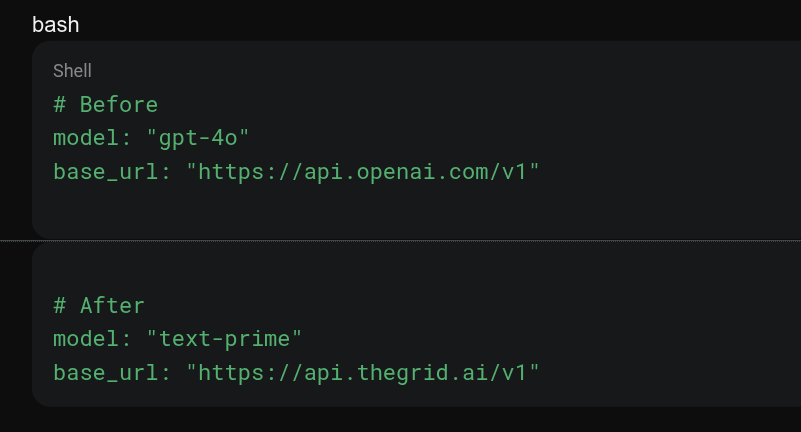
🧵 2. Keep your existing OpenAI or Anthropic client. Swap the base URL and replace the model name with an instrument string like text-prime. That's the entire migration.
Most teams are overpaying for inference without realising it. Fixed rate cards have no competitive pressure. The Grid replaces them with live supply and demand, prices track the market, not a vendor's margin. The Grid sits in the middle and basically says, “Don’t pick the model, pick the level of work you need.” A boring task like classifying support tickets does not need the smartest model, so it can run on standard. A normal production task like RAG, drafting, support replies, or agent steps can run on prime. A hard task with long context, high error cost, or difficult reasoning can run on max. Your app sends the request to The Grid, not directly to OpenAI, Anthropic, or one hosting company. The Grid then checks which suppliers currently qualify for that tier and sends the request to the cheapest one available at that moment. You still use one API key and mostly the same code, but the model behind the request can change as prices and quality change. So you stop paying premium prices for easy work, and also you are not trapped inside one vendor’s model names, pricing, outages, or deprecations. New accounts get the first 200 million tokens covered. Here, I integrated Hermes Agent with The Grid in minutes, kept the agent running locally on my Ubuntu machine, and used “agent-prime” to read support tickets, apply a policy file, and write a triage report through The Grid’s API. You just need to - install Hermes Agent - select The Grid as a custom AI provider. - No local model download. No GPU setup. The request goes through the grid. - The Hermes Agent ran locally, but the AI calls went through The Grid. 🧵 1.
🧵 3. The 3 text tiers and the 3 pricing
- Standard is for high-volume work where cost matters most, like classification, batch summarization, tagging, and simple extraction.
- Prime is the everyday production tier. This is where I’d put agents, RAG, drafting, support workflows, and quality-sensitive pipelines.
- Max is for the harder stuff, like long-context work, high-stakes reasoning, and tasks where a wrong answer can create real downstream cost.
The important part is that “cheapest” does not mean “random cheap model.”
Each tier has a quality threshold. The Grid checks models against benchmark floors anchored to Artificial Analysis. If a supplier falls below the required quality level for a tier, it gets removed from the eligible set. So the market competes on price, but only inside the quality bar you picked.

🧵 2. Keep your existing OpenAI or Anthropic client. Swap the base URL and replace the model name with an instrument string like text-prime. That's the entire migration.
🧵 4. Quality thresholds are anchored to Artificial Analysis benchmarks (Intelligence Index for Text, Coding Index for Code, Agentic Index for Agent).
Suppliers that drift below the threshold for their tier are removed automatically. "Cheapest qualifying offer" is a guarantee, not marketing.
One concern people will naturally have is: “If the system always picks the cheapest qualifying model, won’t quality slowly get worse?”
That would be true if The Grid were just picking the cheapest model blindly.
But that is not how it works.
Each tier has a quality floor. So when you send a request to something like text-prime, The Grid is not saying, “send this to any cheap model.” It is saying, “only models that meet the text-prime quality bar are allowed to compete for this request.”
The market is cheap only after the quality filter has already been applied.
Suppliers are continuously checked against benchmark thresholds for their tier. If a model starts drifting below the required level, it gets removed from the eligible pool. Drift can happen for boring reasons too. A provider might change serving settings, switch hardware, use a more compressed version of a model, hit latency issues, or quietly change how the model is hosted. From the outside, the model name may look the same, but the behavior can change.
That is why the audit layer matters.
Without it, a marketplace could turn into a race to the bottom. Providers would compete by cutting price, and users would slowly absorb worse answers without knowing exactly where the quality drop came from.
With the audit layer, the competition happens only inside a protected quality band.
So the user is not choosing between “cheap” and “good.”
They are choosing the level of quality they need first, then letting the market find the cheapest supplier that still clears that level.

🧵 3. The 3 text tiers and the 3 pricing - Standard is for high-volume work where cost matters most, like classification, batch summarization, tagging, and simple extraction. - Prime is the everyday production tier. This is where I’d put agents, RAG, drafting, support workflows, and quality-sensitive pipelines. - Max is for the harder stuff, like long-context work, high-stakes reasoning, and tasks where a wrong answer can create real downstream cost. The important part is that “cheapest” does not mean “random cheap model.” Each tier has a quality threshold. The Grid checks models against benchmark floors anchored to Artificial Analysis. If a supplier falls below the required quality level for a tier, it gets removed from the eligible set. So the market competes on price, but only inside the quality bar you picked.
🧵 5. The limit order book of choosing a model in Grid
Imagine 3 suppliers can serve text-prime.
Supplier A offers it at $0.90 per 1 million tokens. Supplier B offers it at $0.75. Supplier C offers it at $0.60.
The Grid first checks who actually qualifies for text-prime. If all 3 qualify, Supplier C wins because it is cheapest. But if Supplier C falls below the quality bar, it gets ignored, and Supplier B wins.

🧵 4. Quality thresholds are anchored to Artificial Analysis benchmarks (Intelligence Index for Text, Coding Index for Code, Agentic Index for Agent). Suppliers that drift below the threshold for their tier are removed automatically. "Cheapest qualifying offer" is a guarantee, not marketing. One concern people will naturally have is: “If the system always picks the cheapest qualifying model, won’t quality slowly get worse?” That would be true if The Grid were just picking the cheapest model blindly. But that is not how it works. Each tier has a quality floor. So when you send a request to something like text-prime, The Grid is not saying, “send this to any cheap model.” It is saying, “only models that meet the text-prime quality bar are allowed to compete for this request.” The market is cheap only after the quality filter has already been applied. Suppliers are continuously checked against benchmark thresholds for their tier. If a model starts drifting below the required level, it gets removed from the eligible pool. Drift can happen for boring reasons too. A provider might change serving settings, switch hardware, use a more compressed version of a model, hit latency issues, or quietly change how the model is hosted. From the outside, the model name may look the same, but the behavior can change. That is why the audit layer matters. Without it, a marketplace could turn into a race to the bottom. Providers would compete by cutting price, and users would slowly absorb worse answers without knowing exactly where the quality drop came from. With the audit layer, the competition happens only inside a protected quality band. So the user is not choosing between “cheap” and “good.” They are choosing the level of quality they need first, then letting the market find the cheapest supplier that still clears that level.
🧵 6. the price is not a fixed vendor rate card. It moves based on market supply and demand.

🧵 5. The limit order book of choosing a model in Grid Imagine 3 suppliers can serve text-prime. Supplier A offers it at $0.90 per 1 million tokens. Supplier B offers it at $0.75. Supplier C offers it at $0.60. The Grid first checks who actually qualifies for text-prime. If all 3 qualify, Supplier C wins because it is cheapest. But if Supplier C falls below the quality bar, it gets ignored, and Supplier B wins.
🧵 7. Per-provider (the company or inference service that actually runs the model on its servers) qualification
The Grid checks specific provider’s version of this model good enough, fast enough, stable enough, and reliable enough to serve this tier?
Qualification is not only about the model name. It is about the supplier’s actual delivery. The same model can behave differently depending on who hosts it, how they serve it, and whether their system is stable. So suppliers have to keep meeting the spec
🧵 6. the price is not a fixed vendor rate card. It moves based on market supply and demand.
🧵 8. Their documentation is really exhaustive

🧵 7. Per-provider (the company or inference service that actually runs the model on its servers) qualification The Grid checks specific provider’s version of this model good enough, fast enough, stable enough, and reliable enough to serve this tier? Qualification is not only about the model name. It is about the supplier’s actual delivery. The same model can behave differently depending on who hosts it, how they serve it, and whether their system is stable. So suppliers have to keep meeting the spec
🧵 9. Here’s a quick OpenClaw setup walkthrough with Grid AI

🧵 8. Their documentation is really exhaustive https://thegrid.ai/docs/start-here/quickstart
Try Grid AI here:
Sign up - http://app.thegrid.ai/consumption
Live pricing - http://thegrid.ai/pricing
Docs - http://thegrid.ai/docs
🧵 9. Here’s a quick OpenClaw setup walkthrough with Grid AI