Researchers introduce ProgramBench benchmark for binary-to-repository reconstruction
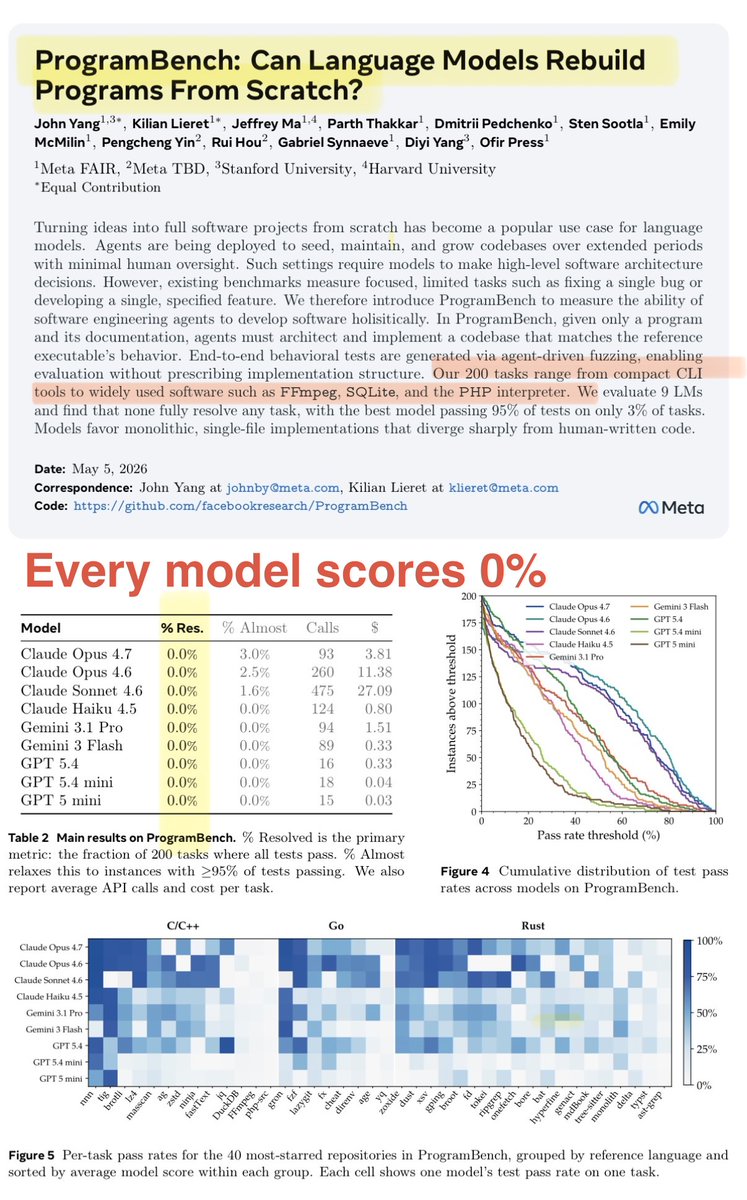
Researchers behind SWE-Bench launched ProgramBench, a benchmark with 200 tasks challenging large language models to generate complete software repositories from executable binaries alone. In a cleanroom with no starter code, documentation, or internet, models target real-world projects like FFmpeg, SQLite, ripgrep, and PHP compilers. All evaluated LLMs, including frontier models, scored 0%.
Great new benchmark for LLM memoization 🤣
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
Some things never change: Gary just doesn't fit in distribution.
Some things never change. If you don’t understand this one, you don’t understand what’s happening AI. Marcus, 1998: neural nets have trouble generalizing far beyond the data. Marcus, 2001, 2012, 2019, 2022, etc: neural nets have trouble generalizing far beyond the data. Apple, 2025: neural nets have trouble generalizing far beyond the data. Meta/Stanford/Harvard, 2026: neural nets have trouble generalizing far beyond the data.
1) Our team at Meta has a tough new coding benchmark challenging models to code entire programs including ffmpeg and the PHP compiler from scratch. 2) Top accuracy is 0% 3) We will be making the benchmark harder.
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
@ChrSzegedy We have a mode in there that requires the agent to implement the program in a *different* lang than it was in originally. And we can easily develop a private version of this for closed-source programs to weed out any memorization issues.
Great new benchmark for LLM memoization 🤣
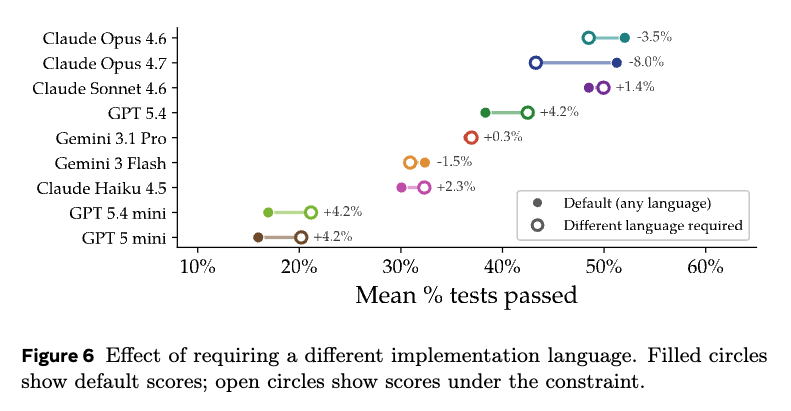
Apparently everyone is post-training with a lot of Python- we show in the paper that models substantially prefer reimplementing programs in Python, even though Python is the actual src lang in 0 of our tasks.

How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
@yoavgo ya def something we've thought of. timing tests are super hard to do well though, it took a lot of effort in SWE-fficiency and the infra here is much more complex.
@OfirPress add wall-clock runtime checks to the tests ;)
@yoavgo
Coding models are already much faster and I'm pretty sure more capable than most humans. Benchmarks have to pave the way towards the next frontier- if we stuck to human level benchmarks we would not further improve. So now we're entering the stage of super-human benchmarking.
Looking at average pass rate is *very* misleading- every task has a big chunk of tests that are very easy to pass and sometimes a minority of tests that are much harder to pass- so you can implement 10% of the program and get a 60% pass rate.
@teortaxesTex no matter what metric you pick there's gonna be some amount of information loss. but I think going with "50% pass" here would be much much more misleading. the end result here is that the agents didn't manage to fully replicate any binaries...
@OfirPress "0% resolved" is still more misleading
@teortaxesTex that's just for our main metric. we have a lot of analysis in the paper, including this plot, showing the partial solve rates. it's clear that agents are on the cusp of being able to do well on this task, and that the current trajectory is pretty positive.
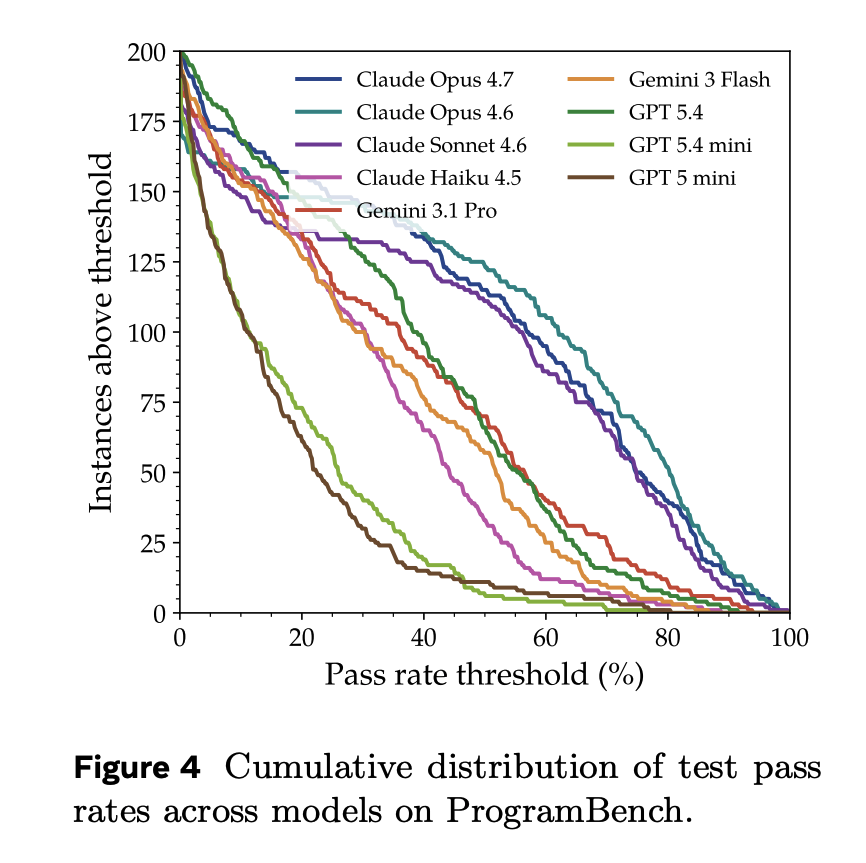
@OfirPress The interesting metric for me is how they move closer to completion. If you regard those tests as stripes on a non-sequential download progress bar, then it becomes pretty obvious which way the wind blows.
Yes. We've also tried really hard to manually / agentically go through the test sets to find "impossible tests" and couldn't find any. In the future we can remove any that are found too.
In addition, we have the 'almost solved' metric so even if a few tests are bad we can still hillclimb on that metric.
hmm i guess that what makes the task not impossible is that the test-suite itself is not adversarial, but based on fuzzing, so it is closer to the probabilistic setting. the agent can implement its own fuzzer and try to pass its generated tests
@OfirPress are the harder tests hard to pass, or hard to discover?
Looking at average pass rate is *very* misleading- every task has a big chunk of tests that are very easy to pass and sometimes a minority of tests that are much harder to pass- so you can implement 10% of the program and get a 60% pass rate.
@OfirPress add wall-clock runtime checks to the tests ;)
Apparently everyone is post-training with a lot of Python- we show in the paper that models substantially prefer reimplementing programs in Python, even though Python is the actual src lang in 0 of our tasks.
programbench is a super-hard task that no human can reliably succeed in. i would argue that even those who wrote the original code are likely to fail at this task as defined (reproduce code that is compatible with a given reference binary, given the binary and its docs).
i would argue that the task is beyond very hard, it is actually impossible, for the same reason concept learning from only positive examples and queries is impossible.
programbench is a super-hard task that no human can reliably succeed in. i would argue that even those who wrote the original code are likely to fail at this task as defined (reproduce code that is compatible with a given reference binary, given the binary and its docs).
hmm i guess that what makes the task not impossible is that the test-suite itself is not adversarial, but based on fuzzing, so it is closer to the probabilistic setting. the agent can implement its own fuzzer and try to pass its generated tests
hmm i guess that what makes the task not impossible is that the test-suite itself is not adversarial, but based on fuzzing, so it is closer to the probabilistic setting. the agent can implement its own fuzzer and try to pass its generated tests
programbench is a super-hard task that no human can reliably succeed in. i would argue that even those who wrote the original code are likely to fail at this task as defined (reproduce code that is compatible with a given reference binary, given the binary and its docs).
@OfirPress I agree, but in that case, why use the APR to create a rank list? The ranking, by itself, implies APR is the primary metric.
Looking at average pass rate is *very* misleading- every task has a big chunk of tests that are very easy to pass and sometimes a minority of tests that are much harder to pass- so you can implement 10% of the program and get a 60% pass rate.
@deedydas called it. in 1998:
Some things never change. If you don’t understand this one, you don’t understand what’s happening AI. Marcus, 1998: neural nets have trouble generalizing far beyond the data. Marcus, 2001, 2012, 2019, 2022, etc: neural nets have trouble generalizing far beyond the data. Apple, 2025: neural nets have trouble generalizing far beyond the data. Meta/Stanford/Harvard, 2026: neural nets have trouble generalizing far beyond the data.
@deedydas Seen this so move so much I made a name for it: the AI bait and switch:
The last sentence in this abstract is really important, in a way that professional programmers will immediately recognize: the models favored big single files rather than breaking things into modules.
That means that the code these systems write is going to be really hard to maintain.
AI code might get written quickly, but especially in new, complex projects, fixing it will be hell.
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
The last sentence in this abstract is really important: models favorable big single files rather than breaking things into modules.
Any good programmer will immediately appreciate that the code these systems write is going to be really hard to maintain.
AI code might get written quickly, but especially in new, complex projects, fixing it will be hell.
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
Some things never change. If you don’t understand this one, you don’t understand what’s happening AI.
Marcus, 1998: neural nets have trouble generalizing far beyond the data.
Marcus, 2001, 2012, 2019, 2022, etc: neural nets have trouble generalizing far beyond the data.
Apple, 2025: neural nets have trouble generalizing far beyond the data.
Meta/Stanford/Harvard, 2026: neural nets have trouble generalizing far beyond the data.
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
@ChrSzegedy honestly this cheap shot is beneath you, Christian
and the truth is that many many people have moved to my side re the critical importance of distribution shift
Some things never change: Gary just doesn't fit in distribution.
Very cool work. Asking agents to build big coding projects from scratch is a great way to create long-horizon tasks.
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
"Coding is [0%] solved".
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵

The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on.
ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet?
We are far from saturated on model quality.
Source: https://programbench.com/
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on. ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet? We are far from saturated on model quality.
A lot of critique around "how is memorizing ffmpeg software engineering?".
Well, every benchmark can be overfit to and memorized. You can memorize all the bugs in SWE-Bench too. ARC AGI might solve this by having a hidden set of games you can't look at. Getting 100% on ProgramBench does not mean we've achieved AGI.
However, in practice, most good models will regress in other obvious ways if they try to brute force memorize these programs. In practice, this is not how frontier models are built. We can also trivially test for memorization by comparing it to the source implementation.
The bet here is: a bottoms-up implementation of a real-world tool is a very long horizon high utility task. If models can reason through building them, it probably generalizes to many more such tasks.
Source: https://programbench.com/
The other critique which is more baffling to me is "well, humans can't do this."
So? Humans can't do a lot of things LLMs today can do today. The goal of benchmarks is to hillclimb on intelligence far above the average human.
A lot of critique around "how is memorizing ffmpeg software engineering?". Well, every benchmark can be overfit to and memorized. You can memorize all the bugs in SWE-Bench too. ARC AGI might solve this by having a hidden set of games you can't look at. Getting 100% on ProgramBench does not mean we've achieved AGI. However, in practice, most good models will regress in other obvious ways if they try to brute force memorize these programs. In practice, this is not how frontier models are built. We can also trivially test for memorization by comparing it to the source implementation. The bet here is: a bottoms-up implementation of a real-world tool is a very long horizon high utility task. If models can reason through building them, it probably generalizes to many more such tasks.
Addressing other criticism. To be clear I'm not defending them.
1. They didn't test harnesses like CC / codex: well, they could just do that 2. Don't like that they measured only completion rates, not progress (@scaling01): yeah, but you could just measure and rank by that 3. Not using internet is not a good constraint: it prevents some blatant cheating, but I agree it can lead to hillclimbing on the wrong thing. You can always just measure performance with internet access too! 4. Why not use novel problems not solved problems: painful and laborious to come up with, hard to write great exhaustive tests for without knowing what a solution looks like, hard to ascertain that it actually is a real world task and not some made up fiction
The other critique which is more baffling to me is "well, humans can't do this." So? Humans can't do a lot of things LLMs today can do today. The goal of benchmarks is to hillclimb on intelligence far above the average human.
@GaryMarcus I think this hides too much nuance. Claim 1: neural nets (or anything) has problem generalizing beyond data (actually distribution) under various settings. Claim 2: in a specific case, a specific neural network (or whatever) does not work well. Claim 2 is not implied by Claim 1.
Some things never change. If you don’t understand this one, you don’t understand what’s happening AI. Marcus, 1998: neural nets have trouble generalizing far beyond the data. Marcus, 2001, 2012, 2019, 2022, etc: neural nets have trouble generalizing far beyond the data. Apple, 2025: neural nets have trouble generalizing far beyond the data. Meta/Stanford/Harvard, 2026: neural nets have trouble generalizing far beyond the data.
@davidad oh wow this is a great benchmark I can’t believe I haven’t seen someone propose it before
Yes, “write all of ffmpeg make no mistakes” is the correct benchmark hill to be climbing in 2026, much more so than SWE-bench. Good work. Looking forward to seeing where GPT-5.5 places on here, and beyond.
@davidad though it has a pretty big memorization problem, not that swe-bench doesn’t. maybe it should be “recreate X in rust, and as performant as possible”, testable in the same way the original program was and not easily memorizable (cc @jarredsumner)
@davidad oh wow this is a great benchmark I can’t believe I haven’t seen someone propose it before
@OfirPress "0% resolved" is still more misleading
Looking at average pass rate is *very* misleading- every task has a big chunk of tests that are very easy to pass and sometimes a minority of tests that are much harder to pass- so you can implement 10% of the program and get a 60% pass rate.
@OfirPress The interesting metric for me is how they move closer to completion. If you regard those tests as stripes on a non-sequential download progress bar, then it becomes pretty obvious which way the wind blows.
@teortaxesTex no matter what metric you pick there's gonna be some amount of information loss. but I think going with "50% pass" here would be much much more misleading. the end result here is that the agents didn't manage to fully replicate any binaries...
@OfirPress Would be interesting if you added some smaller simpler binaries to see where exactly do they reach nontrivial reproduction already
@teortaxesTex that's just for our main metric. we have a lot of analysis in the paper, including this plot, showing the partial solve rates. it's clear that agents are on the cusp of being able to do well on this task, and that the current trajectory is pretty positive.
Yes, “write all of ffmpeg make no mistakes” is the correct benchmark hill to be climbing in 2026, much more so than SWE-bench. Good work. Looking forward to seeing where GPT-5.5 places on here, and beyond.
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
ProgramBench is very hard, but it’s solvable by design.
While the official best score is 0%, our extended results reveal varying levels of meaningful progress across tasks. We added a lot of interactive plots & tables to our website.
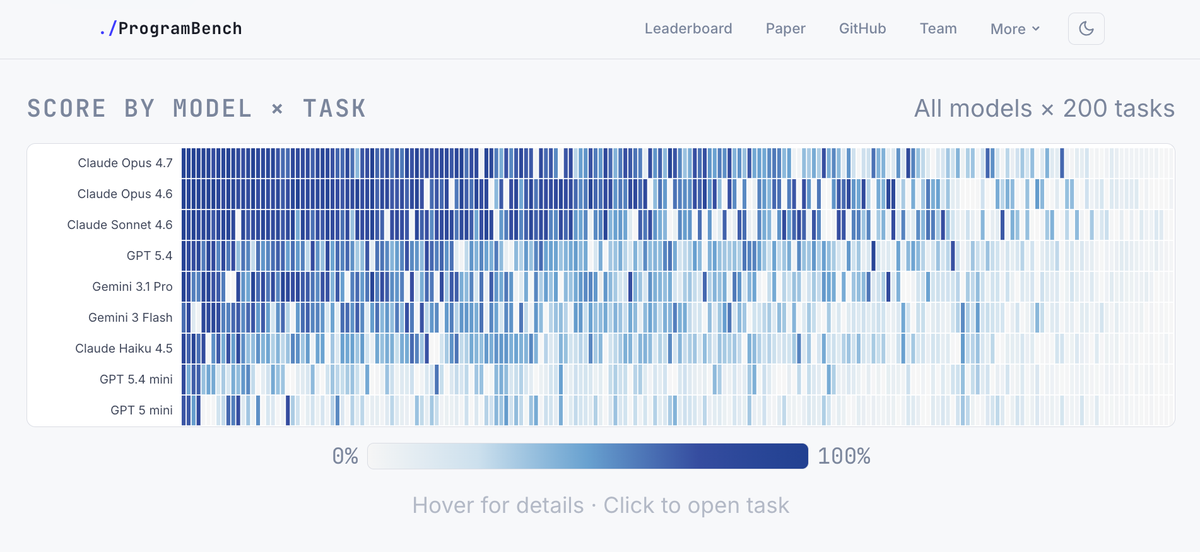
Check out our paper for a bunch of analyses
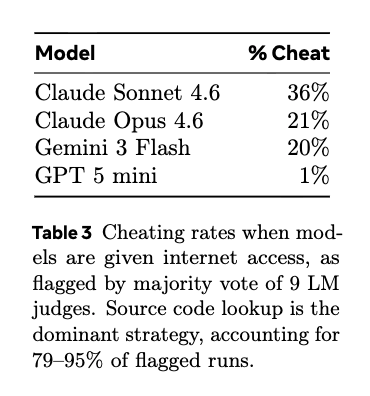
- Models write Python solutions even though originals are in C++/Rust/Go - 98% of runs, models submit before hitting time/turn limits - Given internet access, models Googled solutions 36% of the time, even when told not to

ProgramBench is very hard, but it’s solvable by design. While the official best score is 0%, our extended results reveal varying levels of meaningful progress across tasks. We added a lot of interactive plots & tables to our website.
ProgramBench is a joint effort across Meta FAIR, Meta TBD, Stanford, Harvard
@KLieret (co-first author) @18jeffreyma @parth007_96 @dpedch @sten_sootla @micmylin @pengchengyin @magpie_rayhou @syhw @Diyi_Yang @OfirPress
Paper: https://programbench.com/static/paper.pdf

this is actually hilarious
ProgramBench website reports 0% scores for all models
but in the background rank the model by the more useful but hidden metric of average % of tests passed