ArXiv Paper Details Memory-Efficient LLM Inference Advances In Wllama
——0——
QUOTE POST #781Georgi Gerganov@GGERGANOV
#781Georgi Gerganov@GGERGANOV
Highlighting the new WebGPU backend in llama.cpp/ggml
The work to bring full-fledged WebGPU support in llama.cpp started about an year and a half ago. It has been lead by @reeselevine and team at USCS.
For more information, checkout the interactive blog and paper in the quoted post. Here are 2 excerpts from the paper, summarizing the implemented software architecture.
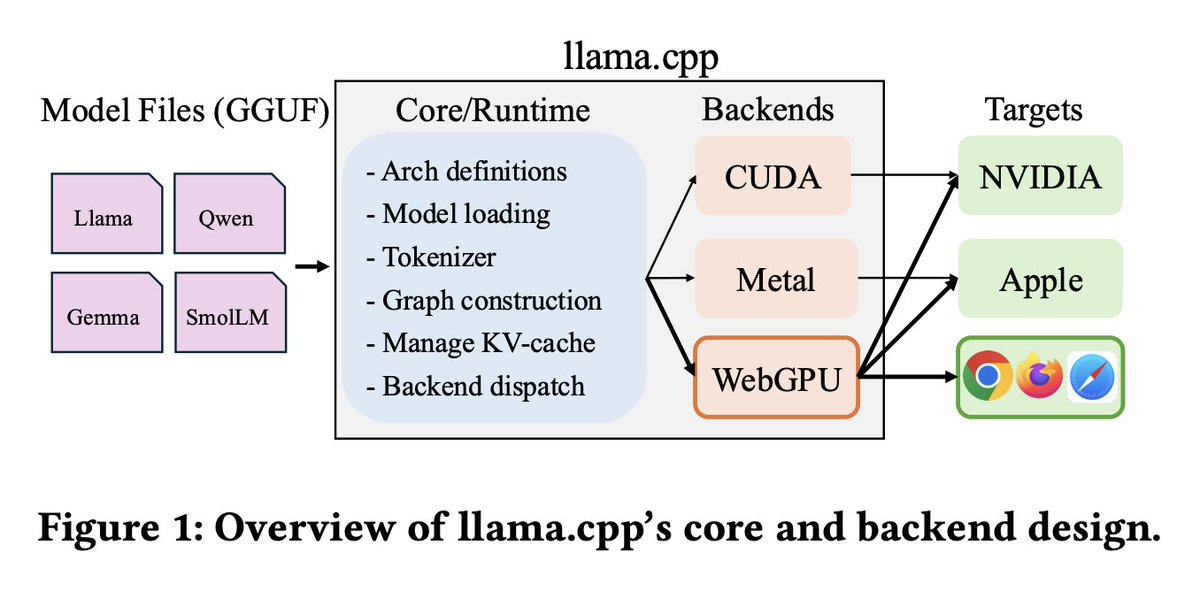

3:42 AM · May 22, 2026 · 7.6K Views